You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- RudranarayanDocument1 pageRudranarayanmanosekhar8562No ratings yet
- Social Media Posts Can Hurt Veterans Job ProspectsDocument3 pagesSocial Media Posts Can Hurt Veterans Job Prospectsmanosekhar8562No ratings yet
- Bangalore To ChennaiDocument2 pagesBangalore To Chennaimanosekhar8562No ratings yet
- JishnuDocument1 pageJishnumanosekhar8562No ratings yet
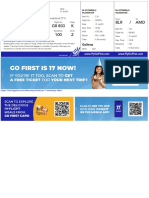
- Go First - Airline Tickets and Fares - Boarding PassDocument2 pagesGo First - Airline Tickets and Fares - Boarding Passmanosekhar8562No ratings yet
- Outreach TemplatesDocument22 pagesOutreach Templatesmanosekhar8562No ratings yet
- FariahhDocument1 pageFariahhmanosekhar8562No ratings yet
- GauravDocument1 pageGauravmanosekhar8562No ratings yet
- DeepanshuDocument1 pageDeepanshumanosekhar8562No ratings yet
- HersheyDocument5 pagesHersheymanosekhar8562No ratings yet
- EBITDA - Meaning, Formula, and HistoryDocument7 pagesEBITDA - Meaning, Formula, and Historymanosekhar8562No ratings yet
- Starbucks CEO 3 Leadership LessonsDocument21 pagesStarbucks CEO 3 Leadership Lessonsmanosekhar8562No ratings yet
- High Time That Data Takes Precedence Over Gut Feeling in HRDocument3 pagesHigh Time That Data Takes Precedence Over Gut Feeling in HRmanosekhar8562No ratings yet
- ObsCPMT PDFDocument14 pagesObsCPMT PDFmanosekhar8562No ratings yet
- ABRSM Theory Gr-1 PDFDocument30 pagesABRSM Theory Gr-1 PDFmanosekhar8562No ratings yet
- Maintenance Repair and Overhaul MRODocument8 pagesMaintenance Repair and Overhaul MRONkemakolam Celestine ChukwuNo ratings yet
- History MysteryDocument5 pagesHistory Mysterymanosekhar8562No ratings yet
- Ieee Paper 2Document16 pagesIeee Paper 2manosekhar8562No ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- English Irregular VerbsDocument9 pagesEnglish Irregular Verbsmaher SufyanNo ratings yet
- Indirect Speech Act1Document13 pagesIndirect Speech Act1darkcardNo ratings yet
- SN English Grammar: A Complete Solution For StudentsDocument6 pagesSN English Grammar: A Complete Solution For StudentsPNo ratings yet
- Teach Yorself JapaneseDocument37 pagesTeach Yorself JapaneseIrina Butunoi100% (1)
- Sentence Relations and TruthDocument25 pagesSentence Relations and TruthErick Rojas100% (1)
- The Learning of Spoken French Variation by Immersion Students From Toronto, Canada - Mougeon - 2004 - Journal of Sociolinguistics - Wiley Online LibraryDocument25 pagesThe Learning of Spoken French Variation by Immersion Students From Toronto, Canada - Mougeon - 2004 - Journal of Sociolinguistics - Wiley Online LibrarycostagutaNo ratings yet
- Dyslexia Acquired Dyslexia: Dual Routes of DamageDocument4 pagesDyslexia Acquired Dyslexia: Dual Routes of DamageFarah TarmiziNo ratings yet
- The Gettier ProblemDocument17 pagesThe Gettier ProblemTodona2No ratings yet
- THEORIES AND RESEARCH METHODOLOGY PAPERDocument27 pagesTHEORIES AND RESEARCH METHODOLOGY PAPERAnonymous u7rUYhrSw100% (1)
- Summary Reviewer in LogicDocument8 pagesSummary Reviewer in LogicMari CrisNo ratings yet
- GRAMMAR AND VOCABULARY For CAMBRIDGE ADVANCED AND PROFICIENCYDocument274 pagesGRAMMAR AND VOCABULARY For CAMBRIDGE ADVANCED AND PROFICIENCYAliona Solomon100% (3)
- Introduction to Volapük LanguageDocument14 pagesIntroduction to Volapük Languagemanuel_puertas_1No ratings yet
- Lesson 5 - Barriers To Effective CommunicationDocument2 pagesLesson 5 - Barriers To Effective CommunicationMary Rose Bobis VicenteNo ratings yet
- Eggins (2004)Document199 pagesEggins (2004)KelenLima100% (2)
- Learn 100 Hebrew Words in a MonthDocument5 pagesLearn 100 Hebrew Words in a MonthSantosh KadamNo ratings yet
- 1º Año Clase 3 - 13 Abril - Grammar 1Document9 pages1º Año Clase 3 - 13 Abril - Grammar 1Jo O ConnorNo ratings yet
- Identifying Sentence ErrorsDownload NowDocument20 pagesIdentifying Sentence ErrorsDownload NowIsh TaylorNo ratings yet
- Aning and Semantics - 3 Levels of Meaning - Expression Meaning - Utterance Meaning - Communicative Meaning 1 Meaning and Semantics Expression MeaningDocument24 pagesAning and Semantics - 3 Levels of Meaning - Expression Meaning - Utterance Meaning - Communicative Meaning 1 Meaning and Semantics Expression MeaningLimaTigaNo ratings yet
- Academic Writing Nature and Concepts ExplainedDocument45 pagesAcademic Writing Nature and Concepts Explainedaimz100% (1)
- Latihan Soal MODALSDocument8 pagesLatihan Soal MODALSnur aisyahNo ratings yet
- Coordinating ConjunctionsDocument17 pagesCoordinating ConjunctionsHsieh GraceNo ratings yet
- 1997 KollerDocument9 pages1997 KollerBecky BeckumNo ratings yet
- Icelandic Primer W 00 SweeDocument128 pagesIcelandic Primer W 00 SweeYaakov SalasNo ratings yet
- Languages 2011Document26 pagesLanguages 2011redultraNo ratings yet
- Gateways To Widen Vocabulary - EditedDocument43 pagesGateways To Widen Vocabulary - EditedLeidelen Muede MarananNo ratings yet
- Connected SpeechDocument97 pagesConnected SpeechLyza Chellum100% (1)
- M Haspelmath - Word Classes and Parts of SpeechDocument8 pagesM Haspelmath - Word Classes and Parts of SpeechbunburydeluxNo ratings yet
- TOEIC GrammarDocument50 pagesTOEIC Grammarnemo_tehata95% (20)
- Short Grammar CompilationDocument25 pagesShort Grammar CompilationSILVANANo ratings yet
- Nithra Grammar3Document172 pagesNithra Grammar3Nidhi AgarwalNo ratings yet