You might also like
- Cotext InformationDocument1 pageCotext InformationShashi ShirkeNo ratings yet
- Cotext InformationDocument1 pageCotext InformationShashi ShirkeNo ratings yet
- Grammer Ref2Document3 pagesGrammer Ref2Shashi ShirkeNo ratings yet
- Power BI Ref1Document2 pagesPower BI Ref1Shashi ShirkeNo ratings yet
- SQL Skill Test BIADocument2 pagesSQL Skill Test BIAShashi ShirkeNo ratings yet
- SQL Sever LoginDocument1 pageSQL Sever LoginShashi ShirkeNo ratings yet
- UntitledDocument1 pageUntitledShashi ShirkeNo ratings yet
- Multi Row FunctionDocument1 pageMulti Row FunctionShashi ShirkeNo ratings yet
- Grammer TestDocument3 pagesGrammer TestShashi ShirkeNo ratings yet
- Sample1 InterviewDocument1 pageSample1 InterviewShashi ShirkeNo ratings yet
- Power BI SampleDocument2 pagesPower BI SampleShashi ShirkeNo ratings yet
- Medicare Inpatient 2017Document8,939 pagesMedicare Inpatient 2017Shashi Shirke100% (1)
- EMPDocument1 pageEMPShashi ShirkeNo ratings yet
- Load Multiple Files and Configure ODI CloudDocument3 pagesLoad Multiple Files and Configure ODI CloudShashi ShirkeNo ratings yet
- Query OutputDocument1 pageQuery OutputShashi ShirkeNo ratings yet
- Hello WorldDocument1 pageHello WorldAmrutha ReddyNo ratings yet
- Error 6Document1 pageError 6Shashi ShirkeNo ratings yet
- Intro of QlikDocument5 pagesIntro of QlikShashi ShirkeNo ratings yet
- Error 8Document1 pageError 8Shashi ShirkeNo ratings yet
- Error 1Document1 pageError 1Shashi ShirkeNo ratings yet
- Error 3Document1 pageError 3Shashi ShirkeNo ratings yet
- Error 5Document2 pagesError 5Shashi ShirkeNo ratings yet
- Factors Influencing Grapevine Activity I: R IxaDocument1 pageFactors Influencing Grapevine Activity I: R IxaShashi ShirkeNo ratings yet
- Error 4Document1 pageError 4Shashi ShirkeNo ratings yet
- Formal & Informal Channel of CommunicationDocument47 pagesFormal & Informal Channel of CommunicationShashi ShirkeNo ratings yet
- Centralized NetworksDocument1 pageCentralized NetworksShashi ShirkeNo ratings yet
- Informal Communication Structures & FlowsDocument1 pageInformal Communication Structures & FlowsShashi ShirkeNo ratings yet
- Network Roles Bridge Liaison Isolate Isolated Dyad CosmopolitesDocument1 pageNetwork Roles Bridge Liaison Isolate Isolated Dyad CosmopolitesShashi ShirkeNo ratings yet
- This Is The Numeric Document Which Is Help To Upload The Document in Any FormatDocument1 pageThis Is The Numeric Document Which Is Help To Upload The Document in Any FormatShashi ShirkeNo ratings yet
- Formal & Informal Channel of CommunicationDocument47 pagesFormal & Informal Channel of CommunicationShashi ShirkeNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5782)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- MCS 023Document118 pagesMCS 023Avnit singhNo ratings yet
- Mysqlcourse 190815092242Document71 pagesMysqlcourse 190815092242Scribe.coNo ratings yet
- Tables and KeysDocument23 pagesTables and KeysShantanu DashNo ratings yet
- DBMS Module-1 PPT UpdatedDocument100 pagesDBMS Module-1 PPT UpdatedHarsshithaNo ratings yet
- 002 L4DC DBAS Sample SADocument4 pages002 L4DC DBAS Sample SAEaint EaindraNo ratings yet
- Microsoft DP-900 Free Practice Exam & Test Training - ITExamsDocument16 pagesMicrosoft DP-900 Free Practice Exam & Test Training - ITExamstimpu33No ratings yet
- Access 2007 Intro to Database ProgramsDocument22 pagesAccess 2007 Intro to Database ProgramsandreeNo ratings yet
- Common Errors: APP-INV-05706: Warning: Cannot Retrieve Transfer Price For The ItemDocument2 pagesCommon Errors: APP-INV-05706: Warning: Cannot Retrieve Transfer Price For The Itempravinprasad_d4831No ratings yet
- Dbms LabDocument245 pagesDbms LabR B SHARANNo ratings yet
- List of CoursesDocument4 pagesList of CoursesAmit SharmaNo ratings yet
- Oracle QueriesDocument606 pagesOracle Queriesarjun.ec63380% (5)
- Templated Controls Databinding: Notes Burhan SaadiDocument81 pagesTemplated Controls Databinding: Notes Burhan SaadiiinvulnerableNo ratings yet
- Funda 1 List - Partition - May 29thDocument4 pagesFunda 1 List - Partition - May 29thapi-3745527No ratings yet
- AcuXDBC User's Guide v8.1Document288 pagesAcuXDBC User's Guide v8.1Alberto GonzalezNo ratings yet
- DBMS SQL Sub QueriesDocument4 pagesDBMS SQL Sub QueriesSwathi TudicherlaNo ratings yet
- SQL queries to analyze employee, project and assignment dataDocument8 pagesSQL queries to analyze employee, project and assignment dataCarla Jane RoxasNo ratings yet
- SQL Sqlite Commands Cheat Sheet PDFDocument5 pagesSQL Sqlite Commands Cheat Sheet PDFAnshik BansalNo ratings yet
- Data Warehousing Final ExamDocument2 pagesData Warehousing Final ExamRod S Pangantihon Jr.50% (2)
- Over 1Document2 pagesOver 1api-3743887No ratings yet
- Android DatabaseDocument7 pagesAndroid DatabaseNitishkumar KhavekarNo ratings yet
- SQL - Understanding Oracle Apex - Application.g - FNN and How To Use It - Stack OverflowDocument4 pagesSQL - Understanding Oracle Apex - Application.g - FNN and How To Use It - Stack OverflowkhalidsnNo ratings yet
- Dad Assignment - EsoftDocument11 pagesDad Assignment - Esoftsheran2333% (3)
- Railway Resevration Python ProgrameDocument11 pagesRailway Resevration Python Programenishant raj100% (1)
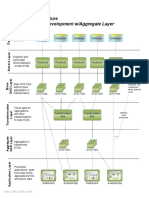
- Two-Tiered Data Architecture with Aggregate LayerDocument1 pageTwo-Tiered Data Architecture with Aggregate Layernano_xpNo ratings yet
- Lab ManualDocument17 pagesLab Manualzinabuhaile26No ratings yet
- Unica Interview QuestionsDocument2 pagesUnica Interview QuestionsmarubadiNo ratings yet
- Hands-On Database 2nd Edition Steve Conger Solutions Manual 1Document29 pagesHands-On Database 2nd Edition Steve Conger Solutions Manual 1jerry100% (44)
- Outline: Multidatabase Query ProcessingDocument41 pagesOutline: Multidatabase Query Processingiin76No ratings yet
- Practic AsDocument254 pagesPractic AsYonatan Hernandez AlvaradoNo ratings yet
- 7CS082 Report CW1Document16 pages7CS082 Report CW1Benjamin HaganNo ratings yet