You might also like
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- Assignment3 Zhao ZihuiDocument8 pagesAssignment3 Zhao Zihuizhaozhaozizizi2No ratings yet
- CSD Practical MannualDocument35 pagesCSD Practical MannualitsurturnNo ratings yet
- An Introduction to Stochastic Modeling, Student Solutions Manual (e-only)From EverandAn Introduction to Stochastic Modeling, Student Solutions Manual (e-only)No ratings yet
- HW#1 M. TahrawiDocument10 pagesHW#1 M. TahrawiMohanad Al-tahrawiNo ratings yet
- Matrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")From EverandMatrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Rating: 3 out of 5 stars3/5 (4)
- Homework Assignment 3 Homework Assignment 3Document10 pagesHomework Assignment 3 Homework Assignment 3Ido AkovNo ratings yet
- Problemas Bono para Tercer Examen de Estadística - Verano 2012Document8 pagesProblemas Bono para Tercer Examen de Estadística - Verano 2012David Meza CarbajalNo ratings yet
- SvarDocument27 pagesSvarMirza KudumovićNo ratings yet
- ENGR 351 Numerical Methods College of Engineering Southern Illinois University Carbondale Exams Fall 2007 Instructor: Professor L.R. ChevalierDocument13 pagesENGR 351 Numerical Methods College of Engineering Southern Illinois University Carbondale Exams Fall 2007 Instructor: Professor L.R. ChevalierAli O DalkiNo ratings yet
- Se - 1Document23 pagesSe - 1G VarshNo ratings yet
- POQ:quizDocument10 pagesPOQ:quizHarsh ShrinetNo ratings yet
- MATLAB Problem Set 4Document12 pagesMATLAB Problem Set 4xman4243No ratings yet
- PS2 Lab ManualDocument37 pagesPS2 Lab ManualFariha shaikhNo ratings yet
- R Intro 2011Document115 pagesR Intro 2011marijkepauwelsNo ratings yet
- 44 2 Two Way AnovaDocument25 pages44 2 Two Way AnovaEbookcraze100% (1)
- AssignmentsDocument84 pagesAssignmentsPrachi TannaNo ratings yet
- Stat 372 Midterm W14 SolutionDocument4 pagesStat 372 Midterm W14 SolutionAdil AliNo ratings yet
- Sample Solutions For System DynamicsDocument7 pagesSample Solutions For System DynamicsameershamiehNo ratings yet
- Kathmandu School of Engineering University Department of Electrical & Electronics EngineeringDocument10 pagesKathmandu School of Engineering University Department of Electrical & Electronics EngineeringChand BikashNo ratings yet
- Final Matlab ManuaDocument23 pagesFinal Matlab Manuaarindam samantaNo ratings yet
- Stat4006 2022-23 PS3Document3 pagesStat4006 2022-23 PS3resulmamiyev1No ratings yet
- 36-225 - Introduction To Probability Theory - Fall 2014: Solutions For Homework 1Document6 pages36-225 - Introduction To Probability Theory - Fall 2014: Solutions For Homework 1Nick LeeNo ratings yet
- Lab 1Document4 pagesLab 1Deepak MishraNo ratings yet
- Solutions To Selected Problems in Chapter 5: 1 Problem 5.1Document13 pagesSolutions To Selected Problems in Chapter 5: 1 Problem 5.10721673895No ratings yet
- Design For Reliability and Quality: IIT, BombayDocument27 pagesDesign For Reliability and Quality: IIT, Bombaytejap314No ratings yet
- 6 MatLab Tutorial ProblemsDocument27 pages6 MatLab Tutorial Problemsabhijeet834uNo ratings yet
- Documents - MX - Ps Work BooksolutionDocument39 pagesDocuments - MX - Ps Work BooksolutionHaziq MansorNo ratings yet
- NI Tutorial 6477 enDocument10 pagesNI Tutorial 6477 enEngr Nayyer Nayyab MalikNo ratings yet
- Pset 1 SolDocument8 pagesPset 1 SolLJOCNo ratings yet
- Ee 5307 HomeworksDocument15 pagesEe 5307 HomeworksManoj KumarNo ratings yet
- Chapter 6. Power Flow Analysis: First The Generators Are Replaced by EquivalentDocument8 pagesChapter 6. Power Flow Analysis: First The Generators Are Replaced by EquivalentpfumoreropaNo ratings yet
- Lab 5Document5 pagesLab 5Kashif hussainNo ratings yet
- HW #2Document7 pagesHW #2sshanbhagNo ratings yet
- Matlab Code 3Document29 pagesMatlab Code 3kthshlxyzNo ratings yet
- Assumption C.5 States That The Values of The Disturbance Term in The Observations in The Sample Are Generated Independently of Each OtherDocument129 pagesAssumption C.5 States That The Values of The Disturbance Term in The Observations in The Sample Are Generated Independently of Each OtherEddie BarrionuevoNo ratings yet
- Determinant and MatLabDocument14 pagesDeterminant and MatLabAbu Dzar Ar-Rahman Ash-ShidiqNo ratings yet
- Xavier University - Ateneo de Cagayan University College of Engineering Electronics Engineering DepartmentDocument6 pagesXavier University - Ateneo de Cagayan University College of Engineering Electronics Engineering DepartmentMor DepRzNo ratings yet
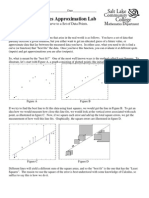
- Math 1050 Project 3 Linear Least Squares ApproximationDocument9 pagesMath 1050 Project 3 Linear Least Squares Approximationapi-233311543No ratings yet
- Matlab 15Document8 pagesMatlab 15Robert RoigNo ratings yet
- Mechanical Vibration Lab ReportDocument7 pagesMechanical Vibration Lab ReportChris NichollsNo ratings yet
- From Unit Root To Cointegration: Putting Economics Into EconometricsDocument23 pagesFrom Unit Root To Cointegration: Putting Economics Into EconometricsfksdajflsadjfskdlaNo ratings yet
- Simple Linear Regression (Solutions To Exercises)Document28 pagesSimple Linear Regression (Solutions To Exercises)blu runner1No ratings yet
- EE132 Lab1 OL Vs CLDocument3 pagesEE132 Lab1 OL Vs CLthinkberry22No ratings yet
- Control System PracticalDocument13 pagesControl System PracticalNITESH KumarNo ratings yet
- Industrial Statistics - A Computer Based Approach With PythonDocument140 pagesIndustrial Statistics - A Computer Based Approach With PythonhtapiaqNo ratings yet
- 10 Regression Analysis in SASDocument12 pages10 Regression Analysis in SASPekanhp OkNo ratings yet
- Solution HW3Document16 pagesSolution HW3mrezzaNo ratings yet
- ENGR 058 (Control Theory) Final: 1) Define The SystemDocument24 pagesENGR 058 (Control Theory) Final: 1) Define The SystemBizzleJohnNo ratings yet
- Econometrics ExamDocument8 pagesEconometrics Examprnh88No ratings yet
- MATLAB Examples - Interpolation and Curve FittingDocument25 pagesMATLAB Examples - Interpolation and Curve FittingQuốc SơnNo ratings yet
- Matlab CodeDocument8 pagesMatlab Codesmit thummarNo ratings yet
- 7 Variance Reduction Techniques: 7.1 Common Random NumbersDocument5 pages7 Variance Reduction Techniques: 7.1 Common Random NumbersjarameliNo ratings yet
- Chapter 8 HW Solution: (A) Position Vs Time. (B) Spatial PathDocument6 pagesChapter 8 HW Solution: (A) Position Vs Time. (B) Spatial Pathrosita61No ratings yet
- Isye4031 Regression and Forecasting Practice Problems 2 Fall 2014Document5 pagesIsye4031 Regression and Forecasting Practice Problems 2 Fall 2014cthunder_1No ratings yet
- Stochastic Solutions ManualDocument144 pagesStochastic Solutions ManualAftab Uddin100% (8)
- Diagnostico de ModelosDocument4 pagesDiagnostico de Modeloskhayman.gpNo ratings yet
- All All: % (A) Construct Side-By-Side Stem-And-Leaf PlotsDocument34 pagesAll All: % (A) Construct Side-By-Side Stem-And-Leaf PlotsJASHWIN GAUTAMNo ratings yet
- The SABR ModelDocument9 pagesThe SABR Modelabhishek210585No ratings yet
- Conc 0.0 0.1 0.2 0.3 100W TN FTN PH STH SPL FLL AWL SPN SPS SPW STW PLWDocument1 pageConc 0.0 0.1 0.2 0.3 100W TN FTN PH STH SPL FLL AWL SPN SPS SPW STW PLW53melmelNo ratings yet
- SNPBC Proceedings PDFDocument376 pagesSNPBC Proceedings PDF53melmelNo ratings yet
- Genotype Environment: DTDPDM DD DRDocument1 pageGenotype Environment: DTDPDM DD DR53melmelNo ratings yet
- SNPBC Proceedings PDFDocument376 pagesSNPBC Proceedings PDF53melmelNo ratings yet
- SNPBC Proceedings PDFDocument376 pagesSNPBC Proceedings PDF53melmelNo ratings yet
- Hort Sci-Sample Paper PDFDocument7 pagesHort Sci-Sample Paper PDF53melmelNo ratings yet
- Fourier Blobs: Subwrld2 Subwrld2Document2 pagesFourier Blobs: Subwrld2 Subwrld253melmelNo ratings yet
- DsagfDocument5 pagesDsagf53melmelNo ratings yet
- Katalog Bonnier BooksDocument45 pagesKatalog Bonnier BooksghitahirataNo ratings yet
- Product Management GemsDocument14 pagesProduct Management GemsVijendra GopaNo ratings yet
- Goal of The Firm PDFDocument4 pagesGoal of The Firm PDFSandyNo ratings yet
- Caso 1 - Tunel Sismico BoluDocument4 pagesCaso 1 - Tunel Sismico BoluCarlos Catalán CórdovaNo ratings yet
- Buffett Wisdom On CorrectionsDocument2 pagesBuffett Wisdom On CorrectionsChrisNo ratings yet
- Copyright IP Law Infringment of CopyrightDocument45 pagesCopyright IP Law Infringment of Copyrightshree2485No ratings yet
- Video Case 1.1 Burke: Learning and Growing Through Marketing ResearchDocument3 pagesVideo Case 1.1 Burke: Learning and Growing Through Marketing ResearchAdeeba 1No ratings yet
- Ruggedbackbone Rx1500 Rx1501Document13 pagesRuggedbackbone Rx1500 Rx1501esilva2021No ratings yet
- Electrical Installation Assignment 2023Document2 pagesElectrical Installation Assignment 2023Monday ChristopherNo ratings yet
- Gears, Splines, and Serrations: Unit 24Document8 pagesGears, Splines, and Serrations: Unit 24Satish Dhandole100% (1)
- Fund For Local Cooperation (FLC) : Application FormDocument9 pagesFund For Local Cooperation (FLC) : Application FormsimbiroNo ratings yet
- Design of Footing (Square FTG.) : M Say, L 3.75Document2 pagesDesign of Footing (Square FTG.) : M Say, L 3.75victoriaNo ratings yet
- Boeing 247 NotesDocument5 pagesBoeing 247 Notesalbloi100% (1)
- Usb - PoliDocument502 pagesUsb - PoliNyl AnerNo ratings yet
- VM PDFDocument4 pagesVM PDFTembre Rueda RaúlNo ratings yet
- DRPL Data Record Output SDP Version 4.17Document143 pagesDRPL Data Record Output SDP Version 4.17rickebvNo ratings yet
- BCK Test Ans (Neha)Document3 pagesBCK Test Ans (Neha)Neha GargNo ratings yet
- EquisetopsidaDocument4 pagesEquisetopsidax456456456xNo ratings yet
- CSFP's Annual Executive Budget 2014Document169 pagesCSFP's Annual Executive Budget 2014rizzelmangilitNo ratings yet
- Forecasting and Demand Management PDFDocument39 pagesForecasting and Demand Management PDFKazi Ajwad AhmedNo ratings yet
- A Study On Mental Health and Quality of Work Life Among Teachers Working in Corporate SchoolsDocument6 pagesA Study On Mental Health and Quality of Work Life Among Teachers Working in Corporate SchoolsKannamma ValliNo ratings yet
- Calio Z: Type Series BookletDocument24 pagesCalio Z: Type Series BookletDan PopescuNo ratings yet
- Brief On Safety Oct 10Document28 pagesBrief On Safety Oct 10Srinivas EnamandramNo ratings yet
- Manual Teclado GK - 340Document24 pagesManual Teclado GK - 340gciamissNo ratings yet
- WCN SyllabusDocument3 pagesWCN SyllabusSeshendra KumarNo ratings yet
- Exit Exam Plan (New)Document2 pagesExit Exam Plan (New)Eleni Semenhi100% (1)
- Feeding Pipe 2'' L 20m: General Plan Al-Sabaeen Pv-Diesel SystemDocument3 pagesFeeding Pipe 2'' L 20m: General Plan Al-Sabaeen Pv-Diesel Systemمحمد الحديNo ratings yet
- Gamesa Wind Turbine Element UpgradesDocument1 pageGamesa Wind Turbine Element Upgradesstanislav uzunchevNo ratings yet
- Table of Contents - YmodDocument4 pagesTable of Contents - YmodDr.Prakher SainiNo ratings yet
- Meeting Protocol and Negotiation Techniques in India and AustraliaDocument3 pagesMeeting Protocol and Negotiation Techniques in India and AustraliaRose4182No ratings yet
- Bulk Material Handling: Practical Guidance for Mechanical EngineersFrom EverandBulk Material Handling: Practical Guidance for Mechanical EngineersRating: 5 out of 5 stars5/5 (1)
- Basic Digital Signal Processing: Butterworths Basic SeriesFrom EverandBasic Digital Signal Processing: Butterworths Basic SeriesRating: 5 out of 5 stars5/5 (1)
- Pressure Vessels: Design, Formulas, Codes, and Interview Questions & Answers ExplainedFrom EverandPressure Vessels: Design, Formulas, Codes, and Interview Questions & Answers ExplainedRating: 5 out of 5 stars5/5 (1)
- Hyperspace: A Scientific Odyssey Through Parallel Universes, Time Warps, and the 10th DimensionFrom EverandHyperspace: A Scientific Odyssey Through Parallel Universes, Time Warps, and the 10th DimensionRating: 4.5 out of 5 stars4.5/5 (3)
- The Laws of Thermodynamics: A Very Short IntroductionFrom EverandThe Laws of Thermodynamics: A Very Short IntroductionRating: 4.5 out of 5 stars4.5/5 (10)
- Mechanical Vibrations and Condition MonitoringFrom EverandMechanical Vibrations and Condition MonitoringRating: 5 out of 5 stars5/5 (1)
- Post Weld Heat Treatment PWHT: Standards, Procedures, Applications, and Interview Q&AFrom EverandPost Weld Heat Treatment PWHT: Standards, Procedures, Applications, and Interview Q&ANo ratings yet
- Vibration Basics and Machine Reliability Simplified : A Practical Guide to Vibration AnalysisFrom EverandVibration Basics and Machine Reliability Simplified : A Practical Guide to Vibration AnalysisRating: 4 out of 5 stars4/5 (2)
- Airplane Flying Handbook: FAA-H-8083-3C (2024)From EverandAirplane Flying Handbook: FAA-H-8083-3C (2024)Rating: 4 out of 5 stars4/5 (12)
- Machinery's Handbook Pocket Companion: Quick Access to Basic Data & More from the 31st EditionFrom EverandMachinery's Handbook Pocket Companion: Quick Access to Basic Data & More from the 31st EditionNo ratings yet
- Pilot's Handbook of Aeronautical Knowledge (2024): FAA-H-8083-25CFrom EverandPilot's Handbook of Aeronautical Knowledge (2024): FAA-H-8083-25CNo ratings yet
- Einstein's Fridge: How the Difference Between Hot and Cold Explains the UniverseFrom EverandEinstein's Fridge: How the Difference Between Hot and Cold Explains the UniverseRating: 4.5 out of 5 stars4.5/5 (51)
- Cyber-Physical Systems: Foundations, Principles and ApplicationsFrom EverandCyber-Physical Systems: Foundations, Principles and ApplicationsHoubing H. SongNo ratings yet
- 1,001 Questions & Answers for the CWI Exam: Welding Metallurgy and Visual Inspection Study GuideFrom Everand1,001 Questions & Answers for the CWI Exam: Welding Metallurgy and Visual Inspection Study GuideRating: 3.5 out of 5 stars3.5/5 (7)
- Electrical (Generator and Electrical Plant): Modern Power Station PracticeFrom EverandElectrical (Generator and Electrical Plant): Modern Power Station PracticeRating: 4 out of 5 stars4/5 (9)
- Laminar Flow Forced Convection in Ducts: A Source Book for Compact Heat Exchanger Analytical DataFrom EverandLaminar Flow Forced Convection in Ducts: A Source Book for Compact Heat Exchanger Analytical DataNo ratings yet
- The Galactic Federation: Discovering the Unknown Can Be Stranger Than FictionFrom EverandThe Galactic Federation: Discovering the Unknown Can Be Stranger Than FictionNo ratings yet
- Practical Hydraulic Systems: Operation and Troubleshooting for Engineers and TechniciansFrom EverandPractical Hydraulic Systems: Operation and Troubleshooting for Engineers and TechniciansRating: 4 out of 5 stars4/5 (8)
- Practical Guides to Testing and Commissioning of Mechanical, Electrical and Plumbing (Mep) InstallationsFrom EverandPractical Guides to Testing and Commissioning of Mechanical, Electrical and Plumbing (Mep) InstallationsRating: 3.5 out of 5 stars3.5/5 (3)
- Safety Theory and Control Technology of High-Speed Train OperationFrom EverandSafety Theory and Control Technology of High-Speed Train OperationRating: 5 out of 5 stars5/5 (2)
- Chasing the Demon: A Secret History of the Quest for the Sound Barrier, and the Band of American Aces Who Conquered ItFrom EverandChasing the Demon: A Secret History of the Quest for the Sound Barrier, and the Band of American Aces Who Conquered ItRating: 4 out of 5 stars4/5 (25)
- Hydraulics and Pneumatics: A Technician's and Engineer's GuideFrom EverandHydraulics and Pneumatics: A Technician's and Engineer's GuideRating: 4 out of 5 stars4/5 (8)
- Gas Turbines: A Handbook of Air, Land and Sea ApplicationsFrom EverandGas Turbines: A Handbook of Air, Land and Sea ApplicationsRating: 4 out of 5 stars4/5 (9)