You might also like
- A Comparative Between Hadoop MapReduce and ApacheDocument4 pagesA Comparative Between Hadoop MapReduce and Apachesalah AlswiayNo ratings yet
- Compusoft, 3 (10), 1136-1139 PDFDocument4 pagesCompusoft, 3 (10), 1136-1139 PDFIjact EditorNo ratings yet
- An Optimized Algorithm For Reduce Task Scheduling: Xiaotong Zhang, Bin Hu, Jiafu JiangDocument8 pagesAn Optimized Algorithm For Reduce Task Scheduling: Xiaotong Zhang, Bin Hu, Jiafu Jiangbony009No ratings yet
- (IJCT-V3I4P1) Authors:Anusha Itnal, Sujata UmaraniDocument5 pages(IJCT-V3I4P1) Authors:Anusha Itnal, Sujata UmaraniIjctJournalsNo ratings yet
- 2inceptez Hadoop ProcessingDocument16 pages2inceptez Hadoop ProcessingMani VijayNo ratings yet
- Engineering Journal::An Efficient Mapreduce Scheduling Algorithm in HadoopDocument7 pagesEngineering Journal::An Efficient Mapreduce Scheduling Algorithm in HadoopEngineering JournalNo ratings yet
- UNIT 4 Notes by ARUN JHAPATEDocument20 pagesUNIT 4 Notes by ARUN JHAPATEAnkit “अंकित मौर्य” MouryaNo ratings yet
- Hadoop Architecture: Er. Gursewak Singh DcseDocument12 pagesHadoop Architecture: Er. Gursewak Singh DcseDaisy KawatraNo ratings yet
- Unit 5Document20 pagesUnit 5manasaNo ratings yet
- Top Answers To Map Reduce Interview Questions: Criteria Mapreduce SparkDocument2 pagesTop Answers To Map Reduce Interview Questions: Criteria Mapreduce SparkSumit KNo ratings yet
- YARN Resource Negotiator OverviewDocument44 pagesYARN Resource Negotiator OverviewManjula AnnamalaiNo ratings yet
- Ditp - ch2 4Document2 pagesDitp - ch2 4jefferyleclercNo ratings yet
- Matchmaking: A New Mapreduce Scheduling Technique: Digitalcommons@University of Nebraska - LincolnDocument9 pagesMatchmaking: A New Mapreduce Scheduling Technique: Digitalcommons@University of Nebraska - LincolnNetra JjoshiNo ratings yet
- Workload Characteristic Oriented Scheduler For MapReduceDocument8 pagesWorkload Characteristic Oriented Scheduler For MapReduceBradu VNo ratings yet
- Hadoop MapReduce Interview QuestionsDocument7 pagesHadoop MapReduce Interview QuestionsZachariah BentleyNo ratings yet
- Hadoop JobTracker: What it is and its role in a clusterDocument8 pagesHadoop JobTracker: What it is and its role in a clusterArunkumar PalathumpattuNo ratings yet
- Big Data/ Hadoop: Interview QuestionsDocument17 pagesBig Data/ Hadoop: Interview Questionssatish.sathya.a2012No ratings yet
- Distributed Mapreduce Engine With Fault Tolerance: June 2014Document6 pagesDistributed Mapreduce Engine With Fault Tolerance: June 2014MANAANo ratings yet
- 1 Purpose: Single Node Setup Cluster SetupDocument1 page1 Purpose: Single Node Setup Cluster Setupp001No ratings yet
- Hadoop 2.0Document20 pagesHadoop 2.0krishan GoyalNo ratings yet
- Hadoop Interview Quations: HDFS (Hadoop Distributed File System)Document23 pagesHadoop Interview Quations: HDFS (Hadoop Distributed File System)Stanfield D. JhonnyNo ratings yet
- YARN (Yet Another Resource Negotiator) : Apache Hadoop in A NutshellDocument2 pagesYARN (Yet Another Resource Negotiator) : Apache Hadoop in A NutshelldudearoraNo ratings yet
- Parallel Real-Time Scheduling of DagsDocument16 pagesParallel Real-Time Scheduling of DagsMayra EstradaNo ratings yet
- Hadoop 1.x Architecture and LimitationsDocument4 pagesHadoop 1.x Architecture and LimitationsSiddhant SinghNo ratings yet
- Multi ThreadingDocument128 pagesMulti ThreadingbabithNo ratings yet
- Hadoop Introduction PDFDocument3 pagesHadoop Introduction PDFTahseef RezaNo ratings yet
- System Design and Implementation 5.1 System DesignDocument14 pagesSystem Design and Implementation 5.1 System DesignsararajeeNo ratings yet
- Unit 3 BbaDocument11 pagesUnit 3 Bbarajendrameena172003No ratings yet
- Hadoop Admin Interview QuestionsDocument9 pagesHadoop Admin Interview Questionssriny123No ratings yet
- Assn - No:1 Cloud Computing Assignment 13.10.2019Document4 pagesAssn - No:1 Cloud Computing Assignment 13.10.2019Hari HaranNo ratings yet
- Performance Analysis of Hadoop Map Reduce OnDocument4 pagesPerformance Analysis of Hadoop Map Reduce OnArabic TigerNo ratings yet
- Beyond Load Balancing: Package-Aware Scheduling For Serverless PlatformsDocument10 pagesBeyond Load Balancing: Package-Aware Scheduling For Serverless PlatformsjannatNo ratings yet
- Hadoop: Er. Gursewak Singh DsceDocument15 pagesHadoop: Er. Gursewak Singh DsceDaisy KawatraNo ratings yet
- MapReduce OnlineDocument15 pagesMapReduce OnlineVyhxNo ratings yet
- Apache Yarn interview questions and answersDocument4 pagesApache Yarn interview questions and answersmazda rx7No ratings yet
- Lovely Professional University (Lpu) : Mittal School of Business (Msob)Document10 pagesLovely Professional University (Lpu) : Mittal School of Business (Msob)FareedNo ratings yet
- Getting Started With HadoopDocument47 pagesGetting Started With HadoopTeeMan27No ratings yet
- Hadoop Overview: Open Source Framework Processing Large Amounts of Heterogeneous Data Sets Distributed FashionDocument62 pagesHadoop Overview: Open Source Framework Processing Large Amounts of Heterogeneous Data Sets Distributed FashionMousoomi BaruahNo ratings yet
- Java Concurrency Tutorial BenefitsDocument108 pagesJava Concurrency Tutorial Benefitswilder delgadoNo ratings yet
- Unit 2Document30 pagesUnit 2Awadhesh MauryaNo ratings yet
- Big Data Hadoop QuestionsDocument7 pagesBig Data Hadoop QuestionsBala GiridharNo ratings yet
- Hadoop V 2.x Vs V 3.xDocument20 pagesHadoop V 2.x Vs V 3.xAtharv ChaudhariNo ratings yet
- Moving_Hadoop_into_the_Cloud_with_Flexible_Slot_Management_and_Speculative_ExecutionDocument15 pagesMoving_Hadoop_into_the_Cloud_with_Flexible_Slot_Management_and_Speculative_Executionarthur seokwon choiNo ratings yet
- 7 Full Hadoop Performance Modeling For Job Estimation and Resource ProvisioningDocument94 pages7 Full Hadoop Performance Modeling For Job Estimation and Resource ProvisioningarunkumarNo ratings yet
- Scheduling algorithms in Hadoop: A review of FIFO, capacity, and fair schedulersDocument6 pagesScheduling algorithms in Hadoop: A review of FIFO, capacity, and fair schedulersThet Su AungNo ratings yet
- Cloudflow - A Framework For Mapreduce Pipeline Development in Biomedical ResearchDocument6 pagesCloudflow - A Framework For Mapreduce Pipeline Development in Biomedical ResearchRobert Carneiro AssisNo ratings yet
- Shangjiang Cluster13Document8 pagesShangjiang Cluster13Ali RazaNo ratings yet
- 1063-Article Text-1696-1-10-20191020Document7 pages1063-Article Text-1696-1-10-20191020Jai SharmaNo ratings yet
- Hadoop Components and Concepts ExplainedDocument5 pagesHadoop Components and Concepts ExplainedAnuj Harshwardhan SharmaNo ratings yet
- Remote Debugging of Hadoop Job With Eclipse - Pravinchavan's BlogDocument4 pagesRemote Debugging of Hadoop Job With Eclipse - Pravinchavan's BlogaepuriNo ratings yet
- Intro Hadoop Ecosystem Components, Hadoop Ecosystem ToolsDocument15 pagesIntro Hadoop Ecosystem Components, Hadoop Ecosystem ToolsRebecca thoNo ratings yet
- Fork Join Framework-Brian GoetzDocument9 pagesFork Join Framework-Brian GoetzAmol ChikhalkarNo ratings yet
- Unit 5 - Big Data Ecosystem - 06.05.18Document21 pagesUnit 5 - Big Data Ecosystem - 06.05.18Asmita GolawtiyaNo ratings yet
- IntroductionDocument2 pagesIntroductionRahul GargNo ratings yet
- Hadoop: A Seminar Report OnDocument28 pagesHadoop: A Seminar Report OnRoshni KhairnarNo ratings yet
- Chapter 10Document45 pagesChapter 10Sarita SamalNo ratings yet
- HadoopDocument14 pagesHadoopChaturvedi TanyaNo ratings yet
- JAVA: Java Programming for beginners teaching you basic to advanced JAVA programming skills!From EverandJAVA: Java Programming for beginners teaching you basic to advanced JAVA programming skills!No ratings yet
- DownloadDocument5 pagesDownloadDinesh SanodiyaNo ratings yet
- Declaration: Details of Investment (FINANCIAL YEAR 2017-2018)Document1 pageDeclaration: Details of Investment (FINANCIAL YEAR 2017-2018)Dinesh SanodiyaNo ratings yet
- Unix Interview Questions Basic Theory QuDocument23 pagesUnix Interview Questions Basic Theory QuDinesh SanodiyaNo ratings yet
- IBM InfoSphere DataStage DemoDocument21 pagesIBM InfoSphere DataStage DemoChintan ParekhNo ratings yet
- Datastage Debugging TipsDocument2 pagesDatastage Debugging TipsDinesh SanodiyaNo ratings yet
- Ds Material PDFDocument243 pagesDs Material PDFDinesh SanodiyaNo ratings yet
- All Datastage Parallel StagesDocument153 pagesAll Datastage Parallel StagesDinesh SanodiyaNo ratings yet
- CLSS MIG Guidelines$2017Mar23142444Document24 pagesCLSS MIG Guidelines$2017Mar23142444Praveen KumarNo ratings yet
- Dataset and UnixDocument14 pagesDataset and UnixDinesh SanodiyaNo ratings yet
- What Is Difference Between Server Jobs and Parallel Jobs? Ans:-Server JobsDocument71 pagesWhat Is Difference Between Server Jobs and Parallel Jobs? Ans:-Server JobsDinesh SanodiyaNo ratings yet
- Riyaz K Patan Global Business Services: EducationDocument2 pagesRiyaz K Patan Global Business Services: EducationDinesh SanodiyaNo ratings yet
- EPF Name Change FormDocument1 pageEPF Name Change FormqabiswajitNo ratings yet
- Imp Datastage NewDocument158 pagesImp Datastage NewDinesh Sanodiya100% (1)
- Datastage Scribble Sheet: VariousDocument20 pagesDatastage Scribble Sheet: VariousKurt AndersenNo ratings yet
- Datastage UnixcommondsDocument9 pagesDatastage Unixcommondsbrightfulindia3No ratings yet
- Dataset& Unix, OracleDocument14 pagesDataset& Unix, OracleDinesh SanodiyaNo ratings yet
- Ds Material PDFDocument243 pagesDs Material PDFDinesh SanodiyaNo ratings yet
- Flat Requirments DetailsDocument2 pagesFlat Requirments DetailsDinesh SanodiyaNo ratings yet
- Data Stage Slowly Changing PDFDocument32 pagesData Stage Slowly Changing PDFShan SriNo ratings yet
- 00 HadoopWelcome TranscriptDocument4 pages00 HadoopWelcome TranscriptramanavgNo ratings yet
- TestDocument3 pagesTestDinesh SanodiyaNo ratings yet
- TestDocument3 pagesTestDinesh SanodiyaNo ratings yet
- Records Not Present in Staging EnvironmentDocument8 pagesRecords Not Present in Staging EnvironmentDinesh SanodiyaNo ratings yet
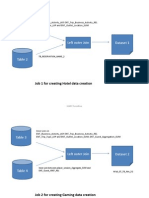
- Table 1: Job 1 For Creating Hotel Data CreationDocument11 pagesTable 1: Job 1 For Creating Hotel Data CreationDinesh SanodiyaNo ratings yet