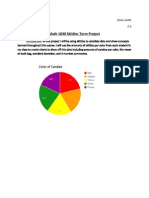
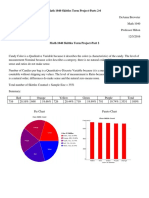
You might also like
- The Skittles Project FinalDocument8 pagesThe Skittles Project Finalapi-316760667No ratings yet
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085No ratings yet
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849No ratings yet
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765No ratings yet
- Skittles ProDocument9 pagesSkittles Proapi-241124972No ratings yet
- Skittles Term Project - Kai Galbiso Stat1040Document6 pagesSkittles Term Project - Kai Galbiso Stat1040api-316758771No ratings yet
- Reflection and EportfolioDocument8 pagesReflection and Eportfolioapi-252747849No ratings yet
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218No ratings yet
- Skittles Project Group Final WordDocument6 pagesSkittles Project Group Final Wordapi-316239273No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849No ratings yet
- Skittles Project With ReflectionDocument7 pagesSkittles Project With Reflectionapi-234712126100% (1)
- Skittles ProjectDocument6 pagesSkittles Projectapi-319345408No ratings yet
- The Rainbow ReportDocument11 pagesThe Rainbow Reportapi-316991888No ratings yet
- Skittle Term ProjectDocument15 pagesSkittle Term Projectapi-260271892No ratings yet
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240No ratings yet
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278No ratings yet
- Final ProjectDocument9 pagesFinal Projectapi-262329757No ratings yet
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685No ratings yet
- Final ProjectDocument6 pagesFinal Projectapi-283261340No ratings yet
- Statistics Final Project Summer Semester 2016Document17 pagesStatistics Final Project Summer Semester 2016api-295161880No ratings yet
- Skittles Project 5-02Document8 pagesSkittles Project 5-02api-354040698No ratings yet
- Statistics Project 17Document13 pagesStatistics Project 17api-271978152No ratings yet
- Comprehensive Skittles Project Math 1040Document7 pagesComprehensive Skittles Project Math 1040api-316732019No ratings yet
- Math 1040Document3 pagesMath 1040api-342333328No ratings yet
- Math 1040 Skittles Term Project AynoaDocument15 pagesMath 1040 Skittles Term Project Aynoaapi-301347675No ratings yet
- Math 1040 Skittles Term ProjectDocument10 pagesMath 1040 Skittles Term Projectapi-310671451No ratings yet
- Skittles ProjectDocument4 pagesSkittles Projectapi-287735026No ratings yet
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081No ratings yet
- SkittlesDocument5 pagesSkittlesapi-249778667No ratings yet
- Skittles Term Project Math 1040Document6 pagesSkittles Term Project Math 1040api-316781222No ratings yet
- Full Skittles ProjectDocument13 pagesFull Skittles Projectapi-537189505No ratings yet
- Croot Part6 EportfolioDocument16 pagesCroot Part6 Eportfolioapi-276896975No ratings yet
- Math 1040 Term ProjectDocument7 pagesMath 1040 Term Projectapi-340188424No ratings yet
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832No ratings yet
- EportfolioDocument8 pagesEportfolioapi-242211470No ratings yet
- Stats ProjectDocument14 pagesStats Projectapi-302666758No ratings yet
- Math 1040 Skittles Term ProjectDocument8 pagesMath 1040 Skittles Term Projectapi-272870073No ratings yet
- Skittles Project Math 1040Document8 pagesSkittles Project Math 1040api-495044194No ratings yet
- Methods of Research Week 15 AssessmentDocument8 pagesMethods of Research Week 15 AssessmentJoeddy LagahitNo ratings yet
- TP 2 StatsDocument5 pagesTP 2 Statsapi-240850453No ratings yet
- Skittles Project 1Document7 pagesSkittles Project 1api-299868669100% (2)
- StatsfinalprojectDocument7 pagesStatsfinalprojectapi-325102852No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-271444168No ratings yet
- Skittles Term Project 1-6Document10 pagesSkittles Term Project 1-6api-284733808No ratings yet
- Skittles Final ProjectDocument5 pagesSkittles Final Projectapi-251571777No ratings yet
- Emily Gregorio Skittles Project FinalDocument3 pagesEmily Gregorio Skittles Project Finalapi-288933258No ratings yet
- Skittle Project FinalDocument6 pagesSkittle Project Finalapi-252859182No ratings yet
- Skittles 2 FinalDocument12 pagesSkittles 2 Finalapi-242194552No ratings yet
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396No ratings yet
- Skittles Term Project 11 9 14Document5 pagesSkittles Term Project 11 9 14api-192489685No ratings yet
- Final ProjectDocument3 pagesFinal Projectapi-265661554No ratings yet
- Stats StuffDocument7 pagesStats Stuffapi-242298926No ratings yet
- Math 1040 ProjectDocument8 pagesMath 1040 Projectapi-388517702No ratings yet
- Math 1040 Final ProjectDocument3 pagesMath 1040 Final Projectapi-285380759No ratings yet
- Statistics Term Project E-Portfolio ReflectionDocument8 pagesStatistics Term Project E-Portfolio Reflectionapi-258147701No ratings yet
- Skittles Project FinalDocument5 pagesSkittles Project Finalapi-271348941No ratings yet
- Kassem Hajj: Math 1040 Skittles Term ProjectDocument10 pagesKassem Hajj: Math 1040 Skittles Term Projectapi-240347922No ratings yet
- Eport 2Document2 pagesEport 2api-245266056No ratings yet
- Eport 1Document2 pagesEport 1api-245266056No ratings yet
- Lifelong WellnessDocument1 pageLifelong Wellnessapi-245266056No ratings yet
- Resume 2013Document2 pagesResume 2013api-245266056No ratings yet
- SHS Statistics and Probability Quarter 4 W3Document5 pagesSHS Statistics and Probability Quarter 4 W3JENETTE SABURAONo ratings yet
- May 2012 IB Psychology grade boundaries and exam reportsDocument27 pagesMay 2012 IB Psychology grade boundaries and exam reportstokteacherNo ratings yet
- Tecnicas EconometricasDocument394 pagesTecnicas EconometricasGustavo F. Huamán FernándezNo ratings yet
- Tes Kepribadian FlorenceDocument59 pagesTes Kepribadian FlorenceMarcella Mariska AryonoNo ratings yet
- Day 2 Reporting PR 2Document5 pagesDay 2 Reporting PR 2Loujean Gudes MarNo ratings yet
- Fundamentals of Data Science Laboratory ExperimentsDocument24 pagesFundamentals of Data Science Laboratory ExperimentsMohamed Shajid N100% (5)
- Quantitative Examination Second Term 20212022 CompleteDocument15 pagesQuantitative Examination Second Term 20212022 CompleteOladele FamesoNo ratings yet
- STATISTICS - Is A Set of Pertinent Activities Such As Collection, Organization, Presentation, Analysis andDocument5 pagesSTATISTICS - Is A Set of Pertinent Activities Such As Collection, Organization, Presentation, Analysis andRye SanNo ratings yet
- Wilcoxon Signed Ranks Test: Descriptive StatisticsDocument12 pagesWilcoxon Signed Ranks Test: Descriptive StatisticsOlah Data GampangNo ratings yet
- Factor Analysis: Statistical Methods and Practical Issues, Volume 14 Volume 1978Document5 pagesFactor Analysis: Statistical Methods and Practical Issues, Volume 14 Volume 1978Raja Shahid RasheedNo ratings yet
- CaENTI31 Territory ConceptDocument669 pagesCaENTI31 Territory ConceptPapp IoanNo ratings yet
- Contoh Abstrak Pada Skripsi Bahasa Inggris Dengan Judul DiaryDocument9 pagesContoh Abstrak Pada Skripsi Bahasa Inggris Dengan Judul DiaryZones Randy SimatupangNo ratings yet
- Nominal, Ordinal, Interval, Ratio Scales with ExamplesDocument9 pagesNominal, Ordinal, Interval, Ratio Scales with ExamplesMd. Tanvir HasanNo ratings yet
- Design Thoughts-Aug-10Document73 pagesDesign Thoughts-Aug-10Arun MNo ratings yet
- Decision MakingDocument5 pagesDecision MakingSandy BuronNo ratings yet
- 1S00426Document596 pages1S00426siddheshNo ratings yet
- Theoritical FrameworkDocument4 pagesTheoritical FrameworkBryan Clareza0% (1)
- Research10 q3 Mod2 InterpretationofData v3Document24 pagesResearch10 q3 Mod2 InterpretationofData v3Dalissa Rivadeniera0% (3)
- Statistics For Business and Economics (13e) : John LoucksDocument48 pagesStatistics For Business and Economics (13e) : John LoucksMary Mae Arnado100% (1)
- Doctoral Candidacy Exam Area: Research Table of SpecificationsDocument2 pagesDoctoral Candidacy Exam Area: Research Table of SpecificationsWendy PermanaNo ratings yet
- Literature Review On Scientific ManagementDocument5 pagesLiterature Review On Scientific Managementea6p1e99100% (1)
- Attribute agreement analysis reportDocument5 pagesAttribute agreement analysis reportisolongNo ratings yet
- Sample Thesis About Operations ManagementDocument6 pagesSample Thesis About Operations Managementtiffanymillerlittlerock100% (2)
- MSC in Evidence-Based Social Intervention and Policy Evaluation - 2017-18 Entry - 20oct2016Document3 pagesMSC in Evidence-Based Social Intervention and Policy Evaluation - 2017-18 Entry - 20oct2016ANo ratings yet
- Presentation of Business Research MethodologyDocument14 pagesPresentation of Business Research MethodologySUMIT KUMARNo ratings yet
- Reaction Time Conclusion PublishDocument3 pagesReaction Time Conclusion Publishapi-112722311No ratings yet
- PDF Chapter 2 Quiz 2019-20-1q Ece154p Cola Valiente CompressDocument17 pagesPDF Chapter 2 Quiz 2019-20-1q Ece154p Cola Valiente CompressMuhammad MalikNo ratings yet
- 15621-Article Text-48518-2-10-20220222Document7 pages15621-Article Text-48518-2-10-20220222Al KayyisNo ratings yet
- Thesis and Dissertation Proposal EvaluationDocument9 pagesThesis and Dissertation Proposal EvaluationHarry Lord M. BolinaNo ratings yet
- Lesson 6: Marketing Research: Let's Start!Document14 pagesLesson 6: Marketing Research: Let's Start!Jamaica BuenoNo ratings yet