You might also like
- Challenges of SSD Forensic Analysis (37p)Document37 pagesChallenges of SSD Forensic Analysis (37p)Akis KaragiannisNo ratings yet
- PlayStation 2 Architecture: Architecture of Consoles: A Practical Analysis, #12From EverandPlayStation 2 Architecture: Architecture of Consoles: A Practical Analysis, #12No ratings yet
- Tutorial T2: Fundamentals of Memory Subsystem Design For HPC and AIDocument105 pagesTutorial T2: Fundamentals of Memory Subsystem Design For HPC and AIdxzhangNo ratings yet
- DSE 4510 Dse4520 Operator ManualDocument64 pagesDSE 4510 Dse4520 Operator ManualPedro100% (5)
- 9098i Circuit Diagrams Overlays Issue 2Document321 pages9098i Circuit Diagrams Overlays Issue 2Robert Morris100% (1)
- Telephone Systems PDFDocument13 pagesTelephone Systems PDFsorry2qaz67% (3)
- ARM Cortex M3 RegistersDocument22 pagesARM Cortex M3 RegistersRaveendra Moodithaya100% (2)
- 3phase TSDDocument114 pages3phase TSDSridhar Chigati100% (3)
- Electronics Washing Machine ControlDocument4 pagesElectronics Washing Machine ControlMohd ShukriNo ratings yet
- Diagram Electrico 962h Ssa00244Document27 pagesDiagram Electrico 962h Ssa00244eleuterio100% (2)
- Lecture 1 Introduction 2018 19 PDFDocument36 pagesLecture 1 Introduction 2018 19 PDFswams_suni647No ratings yet
- CS 3853 Computer Architecture - Memory HierarchyDocument37 pagesCS 3853 Computer Architecture - Memory HierarchyJothi RamasamyNo ratings yet
- Computer Architecture: Memory Hierarchy DesignDocument60 pagesComputer Architecture: Memory Hierarchy Designapi-26594847No ratings yet
- CMSC 611: Advanced Computer ArchitectureDocument21 pagesCMSC 611: Advanced Computer Architecturemanish0009No ratings yet
- Lec07 Memory sp17Document99 pagesLec07 Memory sp17Golnaz KorkianNo ratings yet
- Computer Organization and Architecture Chapter 7 Large and Fast ExploitingDocument32 pagesComputer Organization and Architecture Chapter 7 Large and Fast Exploitingtazusamamiya2No ratings yet
- High Performance Scientific Computing: S. Gopalakrishnan!Document17 pagesHigh Performance Scientific Computing: S. Gopalakrishnan!Pratik ShirsathNo ratings yet
- Module One - Part I - Memory IntroDocument20 pagesModule One - Part I - Memory Intronirosha vijayNo ratings yet
- L5: ROM and Memory HierarchyDocument14 pagesL5: ROM and Memory HierarchyNeel RavalNo ratings yet
- Computer Architecture: Memory HierarchyDocument42 pagesComputer Architecture: Memory HierarchyElisée NdjabuNo ratings yet
- CS 1550: Introduction To Operating SystemsDocument33 pagesCS 1550: Introduction To Operating SystemsmohammedgoaNo ratings yet
- Cache Memory ADocument62 pagesCache Memory ARamiz KrasniqiNo ratings yet
- He-Dieu-Hanh - Kai-Li - Disksflash - (Cuuduongthancong - Com)Document27 pagesHe-Dieu-Hanh - Kai-Li - Disksflash - (Cuuduongthancong - Com)ng.tuandungcsNo ratings yet
- 21 - Virtualmemory2 - WIDEDocument36 pages21 - Virtualmemory2 - WIDEChirag SoodNo ratings yet
- Pretrained NetworksDocument42 pagesPretrained NetworksHarish ParuchuriNo ratings yet
- CELF ELC Europe 2009: On Threads, Processes and Co-ProcessesDocument35 pagesCELF ELC Europe 2009: On Threads, Processes and Co-ProcessesrajNo ratings yet
- MemoryDocument125 pagesMemoryprjtNo ratings yet
- Document Exadata 3 PDFDocument127 pagesDocument Exadata 3 PDFAnonymous rt8iK9pbNo ratings yet
- CS6461 - Computer Architecture Fall 2016 Morris Lancaster - Memory SystemsDocument66 pagesCS6461 - Computer Architecture Fall 2016 Morris Lancaster - Memory Systems闫麟阁No ratings yet
- Lec13 Memory 1 NotesDocument27 pagesLec13 Memory 1 Noteschancharlie30624700No ratings yet
- Microprocessor System Design: Error Correcting Codes Principle of Locality Cache ArchitectureDocument28 pagesMicroprocessor System Design: Error Correcting Codes Principle of Locality Cache ArchitectureBabasrinivas GuduruNo ratings yet
- Memory Hierarchy and Cache Design: Computer Architecture ECE 201Document62 pagesMemory Hierarchy and Cache Design: Computer Architecture ECE 201shravaniNo ratings yet
- Welcome: Technical Services Virtual Boot CampDocument52 pagesWelcome: Technical Services Virtual Boot Campajay kumarNo ratings yet
- Hitachi Deskstar 120 GXPDocument2 pagesHitachi Deskstar 120 GXPanghockbinNo ratings yet
- FlashMemory w2021Document20 pagesFlashMemory w2021Gregori Moises Cruz SantanaNo ratings yet
- Linux Block IO Paper Systor13-Final18Document10 pagesLinux Block IO Paper Systor13-Final18vishrabagNo ratings yet
- Cache and The Memory Hierarchy Part One: Computer Organization II Spring 2017 Gedare BloomDocument31 pagesCache and The Memory Hierarchy Part One: Computer Organization II Spring 2017 Gedare BloomJosef JoestarNo ratings yet
- Understading SSD With OpenssdDocument62 pagesUnderstading SSD With OpenssdkasthurithejaNo ratings yet
- Sizing Storage Unity XT 380 BootcampDocument4 pagesSizing Storage Unity XT 380 Bootcampyinsoph.andradexNo ratings yet
- 08 - Memory ManagementDocument36 pages08 - Memory ManagementShunyi LiuNo ratings yet
- Lecture1 E5231Document24 pagesLecture1 E5231irfan khanNo ratings yet
- Genertions of OSDocument31 pagesGenertions of OSSamavia RiazNo ratings yet
- Back To The Roots Oracle Database IO ManagementDocument35 pagesBack To The Roots Oracle Database IO Management신종근No ratings yet
- UntitledDocument112 pagesUntitledPavan NavNo ratings yet
- Memory Management: Fred Kuhns Department of Computer Science and Engineering Washington University in St. LouisDocument34 pagesMemory Management: Fred Kuhns Department of Computer Science and Engineering Washington University in St. LouisMadhur shailesh Dwivedi100% (1)
- Hynix H27U518S2C 64 MB NAND Flash - Data SheetDocument37 pagesHynix H27U518S2C 64 MB NAND Flash - Data SheetDNo ratings yet
- CS 1550: Introduction To Operating Systems: Prof. Ahmed AmerDocument33 pagesCS 1550: Introduction To Operating Systems: Prof. Ahmed AmerHave No IdeaNo ratings yet
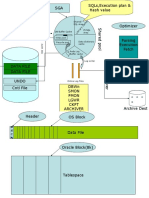
- Y Ca CH E: Shared/ SQL Area Fetching by Server Process Keep PoolDocument36 pagesY Ca CH E: Shared/ SQL Area Fetching by Server Process Keep Poolroudy1No ratings yet
- Lec10 Sram1Document19 pagesLec10 Sram1VenkatGollaNo ratings yet
- Lec3 - Cache and Memory SystemDocument18 pagesLec3 - Cache and Memory SystemVăn Nam NgôNo ratings yet
- Digital VLSI Design Lecture 1: Introduction: Semester B, 2022 Lecturer: Zvika Webb 21 Feb 2022Document53 pagesDigital VLSI Design Lecture 1: Introduction: Semester B, 2022 Lecturer: Zvika Webb 21 Feb 2022Shay SamiaNo ratings yet
- Oracle Cloud Block Volume 100Document23 pagesOracle Cloud Block Volume 100Dharmesh BNo ratings yet
- p1364r0 2Document10 pagesp1364r0 2FlailzzNo ratings yet
- DiskOnChip Based MCP01 Rev0.4Document146 pagesDiskOnChip Based MCP01 Rev0.4spotNo ratings yet
- Evaluating Performance and Energy in File System Server WorkloadsDocument31 pagesEvaluating Performance and Energy in File System Server Workloadsdisnet03No ratings yet
- Ds Fusion Iodrive DuoDocument4 pagesDs Fusion Iodrive DuoasNo ratings yet
- HC2021.UWisc - Karu Sankaralingam.v02Document20 pagesHC2021.UWisc - Karu Sankaralingam.v02ddscribeNo ratings yet
- Flash Mem Summit Jcooke Inconvenient Truths NandDocument32 pagesFlash Mem Summit Jcooke Inconvenient Truths Nandiiokojx386No ratings yet
- Index: Power Quotient International Co., LTDDocument73 pagesIndex: Power Quotient International Co., LTDSsr ShaNo ratings yet
- Vmworld Europe 2009 Vscsistats PDFDocument28 pagesVmworld Europe 2009 Vscsistats PDFBla bla blaNo ratings yet
- Hardware Design of Data Controller For Nand Flash MemoryDocument33 pagesHardware Design of Data Controller For Nand Flash MemoryDevasish BhagawatiNo ratings yet
- Hardware Design of Data Controller For Nand Flash MemoryDocument33 pagesHardware Design of Data Controller For Nand Flash MemoryDevasish BhagawatiNo ratings yet
- Challenges of SSD Forensic Analysis: by Digital AssemblyDocument44 pagesChallenges of SSD Forensic Analysis: by Digital AssemblyMohd Asri XSxNo ratings yet
- Onur Comparch Fall2022 Lecture2a Memory Trends Challenges Opportunities AfterlectureDocument139 pagesOnur Comparch Fall2022 Lecture2a Memory Trends Challenges Opportunities AfterlectureAhmed EidNo ratings yet
- Chapter5 Memory HierarchyDocument106 pagesChapter5 Memory HierarchySANG ĐẶNG HÀNo ratings yet
- Cse502 L3 Memory Hierarchy and CachesDocument38 pagesCse502 L3 Memory Hierarchy and CachesHARSHIT VERMANo ratings yet
- ReVox A77 Serv Man CompleteDocument114 pagesReVox A77 Serv Man CompleteCristian CotetNo ratings yet
- Reference Manual: ModelDocument162 pagesReference Manual: ModelrassesNo ratings yet
- Service Manual Lh780Document1,150 pagesService Manual Lh780Phạm Ngọc TàiNo ratings yet
- Academic Handbook of MITDocument170 pagesAcademic Handbook of MITVibhav PawarNo ratings yet
- Ad4329 ManualDocument54 pagesAd4329 ManualHasan KendekNo ratings yet
- The MOSFET Unity Gain FrequencyDocument2 pagesThe MOSFET Unity Gain Frequencyhariansyah0No ratings yet
- Impact of Inverter-Based Resources On Impedance-Based Protection FunctionsDocument6 pagesImpact of Inverter-Based Resources On Impedance-Based Protection Functionsamina bu bakerNo ratings yet
- Pass Transistor Logic PDFDocument25 pagesPass Transistor Logic PDFTejas KumbarNo ratings yet
- Solid StateDocument5 pagesSolid StateDar KeyyNo ratings yet
- Automated Comparator: Radian Research, IncDocument97 pagesAutomated Comparator: Radian Research, IncManuel Lavado SilvaNo ratings yet
- CDR Questionnaire Form: of The Project I.E. How The Objectives of The Project Was Accomplished in Brief.)Document3 pagesCDR Questionnaire Form: of The Project I.E. How The Objectives of The Project Was Accomplished in Brief.)Uttam AcharyaNo ratings yet
- AVHDLDocument183 pagesAVHDLIslam SamirNo ratings yet
- Bypass Switch - 40A 1.0 Za PDFDocument1 pageBypass Switch - 40A 1.0 Za PDFYvesNo ratings yet
- Product Catalogue 2015Document203 pagesProduct Catalogue 2015Burghelea Ovidiu-GabrielNo ratings yet
- Smart HelmetDocument5 pagesSmart HelmetIJARSCT JournalNo ratings yet
- Brushless DC MotorsDocument21 pagesBrushless DC MotorsKiran KumarNo ratings yet
- Spaj 140 CDocument8 pagesSpaj 140 CaktifiantoNo ratings yet
- Aspire 8930qDocument124 pagesAspire 8930qSg TopolinoNo ratings yet
- S202P-C40 Miniature Circuit Breaker - 2P - C - 40 A: Product-DetailsDocument6 pagesS202P-C40 Miniature Circuit Breaker - 2P - C - 40 A: Product-DetailsBilalNo ratings yet
- Centurion Configurable Controller Installation and Operations ManualDocument44 pagesCenturion Configurable Controller Installation and Operations ManualAnonymous LfeGI2hMNo ratings yet
- Tig 3001 Spare PartsDocument12 pagesTig 3001 Spare PartsJesus Pedro CarvalhoNo ratings yet
- Aire Acondicionado ASY12FSBCWDocument2 pagesAire Acondicionado ASY12FSBCWJano NymusNo ratings yet
- Panasonic KX NCP500 1000 Installation Manual PDFDocument142 pagesPanasonic KX NCP500 1000 Installation Manual PDFLuisGermainSegoviaLlanquinNo ratings yet