You might also like
- Matrix Algebra: Determinants, Inverses, EigenvaluesDocument16 pagesMatrix Algebra: Determinants, Inverses, EigenvaluesCiotir MarcelNo ratings yet
- 5.3 Determinants and Cramer's Rule: Unique Solution of A 2 × 2 SystemDocument16 pages5.3 Determinants and Cramer's Rule: Unique Solution of A 2 × 2 SystemParneet PunnNo ratings yet
- Financial Mathematics Course FIN 118 Unit Course 6 Number Unit Applications of Matrices Unit SubjectDocument21 pagesFinancial Mathematics Course FIN 118 Unit Course 6 Number Unit Applications of Matrices Unit Subjectayadi_ezer6795No ratings yet
- Determinants and EigenvalueDocument40 pagesDeterminants and EigenvalueANo ratings yet
- Analysis and Optimization of An Algorithm For Discrete TomographyDocument32 pagesAnalysis and Optimization of An Algorithm For Discrete TomographystructdesignNo ratings yet
- Lecture 1ADocument56 pagesLecture 1ADilruk GallageNo ratings yet
- Properties of Matrices: IndexDocument10 pagesProperties of Matrices: IndexYusok GarciaNo ratings yet
- Ch10 LU Decomposition 21Document34 pagesCh10 LU Decomposition 21AmaniNo ratings yet
- Lecture4 - Linear Algebraic Equations - 11march2024 - NK - v1Document53 pagesLecture4 - Linear Algebraic Equations - 11march2024 - NK - v1yamanfNo ratings yet
- Matrices and Matrix OperationsDocument51 pagesMatrices and Matrix OperationsJesse Dela CruzNo ratings yet
- MatricesDocument47 pagesMatricesAngel Lilly100% (6)
- Matrix and Determinants (2012)Document73 pagesMatrix and Determinants (2012)Angel Chavez100% (2)
- Course 231: Equations of Mathematical Physics: Notes by Chris BlairDocument17 pagesCourse 231: Equations of Mathematical Physics: Notes by Chris Blairhmalrizzo469No ratings yet
- Matrix and Determinants PDFDocument83 pagesMatrix and Determinants PDFMark SyNo ratings yet
- Matrix AlgebraDocument56 pagesMatrix AlgebramuhsafiqNo ratings yet
- Determinants and Matrix InversionDocument17 pagesDeterminants and Matrix InversionVikram SharmaNo ratings yet
- Determinants: 1 The Determinant of A 2 × 2 MatrixDocument17 pagesDeterminants: 1 The Determinant of A 2 × 2 MatrixJuan Ignacio RamirezNo ratings yet
- Chiang - Chapter 5Document10 pagesChiang - Chapter 5Maman LaloNo ratings yet
- Bca s101 MathDocument11 pagesBca s101 MathanilperfectNo ratings yet
- SM FeynmanRulesDocument19 pagesSM FeynmanRulesTe Chuan HuangNo ratings yet
- Apr-2023-Ece-Board-Exam-Preboard HIGHLIGHTDocument8 pagesApr-2023-Ece-Board-Exam-Preboard HIGHLIGHTJanmarc CorpuzNo ratings yet
- Review in Matrix and Determinants PDFDocument89 pagesReview in Matrix and Determinants PDFJan ValentonNo ratings yet
- Grade 11 Math Exam NotesDocument13 pagesGrade 11 Math Exam Notespkgarg_iitkgpNo ratings yet
- Matlab ManualElectromagnetics IDocument99 pagesMatlab ManualElectromagnetics IAnonymous JnvCyu85No ratings yet
- Matlab Manual EMFTDocument99 pagesMatlab Manual EMFTpratheep100% (1)
- Elasticity T01-2Document9 pagesElasticity T01-2Giannis MamalakisNo ratings yet
- Chapter - Ii Finite Difference MethodDocument13 pagesChapter - Ii Finite Difference MethodVirat DesaiNo ratings yet
- Osborn CFTNotesDocument61 pagesOsborn CFTNotesguilleasilvaNo ratings yet
- Cpe-310B Engineering Computation and Simulation: Solving Sets of EquationsDocument46 pagesCpe-310B Engineering Computation and Simulation: Solving Sets of Equationsali ahmedNo ratings yet
- Linear Algebra PDFDocument17 pagesLinear Algebra PDFIoana CîlniceanuNo ratings yet
- Unit 2 Chapter 4determinant Cramers RuleDocument9 pagesUnit 2 Chapter 4determinant Cramers RuleSarah TahiyatNo ratings yet
- 2.1 Determinants by Cofactor ExpansionDocument9 pages2.1 Determinants by Cofactor ExpansionDương KhảiNo ratings yet
- Linear Algebra BookDocument102 pagesLinear Algebra BookDamián TacuriNo ratings yet
- CryptographyDocument20 pagesCryptographyBhaviteja ReddyNo ratings yet
- A Gentle Introduction To Singular-Value Decomposition For Machine LearningDocument14 pagesA Gentle Introduction To Singular-Value Decomposition For Machine LearningVera DamaiantyNo ratings yet
- O Matrix Multiplication Properties of Matrices Commutativity CompositionDocument5 pagesO Matrix Multiplication Properties of Matrices Commutativity Compositionluigi2120No ratings yet
- Ee 701 Lecture NotesDocument261 pagesEe 701 Lecture NotesarafatasgharNo ratings yet
- DDE 2023 MATLAB Fundamentals: MATLAB Programming and GraphicsDocument32 pagesDDE 2023 MATLAB Fundamentals: MATLAB Programming and GraphicsKilon88No ratings yet
- Tensor Math in Finite Element Computer ProgramsDocument6 pagesTensor Math in Finite Element Computer ProgramsRaasheduddin AhmedNo ratings yet
- Biosim3 Linear AlgebraDocument6 pagesBiosim3 Linear AlgebraAditi GuptaNo ratings yet
- Matrix 101Document55 pagesMatrix 101Sarah SullivanNo ratings yet
- Week1 02Document11 pagesWeek1 02Linh LeNo ratings yet
- KIL1005: Numerical Methods For Engineering: Semester 2, Session 2019/2020 7 May 2020Document16 pagesKIL1005: Numerical Methods For Engineering: Semester 2, Session 2019/2020 7 May 2020Safayet AzizNo ratings yet
- Direct Methods To The Solution of Linear Equations SystemsDocument42 pagesDirect Methods To The Solution of Linear Equations SystemspincoNo ratings yet
- LinAlg 2012june11Document14 pagesLinAlg 2012june11RJ DianaNo ratings yet
- Topic 7. Double Grouping. Latin Squares (ST&D 9.10-9.15)Document8 pagesTopic 7. Double Grouping. Latin Squares (ST&D 9.10-9.15)maleticjNo ratings yet
- Matrices, Determinants & Linear SystemsDocument30 pagesMatrices, Determinants & Linear SystemssilviubogaNo ratings yet
- Cem Differential CalculusDocument33 pagesCem Differential CalculusoomganapathiNo ratings yet
- DeterminantDocument14 pagesDeterminantNindya SulistyaniNo ratings yet
- Linear Algebra With Applications Solution ManuelDocument194 pagesLinear Algebra With Applications Solution Manuelvoldemort260367% (3)
- Chapter 1 Topic 4 - Determinants (Matrices)Document35 pagesChapter 1 Topic 4 - Determinants (Matrices)Joan SilvaNo ratings yet
- ch05 1Document27 pagesch05 1vs sNo ratings yet
- Vector Norm: For An N-Dimensional Vector (... ) The Vector Nor MDocument29 pagesVector Norm: For An N-Dimensional Vector (... ) The Vector Nor Mhmalrizzo469No ratings yet
- MTH10007 Notes s1-2015Document208 pagesMTH10007 Notes s1-2015Dylan Ngu Tung Hong0% (1)
- Research ProposalDocument6 pagesResearch ProposalApam BenjaminNo ratings yet
- Multivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Document8 pagesMultivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Apam BenjaminNo ratings yet
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenDocument12 pagesCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminNo ratings yet
- Oxygen Cycle: PlantsDocument3 pagesOxygen Cycle: PlantsApam BenjaminNo ratings yet
- Nitrogen Cycle: Ecological FunctionDocument8 pagesNitrogen Cycle: Ecological FunctionApam BenjaminNo ratings yet
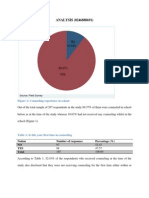
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolDocument8 pagesANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminNo ratings yet
- Lecture8 Module2 Anova 1Document13 pagesLecture8 Module2 Anova 1Apam BenjaminNo ratings yet
- PLM IiDocument3 pagesPLM IiApam BenjaminNo ratings yet
- Lecture6 Module2 Anova 1Document10 pagesLecture6 Module2 Anova 1Apam BenjaminNo ratings yet
- Lecture7 Module2 Anova 1Document10 pagesLecture7 Module2 Anova 1Apam BenjaminNo ratings yet
- Lecture4 Module2 Anova 1Document9 pagesLecture4 Module2 Anova 1Apam BenjaminNo ratings yet
- PLMDocument5 pagesPLMApam BenjaminNo ratings yet
- Lecture5 Module2 Anova 1Document9 pagesLecture5 Module2 Anova 1Apam BenjaminNo ratings yet
- Hosmer On Survival With StataDocument21 pagesHosmer On Survival With StataApam BenjaminNo ratings yet
- Finish WorkDocument116 pagesFinish WorkApam BenjaminNo ratings yet
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaDocument7 pagesRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminNo ratings yet
- ARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaDocument9 pagesARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaApam BenjaminNo ratings yet
- Personal Information: Curriculum VitaeDocument6 pagesPersonal Information: Curriculum VitaeApam BenjaminNo ratings yet
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsDocument14 pagesHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminNo ratings yet
- Trial Questions (PLM)Document3 pagesTrial Questions (PLM)Apam BenjaminNo ratings yet
- A Study On School DropoutsDocument6 pagesA Study On School DropoutsApam BenjaminNo ratings yet
- Ajsms 2 4 348 355Document8 pagesAjsms 2 4 348 355Akolgo PaulinaNo ratings yet
- How To Write A Paper For A Scientific JournalDocument10 pagesHow To Write A Paper For A Scientific JournalApam BenjaminNo ratings yet
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Creating STATA DatasetsDocument4 pagesCreating STATA DatasetsApam BenjaminNo ratings yet
- Banque AtlanticbanDocument1 pageBanque AtlanticbanApam BenjaminNo ratings yet
- l.4. Research QuestionsDocument1 pagel.4. Research QuestionsApam BenjaminNo ratings yet
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteDocument1 pageMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminNo ratings yet
- Asri Stata 2013-FlyerDocument1 pageAsri Stata 2013-FlyerAkolgo PaulinaNo ratings yet
- Project ReportsDocument31 pagesProject ReportsBilal AliNo ratings yet
- The Evolution of Project ManagementDocument5 pagesThe Evolution of Project Managementcrib85No ratings yet
- Computer Book 8 Answer KeyDocument33 pagesComputer Book 8 Answer KeyMa. Dhanice ValdezNo ratings yet
- Lesson14 - DLP15 - While and Do While LoopDocument3 pagesLesson14 - DLP15 - While and Do While LoopAlvaro QuemadoNo ratings yet
- Dean of Industry Interface JDDocument3 pagesDean of Industry Interface JDKrushnasamy SuramaniyanNo ratings yet
- MailEnable System Manual PDFDocument17 pagesMailEnable System Manual PDFDTVNo ratings yet
- Online Dictionaries Today and TomorrowDocument16 pagesOnline Dictionaries Today and TomorrowGuillermo GonzálezNo ratings yet
- Applied Robotics With The SumoBot by Andy LindsayDocument268 pagesApplied Robotics With The SumoBot by Andy LindsayBogus Malogus100% (1)
- Application Note: Optimizing Code Performance and Size For Stellaris® MicrocontrollersDocument21 pagesApplication Note: Optimizing Code Performance and Size For Stellaris® MicrocontrollersVănThịnhNo ratings yet
- Epson FX 890 DatasheetDocument2 pagesEpson FX 890 DatasheetMarcos ZamorioNo ratings yet
- B.Ed M.Ed CET 2024 IBDocument27 pagesB.Ed M.Ed CET 2024 IBDnyaneshwar MaskeNo ratings yet
- 90 Blue Plus ProgrammingDocument2 pages90 Blue Plus ProgrammingDaniel TaradaciucNo ratings yet
- Xii Zoology Reasoning Question AnswersDocument9 pagesXii Zoology Reasoning Question AnswersNisha zehra83% (6)
- Eaton VFDDocument94 pagesEaton VFDsalimskaini1990No ratings yet
- 1 2 3 4 5 6 7 PM583 Di524 8 9 Ta521 Di524 PM583 Ta521 CM597 Ci522Document1 page1 2 3 4 5 6 7 PM583 Di524 8 9 Ta521 Di524 PM583 Ta521 CM597 Ci522mahmoud sheblNo ratings yet
- BRO ASD535-532-531 en PDFDocument6 pagesBRO ASD535-532-531 en PDFArman Ul NasarNo ratings yet
- Vdocuments - MX Rotalign Ultra System ManualDocument31 pagesVdocuments - MX Rotalign Ultra System ManualTanNo ratings yet
- Nemo Outdoor 7.8.2 Release: Technical Bulletin & Release NotesDocument58 pagesNemo Outdoor 7.8.2 Release: Technical Bulletin & Release NotesAnonymous mj4J6ZWEWNo ratings yet
- EJB ArchitectureDocument3 pagesEJB ArchitectureAkrati GuptaNo ratings yet
- Docebo All in On AI Your Guide To Artificial Intelligence in LDDocument20 pagesDocebo All in On AI Your Guide To Artificial Intelligence in LDHager Hamdy100% (1)
- Batch 26 NotesDocument123 pagesBatch 26 NotesSaad ShaikhNo ratings yet
- Big Data and It Governance: Group 1 PGP31102Document34 pagesBig Data and It Governance: Group 1 PGP31102musadhiq_yavarNo ratings yet
- CCTV Fdas Sprinkler Biometrics Access Control Web Development PabxDocument2 pagesCCTV Fdas Sprinkler Biometrics Access Control Web Development PabxKris Larine Orillo-DavisNo ratings yet
- Java Interview Questions - AnswersDocument4 pagesJava Interview Questions - AnswersApurba PanjaNo ratings yet
- Project UMOJA AR/VR Gaming Framework: AR Game Development Wearable Accelerometer Prototype (x3) Marketing and PR FundingDocument1 pageProject UMOJA AR/VR Gaming Framework: AR Game Development Wearable Accelerometer Prototype (x3) Marketing and PR FundingAston WalkerNo ratings yet
- Creating A Database For Creating Cadastre CardsDocument8 pagesCreating A Database For Creating Cadastre CardsCentral Asian StudiesNo ratings yet
- Dealing With SoC Metastability Problems Due To Reset Domain CrossingDocument8 pagesDealing With SoC Metastability Problems Due To Reset Domain CrossingSuraj RaoNo ratings yet
- Makerere University Entry Cutoff Points 2018-19Document58 pagesMakerere University Entry Cutoff Points 2018-19kiryamwibo yenusu94% (16)
- GAMBAS Middleware - GAMBASDocument5 pagesGAMBAS Middleware - GAMBASSURYA PRAKASH PANDEYNo ratings yet
- Block 1Document57 pagesBlock 1riya guptaNo ratings yet
- Catalogo ImportsumaryDocument50 pagesCatalogo ImportsumaryMatthew EnglandNo ratings yet
- Proof of Heaven: A Neurosurgeon's Journey into the AfterlifeFrom EverandProof of Heaven: A Neurosurgeon's Journey into the AfterlifeRating: 3.5 out of 5 stars3.5/5 (165)
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Secrets of the Millionaire Mind: Mastering the Inner Game of WealthFrom EverandSecrets of the Millionaire Mind: Mastering the Inner Game of WealthRating: 4.5 out of 5 stars4.5/5 (197)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Who Tells the Truth?: Collection of Logical Puzzles to Make You ThinkFrom EverandWho Tells the Truth?: Collection of Logical Puzzles to Make You ThinkRating: 5 out of 5 stars5/5 (1)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)
- The Game: Penetrating the Secret Society of Pickup ArtistsFrom EverandThe Game: Penetrating the Secret Society of Pickup ArtistsRating: 4 out of 5 stars4/5 (131)