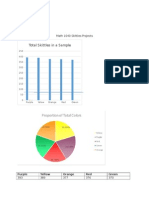
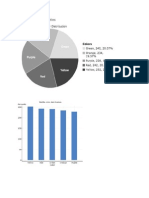
You might also like
- The Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer QuestionsDocument7 pagesThe Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer Questionsapi-438148756No ratings yet
- Visualization Quick Guide: A Best Practice Guide To Help You Find The Right Visualization For Your DataDocument21 pagesVisualization Quick Guide: A Best Practice Guide To Help You Find The Right Visualization For Your DataAman SinghNo ratings yet
- FRA PROJECT MILESTONE 1 LOGISTIC REGRESSIONDocument23 pagesFRA PROJECT MILESTONE 1 LOGISTIC REGRESSIONMaminul Islam100% (3)
- 8663 - Solutions For AS A Level Year 1 Edexcel Stats Mechanics Expert Set A v1.1Document20 pages8663 - Solutions For AS A Level Year 1 Edexcel Stats Mechanics Expert Set A v1.1Cherie Chow50% (2)
- Skittles Project 5-02Document8 pagesSkittles Project 5-02api-354040698No ratings yet
- The Rainbow ReportDocument11 pagesThe Rainbow Reportapi-316991888No ratings yet
- Math 1040Document3 pagesMath 1040api-219553415No ratings yet
- Team Project Part 6 Final ReportDocument8 pagesTeam Project Part 6 Final Reportapi-316794103No ratings yet
- Stats ProjectDocument14 pagesStats Projectapi-302666758No ratings yet
- Croot Part6 EportfolioDocument16 pagesCroot Part6 Eportfolioapi-276896975No ratings yet
- Skittle Group 1Document2 pagesSkittle Group 1api-240854983No ratings yet
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685No ratings yet
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081No ratings yet
- The Full Skittles ProjectDocument6 pagesThe Full Skittles Projectapi-340271527100% (1)
- EportfolioDocument12 pagesEportfolioapi-251934892No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-271444168No ratings yet
- 1040 Group Project Part Two 2Document2 pages1040 Group Project Part Two 2api-355821718No ratings yet
- Term Project - EportfolioDocument7 pagesTerm Project - Eportfolioapi-251981709No ratings yet
- Skittles ProjectDocument3 pagesSkittles Projectapi-300090992No ratings yet
- Skittles Final ProjectDocument5 pagesSkittles Final Projectapi-251571777No ratings yet
- StatsfinalprojectDocument7 pagesStatsfinalprojectapi-325102852No ratings yet
- Eportfolio StatisticsDocument8 pagesEportfolio Statisticsapi-325734103No ratings yet
- SkittlesDocument5 pagesSkittlesapi-249778667No ratings yet
- Project Part 3Document3 pagesProject Part 3api-236294981No ratings yet
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765No ratings yet
- Math ProfileDocument9 pagesMath Profileapi-454376679No ratings yet
- Skittles Term Project 11 9 14Document5 pagesSkittles Term Project 11 9 14api-192489685No ratings yet
- Term Project Part 3 Summary Stats - Individual PortionDocument1 pageTerm Project Part 3 Summary Stats - Individual Portionapi-284921427No ratings yet
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085No ratings yet
- Final ProjectDocument9 pagesFinal Projectapi-262329757No ratings yet
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872No ratings yet
- Math 1040 Term ProjectDocument7 pagesMath 1040 Term Projectapi-340188424No ratings yet
- Skittles 2Document4 pagesSkittles 2api-437551719No ratings yet
- Skittles Project Data This OneDocument4 pagesSkittles Project Data This Oneapi-2855517690% (1)
- 1040 ProjectDocument4 pages1040 Projectapi-279808770No ratings yet
- Skittles Project With ReflectionDocument7 pagesSkittles Project With Reflectionapi-234712126100% (1)
- Skittles SumDocument1 pageSkittles Sumapi-325442935No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849No ratings yet
- Skittles Project 2Document10 pagesSkittles Project 2api-316655135No ratings yet
- Skittles Project 2Document5 pagesSkittles Project 2api-355504623No ratings yet
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218No ratings yet
- EportfolioDocument8 pagesEportfolioapi-242211470No ratings yet
- TP 2 StatsDocument5 pagesTP 2 Statsapi-240850453No ratings yet
- Skittles WordDocument5 pagesSkittles Wordapi-285645725No ratings yet
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396No ratings yet
- Skittles ProDocument9 pagesSkittles Proapi-241124972No ratings yet
- Skittles ReportDocument5 pagesSkittles Reportapi-242736484No ratings yet
- Skittles Project FinalDocument5 pagesSkittles Project Finalapi-271348941No ratings yet
- Group Project #1 - SkittlesDocument9 pagesGroup Project #1 - Skittlesapi-245266056No ratings yet
- Skittles Project Group Final WordDocument6 pagesSkittles Project Group Final Wordapi-316239273No ratings yet
- The Skittles Project FinalDocument8 pagesThe Skittles Project Finalapi-316760667No ratings yet
- Math 1040 Skittlesterm ProjectDocument3 pagesMath 1040 Skittlesterm Projectapi-383654278No ratings yet
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832No ratings yet
- Term Project SkittlesDocument4 pagesTerm Project Skittlesapi-356003029No ratings yet
- Skittles FinalDocument12 pagesSkittles Finalapi-241861434No ratings yet
- Skittles Project Part 5Document16 pagesSkittles Project Part 5api-246855746No ratings yet
- Term Project: Report IntroductionDocument9 pagesTerm Project: Report Introductionapi-319795406No ratings yet
- Skittles 2 FinalDocument12 pagesSkittles 2 Finalapi-242194552No ratings yet
- Term Project Part 7Document8 pagesTerm Project Part 7api-291870758No ratings yet
- Skittle Term ProjectDocument15 pagesSkittle Term Projectapi-260271892No ratings yet
- Skittle Project FinalDocument6 pagesSkittle Project Finalapi-252859182No ratings yet
- AnxietyDocument4 pagesAnxietyapi-313630053No ratings yet
- Skittlepart3 CorrectionDocument2 pagesSkittlepart3 Correctionapi-313630053No ratings yet
- PKD PaperDocument7 pagesPKD Paperapi-313630053100% (2)
- PKDDocument4 pagesPKDapi-313630053No ratings yet
- Article SummaryDocument4 pagesArticle Summaryapi-313630053No ratings yet
- BUSN 5760 Mid TermDocument27 pagesBUSN 5760 Mid TermNiccole MaldonadoNo ratings yet
- MTH 216 MATH 216 mth216 Math 216 QUANTITATIVE REASONING IIDocument32 pagesMTH 216 MATH 216 mth216 Math 216 QUANTITATIVE REASONING IIBestMATHcourseNo ratings yet
- The Many Meanings of QuartileDocument9 pagesThe Many Meanings of QuartilealbgomezNo ratings yet
- Week 4: Mini Project: Part 1: Familiarize Yourself With The DatasetDocument14 pagesWeek 4: Mini Project: Part 1: Familiarize Yourself With The DatasetBigTunaNo ratings yet
- Investigtion Report 2700wdDocument16 pagesInvestigtion Report 2700wdapi-460543617No ratings yet
- Semester 1 ExamDocument39 pagesSemester 1 ExamNamory DOSSONo ratings yet
- Descriptive Statistics ModifiedDocument36 pagesDescriptive Statistics ModifiedMohammad Bony IsrailNo ratings yet
- GEA1000 Finals CheatsheetDocument2 pagesGEA1000 Finals CheatsheetmaryamNo ratings yet
- Data Visualization - Getting Started With PlotlyDocument37 pagesData Visualization - Getting Started With Plotlymartin napangaNo ratings yet
- BEd 1.5Document24 pagesBEd 1.5Zeeshan ShaniNo ratings yet
- Chapter 1Document37 pagesChapter 1Evan ThanhNo ratings yet
- IGCSE Files Telegram Channel: Thursday 22 October 2020Document24 pagesIGCSE Files Telegram Channel: Thursday 22 October 2020Ayyub SNo ratings yet
- Statistical Methods For Decision MakingDocument15 pagesStatistical Methods For Decision MakingThaku Singh100% (1)
- Apostila GgplotDocument59 pagesApostila GgplotBreno Benvindo Dos AnjosNo ratings yet
- 07 Box Plots, Variance and Standard DeviationDocument5 pages07 Box Plots, Variance and Standard DeviationAlex ChildsNo ratings yet
- 01 ABE Review - Basic Concepts and Descriptive StatisticsDocument66 pages01 ABE Review - Basic Concepts and Descriptive StatisticsRio Banan IINo ratings yet
- Multi-Vari Chart (Graphing Using Minitab)Document57 pagesMulti-Vari Chart (Graphing Using Minitab)ClarkRMNo ratings yet
- Exercises 1.1: The of Which Are More Consistent From The Point of View of ?Document3 pagesExercises 1.1: The of Which Are More Consistent From The Point of View of ?Abd El-Razek AhmedNo ratings yet
- Oracle Bi Sample App Content GuideDocument174 pagesOracle Bi Sample App Content Guideavinashworld100% (1)
- Unit CoversDocument7 pagesUnit Coversapi-234130682No ratings yet
- Chapter 3 Slides #4 BoxplotsDocument10 pagesChapter 3 Slides #4 BoxplotsMinh NgọcNo ratings yet
- HTMRNDocument48 pagesHTMRNDaveNo ratings yet
- Terms 2Document11 pagesTerms 2jlayambotNo ratings yet
- Teaching Statistics: Using Climatic DataDocument24 pagesTeaching Statistics: Using Climatic DataNourddin KoulaliNo ratings yet
- June 2017 (IAL) QP - S1 Edexcel PDFDocument24 pagesJune 2017 (IAL) QP - S1 Edexcel PDFChryssa EconomouNo ratings yet
- PMC500 Tutorial 1 Norazliza BT Abd AzizDocument13 pagesPMC500 Tutorial 1 Norazliza BT Abd AzizAmz Abd AzizNo ratings yet
- CSE3506 Logistic Regression Predicts Red Wine QualityDocument10 pagesCSE3506 Logistic Regression Predicts Red Wine QualityShivam Batra100% (1)