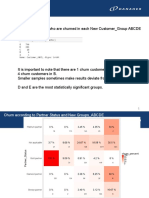
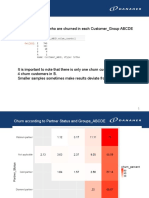
You might also like
- Introduction To Data ScienceDocument74 pagesIntroduction To Data ScienceMichael Wee75% (4)
- Data Science OverviewDocument74 pagesData Science OverviewMatheus SilvaNo ratings yet
- Role of IT in Facing COVID-19Document19 pagesRole of IT in Facing COVID-19Meilani SafitriNo ratings yet
- The Digital Dilemma 2: Perspectives From Independent Filmmakers, Documentarians and Nonprofit Audiovisual ArchivesDocument136 pagesThe Digital Dilemma 2: Perspectives From Independent Filmmakers, Documentarians and Nonprofit Audiovisual ArchivesscriNo ratings yet
- Seas Lifts Off: Engineering That Makes A DifferenceDocument4 pagesSeas Lifts Off: Engineering That Makes A DifferenceSteven RankineNo ratings yet
- Chapter 4 5 PDFDocument185 pagesChapter 4 5 PDFGleniece CoronadoNo ratings yet
- MARCH 2011: $5.95canada $6.95Document88 pagesMARCH 2011: $5.95canada $6.95jhasua23No ratings yet
- Who Gives a Gigabyte?: A Survival Guide for the Technologically PerplexedFrom EverandWho Gives a Gigabyte?: A Survival Guide for the Technologically PerplexedNo ratings yet
- Data Science: Principles and Practice: Lecture 1: IntroductionDocument36 pagesData Science: Principles and Practice: Lecture 1: IntroductionYoussef AbdalnabyNo ratings yet
- Full Download Test Bank For Essentials of Mis 13th by Laudon PDF Full ChapterDocument36 pagesFull Download Test Bank For Essentials of Mis 13th by Laudon PDF Full Chapterunhealth.foist8qrnn2100% (17)
- Data Intensive Computing Architectures Algorithms and ApplicationsDocument300 pagesData Intensive Computing Architectures Algorithms and ApplicationsMarius Cristian CapatinaNo ratings yet
- Ielts Reading Test 44Document6 pagesIelts Reading Test 44Nur IndahNo ratings yet
- The TVs of Tomorrow: How RCA’s Flat-Screen Dreams Led to the First LCDsFrom EverandThe TVs of Tomorrow: How RCA’s Flat-Screen Dreams Led to the First LCDsRating: 5 out of 5 stars5/5 (2)
- All Together Now A Perspective On The Netflix PrizeDocument7 pagesAll Together Now A Perspective On The Netflix Prizesneha smNo ratings yet
- Ielts Reading Test 44Document6 pagesIelts Reading Test 44Nepal WorldNo ratings yet
- Data Analytics for Business Decision MakingDocument15 pagesData Analytics for Business Decision MakingCarlos Andre Payares LunaNo ratings yet
- Introduction to Connected Strategy: Disruption, Innovation & StrategyDocument91 pagesIntroduction to Connected Strategy: Disruption, Innovation & StrategydzugeekNo ratings yet
- Review of Key Networking ConceptsDocument37 pagesReview of Key Networking ConceptsVino SankarNo ratings yet
- Cambridge Book 1 Test 4Document8 pagesCambridge Book 1 Test 4shalumaven6699No ratings yet
- Managing Uncertainty 2011 07Document28 pagesManaging Uncertainty 2011 07Tamas_Toth_5477No ratings yet
- Blog Pay No Attention To That Man Behind The CurtainDocument3 pagesBlog Pay No Attention To That Man Behind The CurtainWeb MasterNo ratings yet
- Want To Become A BillionaireDocument4 pagesWant To Become A Billionairedeepak0061No ratings yet
- American Institute For Manufacturing Integrated Photonics: Implications For The Future - John BowersDocument55 pagesAmerican Institute For Manufacturing Integrated Photonics: Implications For The Future - John BowersUCSBieeNo ratings yet
- Daniel Mellinger ThesisDocument5 pagesDaniel Mellinger Thesisvxjgqeikd100% (2)
- The 42 V's of Big Data and Data Science PDFDocument6 pagesThe 42 V's of Big Data and Data Science PDF5oscilantesNo ratings yet
- INF442 Algorithms Data Analysis CDocument40 pagesINF442 Algorithms Data Analysis CKADDAMI SaousanNo ratings yet
- Crowdsourcing IdeagorasDocument37 pagesCrowdsourcing IdeagorasMandyNo ratings yet
- Test Bank For Information Systems Today 8th Edition Joseph ValacichDocument36 pagesTest Bank For Information Systems Today 8th Edition Joseph Valacichbluelymooneyed45rqx100% (40)
- Frey, Franziska - Digital Imaging For Photographic CollectionsDocument52 pagesFrey, Franziska - Digital Imaging For Photographic CollectionsAna paivaNo ratings yet
- Big Data: How the Information Revolution Is Transforming Our LivesFrom EverandBig Data: How the Information Revolution Is Transforming Our LivesRating: 4 out of 5 stars4/5 (3)
- Silicon Valley: Past, Present, FutureDocument60 pagesSilicon Valley: Past, Present, FutureAbhishek GuddadNo ratings yet
- Data Warehousing: Lecture No 01Document33 pagesData Warehousing: Lecture No 01Anonymous I3Ath48dNo ratings yet
- Camb 1 Test 4Document6 pagesCamb 1 Test 4Sharon GunarajNo ratings yet
- NCSA Supercomputing Coloring Book Vol 2Document20 pagesNCSA Supercomputing Coloring Book Vol 2Kf LimNo ratings yet
- Working Film DirectorDocument26 pagesWorking Film DirectorsidisocialnetworkNo ratings yet
- Mirachip: Miracle Computer Chip Combats Airborne Viruses and Fosters a Cyber Virus to Debilitate ChinaFrom EverandMirachip: Miracle Computer Chip Combats Airborne Viruses and Fosters a Cyber Virus to Debilitate ChinaNo ratings yet
- Computer TechnologyDocument55 pagesComputer TechnologyArmSy ZtrueNo ratings yet
- Analytics Julyaugust 2012Document47 pagesAnalytics Julyaugust 2012Ashoka VanjareNo ratings yet
- The Oredigger, Issue 6, October 7, 2013Document12 pagesThe Oredigger, Issue 6, October 7, 2013The OrediggerNo ratings yet
- Data Mining: Session 1 An IntroductionDocument51 pagesData Mining: Session 1 An IntroductionMuhammad Umer FarooqNo ratings yet
- 11 Siliconvalleyhistoryandinnovationcopy 01032023 010624am 26102023 014302pmDocument44 pages11 Siliconvalleyhistoryandinnovationcopy 01032023 010624am 26102023 014302pmMuhammad UmairNo ratings yet
- 1 - BBDS - Why Learning Data Science Is An Absolute MustDocument59 pages1 - BBDS - Why Learning Data Science Is An Absolute MustbaikariNo ratings yet
- The Game Changers:: Wisdom From A Tech Guru, Acclaimed Actor, & Sports LegendDocument9 pagesThe Game Changers:: Wisdom From A Tech Guru, Acclaimed Actor, & Sports LegendSapientNitroNo ratings yet
- Yahoo Web Search: 1. Including Results ForDocument3 pagesYahoo Web Search: 1. Including Results ForArch. ZionNo ratings yet
- 01 IntroductionDocument71 pages01 IntroductionRahul VenkatNo ratings yet
- Connecting Behaviors To Attitudes About Safety Is Labs' Next Big ChallengeDocument11 pagesConnecting Behaviors To Attitudes About Safety Is Labs' Next Big Challengesandia_docsNo ratings yet
- Internet Futures Scenarios Explore Open vs Controlled ModelsDocument12 pagesInternet Futures Scenarios Explore Open vs Controlled ModelsMawuli AttahNo ratings yet
- Televisionaries: Inside the Chaos and Innovation of the Digital RevolutionFrom EverandTelevisionaries: Inside the Chaos and Innovation of the Digital RevolutionNo ratings yet
- Future of Computing ExploredDocument26 pagesFuture of Computing ExploredSuganya SelvarajNo ratings yet
- American Cinematographer 2010-04Document110 pagesAmerican Cinematographer 2010-04Cesar Rodriguez Flores100% (1)
- (Richard Colson) The Fundamentals of Digital OrgDocument178 pages(Richard Colson) The Fundamentals of Digital OrgAzu Ki100% (1)
- AC Noi 2010Document104 pagesAC Noi 2010Bogdanovici BarbuNo ratings yet
- Small Business Development Center University at Albany William Brigham, DirectorDocument33 pagesSmall Business Development Center University at Albany William Brigham, DirectorHantu TuNo ratings yet
- Report Regarding Cambridge Analytica LLC and SCL Elections LTDDocument36 pagesReport Regarding Cambridge Analytica LLC and SCL Elections LTDElias Alboadicto Villagrán DonaireNo ratings yet
- Lacanaria Ass3Document2 pagesLacanaria Ass3MARK ARQUE LACANARIANo ratings yet
- The Digital Consumer Technology Handbook: A Comprehensive Guide to Devices, Standards, Future Directions, and Programmable Logic SolutionsFrom EverandThe Digital Consumer Technology Handbook: A Comprehensive Guide to Devices, Standards, Future Directions, and Programmable Logic SolutionsNo ratings yet
- Final PresentationDocument54 pagesFinal Presentationapi-232796443No ratings yet
- NYIT Magazine Vol. 10Document48 pagesNYIT Magazine Vol. 10Ali HilliNo ratings yet
- Lesson 1Document48 pagesLesson 1NuwandiNo ratings yet
- Will Today's Digital Movies Exist in 100 Years?Document12 pagesWill Today's Digital Movies Exist in 100 Years?Christian RangelNo ratings yet
- Case Interview Sample QuestionsDocument2 pagesCase Interview Sample Questionssnaren77767% (3)
- Capital One PDFDocument32 pagesCapital One PDFPallav AnandNo ratings yet
- Churned A Matrix V 5Document30 pagesChurned A Matrix V 5Pallav AnandNo ratings yet
- Churned A Matrix V 3Document29 pagesChurned A Matrix V 3Pallav AnandNo ratings yet
- Artofdatascience PDFDocument162 pagesArtofdatascience PDForchid21No ratings yet
- TX DL 2016Document96 pagesTX DL 2016vreddy123No ratings yet
- Interview Questions ExperiencesDocument9 pagesInterview Questions ExperiencesPallav AnandNo ratings yet
- Churned A Matrix V 3Document29 pagesChurned A Matrix V 3Pallav AnandNo ratings yet
- Churned A Matrix V 3Document29 pagesChurned A Matrix V 3Pallav AnandNo ratings yet
- Data Processing With Dplyr TidyrDocument25 pagesData Processing With Dplyr TidyrPallav AnandNo ratings yet
- Machinelearningsalon Kit 28-12-2014Document155 pagesMachinelearningsalon Kit 28-12-2014Vladimir PodshivalovNo ratings yet
- No of Customers Who Are Churned in Each Customer - Group ABCDEDocument27 pagesNo of Customers Who Are Churned in Each Customer - Group ABCDEPallav AnandNo ratings yet
- Dates TimesDocument12 pagesDates TimesPallav AnandNo ratings yet
- Resume Ahmed ZaidiDocument2 pagesResume Ahmed ZaidiPallav AnandNo ratings yet
- Sanjay Natraj: Data Scientist/hadoop EngineerDocument2 pagesSanjay Natraj: Data Scientist/hadoop EngineerPallav AnandNo ratings yet
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDocument33 pages40 Interview Questions Asked at Startups in Machine Learning - Data SciencePallav Anand100% (3)
- Biological NewDocument5 pagesBiological NewPallav AnandNo ratings yet
- Students As FormDocument2 pagesStudents As FormPallav AnandNo ratings yet
- Lab 07Document15 pagesLab 07Pallav AnandNo ratings yet
- Caltrain Fares Effective 2-28-16113161316Document1 pageCaltrain Fares Effective 2-28-16113161316Pallav AnandNo ratings yet
- IsenDocument4 pagesIsenPallav AnandNo ratings yet
- Machine Learning and Data Mining: Prof. Alexander Ihler Fall 2012Document36 pagesMachine Learning and Data Mining: Prof. Alexander Ihler Fall 2012Pallav AnandNo ratings yet
- 4 HypoDocument4 pages4 HypoPallav AnandNo ratings yet
- 6 Chi SquareDocument3 pages6 Chi SquarePallav AnandNo ratings yet
- Pallav ReportDocument5 pagesPallav ReportPallav AnandNo ratings yet
- 3 2 Review Sampling, CIDocument24 pages3 2 Review Sampling, CIPallav AnandNo ratings yet
- 2 Hypo TestingDocument4 pages2 Hypo TestingPallav AnandNo ratings yet
- 3.1 Hypothesis Testing (Critical Value Approach) : StatisticsDocument3 pages3.1 Hypothesis Testing (Critical Value Approach) : StatisticsPallav AnandNo ratings yet
- Detailed List & Syllabuses of Courses: Syrian Arab Republic Damascus UniversityDocument14 pagesDetailed List & Syllabuses of Courses: Syrian Arab Republic Damascus UniversitySedra MerkhanNo ratings yet
- Presentation On Nano TechnologyDocument12 pagesPresentation On Nano TechnologyAshis karmakarNo ratings yet
- Thesis ProjectDocument23 pagesThesis Projecteyoule abdiNo ratings yet
- Icare ONE Manual 12 Languages Lo ResDocument194 pagesIcare ONE Manual 12 Languages Lo ResMila VeraNo ratings yet
- TLE 7/8 Computer Systems Servicing 2 Quarter: Ict (Exploratory)Document5 pagesTLE 7/8 Computer Systems Servicing 2 Quarter: Ict (Exploratory)Joan Cala-or Valones100% (2)
- Laptop Repair Tutorial (Chip Level) (2nd Edition) - 1Document150 pagesLaptop Repair Tutorial (Chip Level) (2nd Edition) - 1HaftamuNo ratings yet
- GCA #2 - Job Hot ListDocument40 pagesGCA #2 - Job Hot ListLevoisNo ratings yet
- 7502.9028 Manual Dover DMC I For 32bit Windows Rev11Document87 pages7502.9028 Manual Dover DMC I For 32bit Windows Rev11jamesNo ratings yet
- Home AutomationDocument4 pagesHome AutomationLiezheel Mynha AlejandroNo ratings yet
- Commercial Cooking NC II TR TESDADocument144 pagesCommercial Cooking NC II TR TESDARachel Penalosa67% (6)
- Chapter 6 Input and Output DevicesDocument7 pagesChapter 6 Input and Output DevicesKylah Joy BautistaNo ratings yet
- 12250H13 - Advanced Computer Architecture: LTPC 4 0 0 4Document8 pages12250H13 - Advanced Computer Architecture: LTPC 4 0 0 4suganyamachendranNo ratings yet
- Application of Computers To Automobile AerodynamicsDocument10 pagesApplication of Computers To Automobile AerodynamicsRodrigo BobNo ratings yet
- Characteristics of ComputersDocument2 pagesCharacteristics of ComputersBilas Joseph33% (3)
- Computer Fundamentals Document TitleDocument4 pagesComputer Fundamentals Document TitlePramitha Hanny QueencelineNo ratings yet
- Computer Hardware: Introduction To Information SystemsDocument17 pagesComputer Hardware: Introduction To Information Systemssoofi sainNo ratings yet
- United States Patent: (10) Patent No.: (45) Date of PatentDocument17 pagesUnited States Patent: (10) Patent No.: (45) Date of PatentChoo Wei shengNo ratings yet
- Brannstrom Sweden AB Operations Manual for Oil Discharge Monitoring Equipment CleanTrack 1000 BDocument233 pagesBrannstrom Sweden AB Operations Manual for Oil Discharge Monitoring Equipment CleanTrack 1000 BIvaylo IvanovNo ratings yet
- DiacomU Training Oct2013Document62 pagesDiacomU Training Oct2013Sambal Pauh100% (1)
- Types of E-Resources and Its Utilities in Library 9Document9 pagesTypes of E-Resources and Its Utilities in Library 9SudhakarNo ratings yet
- Computer SystemDocument51 pagesComputer SystemxainamagdfhdgNo ratings yet
- E220-900T30D User Manual: 868/915Mhz 30Dbm Lora Wireless ModuleDocument22 pagesE220-900T30D User Manual: 868/915Mhz 30Dbm Lora Wireless Modulegipsyking2010No ratings yet
- Dasar AlgoritmaDocument43 pagesDasar AlgoritmaSan PaoloNo ratings yet
- Nursing Informatics SystemsDocument43 pagesNursing Informatics Systemshanna castueraNo ratings yet
- CV Taras Chornyi PDFDocument3 pagesCV Taras Chornyi PDFapi-285403434No ratings yet
- FAER Scholar Programme ProposalDocument3 pagesFAER Scholar Programme ProposalHenryfordNo ratings yet
- Discovering Computers 2012Document37 pagesDiscovering Computers 2012Nghiep Nguyen100% (3)
- Basit Khan CVDocument3 pagesBasit Khan CVapi-26551191No ratings yet
- Common Competencies: No - Unit Code Unit of Competenc y Learning Outcome Methodology Assessment Approach DurationDocument3 pagesCommon Competencies: No - Unit Code Unit of Competenc y Learning Outcome Methodology Assessment Approach DurationJeru MacNo ratings yet
- CSS 11 Q1 W6-7 FinalizedDocument21 pagesCSS 11 Q1 W6-7 FinalizedAC BalioNo ratings yet