You might also like
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignFrom EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNo ratings yet
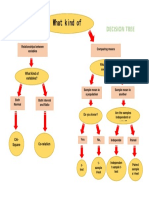
- What Kind of Test: Decision TreeDocument1 pageWhat Kind of Test: Decision TreeghNo ratings yet
- Two Samples: Testing The Difference of Means of Two Independent SamplesDocument1 pageTwo Samples: Testing The Difference of Means of Two Independent Samplesreshma thomasNo ratings yet
- Stats 4TH Quarter ReviewerDocument2 pagesStats 4TH Quarter ReviewerKhryzelle BañagaNo ratings yet
- PYC3704 Past Exam QuestionsDocument143 pagesPYC3704 Past Exam QuestionsgavhumendeNo ratings yet
- Hypothesis Testing - For TeachingDocument17 pagesHypothesis Testing - For TeachingTanmay IyerNo ratings yet
- Sample Size Estimation: Original Author: Jonathan Berkowitz PHD Perc Reviewer: Timothy Lynch MDDocument21 pagesSample Size Estimation: Original Author: Jonathan Berkowitz PHD Perc Reviewer: Timothy Lynch MDLeaNo ratings yet
- Depedpang 1Document127 pagesDepedpang 1Bayoyong NhsNo ratings yet
- Day 21 - Repeated-Measures ANOVADocument5 pagesDay 21 - Repeated-Measures ANOVADarlene CorderoNo ratings yet
- HR AnalyticsDocument15 pagesHR AnalyticsPranavNo ratings yet
- MAS 202 Final Exam Topics Fall 2021Document2 pagesMAS 202 Final Exam Topics Fall 2021Katie PiccoloNo ratings yet
- Type of Data Application of Statistics in EpidemiologyDocument14 pagesType of Data Application of Statistics in EpidemiologyAldrin AntivolaNo ratings yet
- 06 Hypothesis Testing For Two Population Parameter PDFDocument52 pages06 Hypothesis Testing For Two Population Parameter PDFAngela Erish CastroNo ratings yet
- Module 5.hypothesis TestingDocument16 pagesModule 5.hypothesis TestingSonali SinghNo ratings yet
- Statistical Analysis in Neuroimaging: T-tests, ANOVAs, and RegressionDocument39 pagesStatistical Analysis in Neuroimaging: T-tests, ANOVAs, and RegressionWork PlaceNo ratings yet
- Lesson 6 - Statistics For Data Science - IIDocument60 pagesLesson 6 - Statistics For Data Science - IIrimbrahimNo ratings yet
- Calculating confidence intervals and hypothesis tests for a population mean from one sampleDocument1 pageCalculating confidence intervals and hypothesis tests for a population mean from one sampleJeevan RegmiNo ratings yet
- One Sample Mean Summary Formulas PDFDocument1 pageOne Sample Mean Summary Formulas PDFreshma thomasNo ratings yet
- Parametric Tests: t-Tests and ANOVADocument57 pagesParametric Tests: t-Tests and ANOVAMukul BhatnagarNo ratings yet
- IL1-Measures of Disease FrequencyDocument5 pagesIL1-Measures of Disease FrequencyVanessa HermioneNo ratings yet
- Analyze Phase: The Aim of The Analyze Phase Is ToDocument49 pagesAnalyze Phase: The Aim of The Analyze Phase Is Tosaurabh pNo ratings yet
- ("The Paired Population Means Are Equal") ("The Paired Population Means Are Not Equal") Dependent - Measured Wilcoxon Signed-Ranks TestDocument10 pages("The Paired Population Means Are Equal") ("The Paired Population Means Are Not Equal") Dependent - Measured Wilcoxon Signed-Ranks TestMikahNo ratings yet
- Sampling Distributions & Standard Error: Lesson 7Document20 pagesSampling Distributions & Standard Error: Lesson 7Lorena TeofiloNo ratings yet
- AnovaDocument22 pagesAnovaFun Toosh345No ratings yet
- Which Statistical Tests To UseDocument2 pagesWhich Statistical Tests To Useian1231No ratings yet
- Application of ANOVADocument19 pagesApplication of ANOVAabhay_prakash_ranjan100% (2)
- 4.analyze 184Document49 pages4.analyze 184lucky prajapatiNo ratings yet
- Chapter 2-1Document27 pagesChapter 2-1EdgarNo ratings yet
- Hypothesis Testing: - DR Najib H.S. Farhan Universal Business SchoolDocument20 pagesHypothesis Testing: - DR Najib H.S. Farhan Universal Business SchoolZeus ZeusNo ratings yet
- TestSummary Handout1 v01Document2 pagesTestSummary Handout1 v01KIM THUyNo ratings yet
- Application of ANOVADocument18 pagesApplication of ANOVAUma Shankar38% (8)
- Test of Difference Correlational SP EsDocument6 pagesTest of Difference Correlational SP EsLampano AngelineNo ratings yet
- Hypothesis Tests SummaryDocument2 pagesHypothesis Tests SummaryJelaNo ratings yet
- WK 11-Session 11 Notes-Hypothesis Testing (Two Samples) - UploadDocument12 pagesWK 11-Session 11 Notes-Hypothesis Testing (Two Samples) - UploadLIAW ANN YINo ratings yet
- جدول الطولDocument1 pageجدول الطولllmoj1997No ratings yet
- Chap 009Document59 pagesChap 009Rohit Raj PandeyNo ratings yet
- One sample proportion confidence intervals and hypothesis testsDocument1 pageOne sample proportion confidence intervals and hypothesis testsJeevan RegmiNo ratings yet
- 3D Formulae SheetDocument1 page3D Formulae SheetmeeteshlalNo ratings yet
- Which Statistical Tests To UseDocument1 pageWhich Statistical Tests To UsePam FajardoNo ratings yet
- How To Select A Test ?Document11 pagesHow To Select A Test ?Triando ErsandiNo ratings yet
- Common StatisticsDocument23 pagesCommon StatisticsJeffNo ratings yet
- Introduction To Statistics - 19!3!21Document47 pagesIntroduction To Statistics - 19!3!21balaa aiswaryaNo ratings yet
- Tests: in General, - Tests Incorporate An "Estimation" ofDocument34 pagesTests: in General, - Tests Incorporate An "Estimation" ofNareshh SulenaNo ratings yet
- T, F & RegressionDocument44 pagesT, F & RegressionAbdul HananNo ratings yet
- Own Formula SheetDocument3 pagesOwn Formula SheetPATRICIA TRUJILLO SANZNo ratings yet
- (N) Sampling: PopulationDocument1 page(N) Sampling: PopulationJulia MikuckaNo ratings yet
- EDA-report_GONZALES-EJ (1)Document8 pagesEDA-report_GONZALES-EJ (1)EJ GonzalesNo ratings yet
- ANOVA: Analyze Variance DifferencesDocument40 pagesANOVA: Analyze Variance DifferencesvvinaybhardwajNo ratings yet
- Notes: AnovaDocument6 pagesNotes: AnovaaddinaNo ratings yet
- Testing ProportionsDocument2 pagesTesting ProportionsboNo ratings yet
- Lecture 26 CompactDocument5 pagesLecture 26 CompactDela Cruz DearNo ratings yet
- Lesson For T TestsDocument53 pagesLesson For T TestsShin GuzmanNo ratings yet
- SamplingDocument27 pagesSamplingRegina CahyaniNo ratings yet
- Lab Assignment #2 HamidDocument7 pagesLab Assignment #2 HamidPohuyistNo ratings yet
- Summary Table For Statistical TechniquesDocument4 pagesSummary Table For Statistical Techniquesamul65No ratings yet
- Estimation of ParametersDocument20 pagesEstimation of ParametersJohnRoldGleyPanaliganNo ratings yet
- Independent Sample T Test PDFDocument2 pagesIndependent Sample T Test PDFalfanNo ratings yet
- Paired Samples Test Compares Pre and Post Pain EpisodesDocument1 pagePaired Samples Test Compares Pre and Post Pain EpisodesHow to youNo ratings yet
- Parameters and StatisticsDocument12 pagesParameters and StatisticsShe EnaNo ratings yet
- Demand Pattern: 1. Plot The Demand and Share The Characteristics of Demand PatternDocument10 pagesDemand Pattern: 1. Plot The Demand and Share The Characteristics of Demand PatternParikshit MahajanNo ratings yet
- Equivalence Tests For One ProportionDocument25 pagesEquivalence Tests For One ProportionTasneem JahanNo ratings yet
- Formulas For The Final ExamDocument3 pagesFormulas For The Final ExamTrisha Faith AlberNo ratings yet
- Construction Cost Estimation - A Parametric Approach ForDocument11 pagesConstruction Cost Estimation - A Parametric Approach FormrvictormrrrNo ratings yet
- Series Date HDFC Close Price Nifty Clo Ri (HDFC) RM (Nifty 5date Close GT 9Document11 pagesSeries Date HDFC Close Price Nifty Clo Ri (HDFC) RM (Nifty 5date Close GT 9B Akhil Sai KishoreNo ratings yet
- Pengaruh Hutang Dan Ekuitas Terhadap Profitabilitas Pada Perusahaan Aneka Industri Yang Terdaftar Di Bursa Efek IndonesiaDocument11 pagesPengaruh Hutang Dan Ekuitas Terhadap Profitabilitas Pada Perusahaan Aneka Industri Yang Terdaftar Di Bursa Efek IndonesiaTitin SuhartiniNo ratings yet
- IB Questionbank Maths SL 1Document7 pagesIB Questionbank Maths SL 1Priya Vijay kumaarNo ratings yet
- Tutorial 1 QuestionsDocument4 pagesTutorial 1 QuestionsbeatlollolNo ratings yet
- Age and Gender Impact on Magazine SubscriptionsDocument5 pagesAge and Gender Impact on Magazine Subscriptionshaider_simple71No ratings yet
- Pothos ExperimentDocument5 pagesPothos Experimentapi-529346841No ratings yet
- Multiple Regression Predicts Elementary School Academic PerformanceDocument12 pagesMultiple Regression Predicts Elementary School Academic PerformanceVibeesh KettavanNo ratings yet
- 2009 Poisson DistributionDocument6 pages2009 Poisson Distributionfabremil7472100% (4)
- MLP Sous Keras: A. MLP Pour Une Classification BinaireDocument2 pagesMLP Sous Keras: A. MLP Pour Une Classification BinaireSoufiane BiggiNo ratings yet
- Estimatr Cheat Sheet: Quick Reference for Linear Models, Instrumental Variables, and More in RDocument1 pageEstimatr Cheat Sheet: Quick Reference for Linear Models, Instrumental Variables, and More in RfcgarciaNo ratings yet
- Panel Data Models: Dynamic Panels and Unit RootsDocument20 pagesPanel Data Models: Dynamic Panels and Unit RootsJeremiahOmwoyoNo ratings yet
- Institute of Rural Management AnandDocument3 pagesInstitute of Rural Management AnandSurya BhartiNo ratings yet
- Gianola-Fernando-Bayesian Methods-1986-J Anim SciDocument28 pagesGianola-Fernando-Bayesian Methods-1986-J Anim Scijose raul perezNo ratings yet
- Faculty of Business and Management: Assignment/ Project Declaration FormDocument8 pagesFaculty of Business and Management: Assignment/ Project Declaration FormnurainNo ratings yet
- Stat 491 Chapter 8 - Hypothesis Testing - Two Sample InferenceDocument39 pagesStat 491 Chapter 8 - Hypothesis Testing - Two Sample InferenceHarry BerryNo ratings yet
- Mix Design QnsDocument2 pagesMix Design QnsGaddam SudheerNo ratings yet
- Correlation Analysis ChapterDocument46 pagesCorrelation Analysis ChapterShyam SundarNo ratings yet
- Descriptive Statistics: Frequency Distributions and Related StatisticsDocument47 pagesDescriptive Statistics: Frequency Distributions and Related Statisticsha ssanNo ratings yet
- Analysis of Test Data-HandoutDocument20 pagesAnalysis of Test Data-HandoutEdd VillamorNo ratings yet
- Basic Statistical ToolsDocument43 pagesBasic Statistical ToolsHaytham Janoub HamoudaNo ratings yet
- Regression AnalysisDocument44 pagesRegression AnalysisPritisha SrivastavaNo ratings yet
- Industrial InstrumentationDocument30 pagesIndustrial InstrumentationNHIÊN CÙ VĂNNo ratings yet
- Mansi Bharne 16/10: Unit Viii: Correlation and RegressionDocument5 pagesMansi Bharne 16/10: Unit Viii: Correlation and RegressionVrushab PunjabiNo ratings yet
- Final Project - ML - Nikita Chaturvedi - 03.10.2021 - Jupyter NotebookDocument154 pagesFinal Project - ML - Nikita Chaturvedi - 03.10.2021 - Jupyter NotebookNikita Chaturvedi100% (10)
- Representations of Data and Correlation - Test A (50 Mins) : Graph Paper NeededDocument1 pageRepresentations of Data and Correlation - Test A (50 Mins) : Graph Paper NeededHo Lam, Trish LauNo ratings yet
- Mean and Variance QuestionsDocument4 pagesMean and Variance QuestionsFlorea VictorNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 5 out of 5 stars5/5 (2)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Calculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusFrom EverandCalculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusRating: 4.5 out of 5 stars4.5/5 (2)
- Psychology Behind Mathematics - The Comprehensive GuideFrom EverandPsychology Behind Mathematics - The Comprehensive GuideNo ratings yet
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathFrom EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathRating: 5 out of 5 stars5/5 (1)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 4.5 out of 5 stars4.5/5 (20)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)
- Math Magic: How To Master Everyday Math ProblemsFrom EverandMath Magic: How To Master Everyday Math ProblemsRating: 3.5 out of 5 stars3.5/5 (15)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceFrom EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceNo ratings yet
- Classroom-Ready Number Talks for Kindergarten, First and Second Grade Teachers: 1,000 Interactive Activities and Strategies that Teach Number Sense and Math FactsFrom EverandClassroom-Ready Number Talks for Kindergarten, First and Second Grade Teachers: 1,000 Interactive Activities and Strategies that Teach Number Sense and Math FactsNo ratings yet
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)