You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Linear Mixed Effects Modeling Using RDocument13 pagesLinear Mixed Effects Modeling Using RJairo Cardona GiraldoNo ratings yet
- Linear Mixed Effects Modeling Using RDocument13 pagesLinear Mixed Effects Modeling Using RJairo Cardona GiraldoNo ratings yet
- Sample Report For CFA in APADocument6 pagesSample Report For CFA in APANasir Jan KakarNo ratings yet
- Logistic Regression Quiz - Predictive Modeling - Great LearningDocument8 pagesLogistic Regression Quiz - Predictive Modeling - Great LearningRanadip Guha100% (2)
- Dummy Dependent Variables ModelsDocument15 pagesDummy Dependent Variables ModelsBrinda RamNo ratings yet
- Ardl ModelDocument20 pagesArdl ModelMuhammad Nabeel SafdarNo ratings yet
- 2022 Cambridge University Press - Machine LearningDocument352 pages2022 Cambridge University Press - Machine LearningMiguel Angel Pardave BarzolaNo ratings yet
- Introduction To Blogging PDFDocument5 pagesIntroduction To Blogging PDFJairo Cardona Giraldo0% (1)
- Multilevel Models in R Presente and FutureDocument8 pagesMultilevel Models in R Presente and FutureJairo Cardona GiraldoNo ratings yet
- Modelo Multinivel Con RDocument40 pagesModelo Multinivel Con RJairo Cardona GiraldoNo ratings yet
- 7448 26945 1 PBDocument3 pages7448 26945 1 PBSachin ManjalekarNo ratings yet
- Leslie Salt Property Project ReportDocument10 pagesLeslie Salt Property Project ReportAgnish KarNo ratings yet
- Multiple Linear and Non-Linear Regression in Minitab: Lawrence JeromeDocument4 pagesMultiple Linear and Non-Linear Regression in Minitab: Lawrence Jeromeanon_99054501No ratings yet
- Journal of Managment 1 PDFDocument145 pagesJournal of Managment 1 PDFMohamed IrshaNo ratings yet
- Statistics Book ListDocument7 pagesStatistics Book ListAshish GuptaNo ratings yet
- IAPRI Technical Training-Intro To Applied Econometrics 2018 06 25+-+Nicole+MasonDocument29 pagesIAPRI Technical Training-Intro To Applied Econometrics 2018 06 25+-+Nicole+MasonBebeelacNo ratings yet
- Module-I Machine Learning1Document20 pagesModule-I Machine Learning1Ankit KumarNo ratings yet
- Correlation 6th SemDocument11 pagesCorrelation 6th SemANUJ SINGH SIROHINo ratings yet
- L09-An Introduction To Machine LearningDocument65 pagesL09-An Introduction To Machine LearningAlda lumbangaolNo ratings yet
- Tests of NormalityDocument7 pagesTests of NormalityjoedcentenoNo ratings yet
- Ola Data Analysis For Dynamic Price Prediction UsiDocument8 pagesOla Data Analysis For Dynamic Price Prediction UsiAditya RajNo ratings yet
- The MSP Dilemma in IndiaDocument20 pagesThe MSP Dilemma in IndiaHarshit GuptaNo ratings yet
- Module 010 - Correlation AnalysisDocument11 pagesModule 010 - Correlation AnalysisIlovedocumintNo ratings yet
- Post Hoc Tests Familywise Error: Newsom Psy 521/621 Univariate Quantitative Methods, Fall 2020 1Document4 pagesPost Hoc Tests Familywise Error: Newsom Psy 521/621 Univariate Quantitative Methods, Fall 2020 1inayati fitriyahNo ratings yet
- Grafivas Poly Reactores HomogeneosDocument37 pagesGrafivas Poly Reactores HomogeneosDulce Ivanery Gutiérrez LimaNo ratings yet
- Math408 Incourse AssignmentDocument2 pagesMath408 Incourse AssignmentMD. MAJIBUL HASAN IMRANNo ratings yet
- Testul 6Document10 pagesTestul 6PirvuNo ratings yet
- Pearson RDocument15 pagesPearson RJa VilleNo ratings yet
- ECON2280 T4 Stata OutputDocument3 pagesECON2280 T4 Stata Output林嘉明No ratings yet
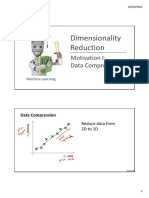
- Dimensionality Reduction: Motivation I: Data CompressionDocument35 pagesDimensionality Reduction: Motivation I: Data CompressionAli NasirNo ratings yet
- Machine Learning AssignmentDocument2 pagesMachine Learning AssignmentUtkarsh guptaNo ratings yet
- 4 Regression AnalysisDocument33 pages4 Regression AnalysishijabNo ratings yet
- Econometric Project - Permanent Income HypothesisDocument9 pagesEconometric Project - Permanent Income HypothesisAdami FajriNo ratings yet
- Sample Thesis Using Regression AnalysisDocument6 pagesSample Thesis Using Regression Analysisgj4m3b5b100% (2)
- Uji HomogenitasDocument2 pagesUji HomogenitasDedi Landani GintingNo ratings yet