You might also like
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Oxygen Cycle: PlantsDocument3 pagesOxygen Cycle: PlantsApam BenjaminNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Nitrogen Cycle: Ecological FunctionDocument8 pagesNitrogen Cycle: Ecological FunctionApam BenjaminNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Research ProposalDocument6 pagesResearch ProposalApam BenjaminNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
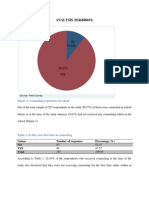
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolDocument8 pagesANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenDocument12 pagesCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminNo ratings yet
- Lecture5 Module2 Anova 1Document9 pagesLecture5 Module2 Anova 1Apam BenjaminNo ratings yet
- Multivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Document8 pagesMultivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Apam BenjaminNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Finish WorkDocument116 pagesFinish WorkApam BenjaminNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- PLMDocument5 pagesPLMApam BenjaminNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Lecture6 Module2 Anova 1Document10 pagesLecture6 Module2 Anova 1Apam BenjaminNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Lecture4 Module2 Anova 1Document9 pagesLecture4 Module2 Anova 1Apam BenjaminNo ratings yet
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsDocument14 pagesHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Comparison of Chi-Square and Likelihood Ratio Chi-Square Tests: Power of TestDocument3 pagesComparison of Chi-Square and Likelihood Ratio Chi-Square Tests: Power of TestApam BenjaminNo ratings yet
- l.4. Research QuestionsDocument1 pagel.4. Research QuestionsApam BenjaminNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Personal Information: Curriculum VitaeDocument6 pagesPersonal Information: Curriculum VitaeApam BenjaminNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- A Study On School DropoutsDocument6 pagesA Study On School DropoutsApam BenjaminNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaDocument7 pagesRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Project ReportsDocument31 pagesProject ReportsBilal AliNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteDocument1 pageMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Time Series Lecture NotesDocument97 pagesTime Series Lecture NotesApam BenjaminNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Evaluating The Effects of The National Health Insurance Act in Ghana: BaselineDocument75 pagesEvaluating The Effects of The National Health Insurance Act in Ghana: BaselineApam BenjaminNo ratings yet
- Tutorials in Statistics - Chapter 4 NewDocument11 pagesTutorials in Statistics - Chapter 4 NewApam BenjaminNo ratings yet
- Trapezoidal Rule EditedDocument3 pagesTrapezoidal Rule EditedApam BenjaminNo ratings yet
- Content Design Portfolio Curious Writer 1643776943Document28 pagesContent Design Portfolio Curious Writer 1643776943AbrilNo ratings yet
- Group 3 - AppendicesDocument82 pagesGroup 3 - AppendicesChianti Gaming09No ratings yet
- Credit ManagementDocument9 pagesCredit ManagementJayshreeDashaniNo ratings yet
- CHRA Global OnlineDocument6 pagesCHRA Global Onlinezaidi100% (1)
- Ordered Synopsis CenthilDocument14 pagesOrdered Synopsis CenthilageesNo ratings yet
- Conceptual FramewrokDocument4 pagesConceptual FramewrokShekaina Faith Cuizon Lozada100% (1)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Age 12 Multigroup Ethnic Identity MeasureDocument4 pagesAge 12 Multigroup Ethnic Identity MeasureRamz E AgehiNo ratings yet
- EFDA - Guidelines For IVD Registration RequirementsDocument56 pagesEFDA - Guidelines For IVD Registration RequirementsdawitNo ratings yet
- Minat Baca Siswa Kelas Rendah Dalam Pelaksanaan Literasi Sekolah Di SD Islam Al Azhar 34 Makassar Hasninda DamrinDocument11 pagesMinat Baca Siswa Kelas Rendah Dalam Pelaksanaan Literasi Sekolah Di SD Islam Al Azhar 34 Makassar Hasninda DamrinMariaUlfaNo ratings yet
- Abstract and Intro Acid-Base TitrationsDocument2 pagesAbstract and Intro Acid-Base TitrationsZhyra Alexis Anda0% (1)
- POGIL Presentation 9th GCC Medical Education ConferenceDocument16 pagesPOGIL Presentation 9th GCC Medical Education ConferencedecgaynorNo ratings yet
- Lampiran 5Document229 pagesLampiran 5Riza WidyaNo ratings yet
- PRISMA StatementDocument7 pagesPRISMA StatementJuan Camilo MontenegroNo ratings yet
- Adversity QuotientDocument22 pagesAdversity QuotientKimson JhunNo ratings yet
- TaaassskkkDocument25 pagesTaaassskkkSita Kartina Archuleta0% (4)
- Application of Game Theory in Organisational Conflict Resolution: The Case of NegotiationDocument6 pagesApplication of Game Theory in Organisational Conflict Resolution: The Case of NegotiationMiguel MazaNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Assignment Brief Unit 47 QCFDocument14 pagesAssignment Brief Unit 47 QCFAlamzeb KhanNo ratings yet
- Detailed Lesson Plan: (Abm - Bm11Pad-Iig-2)Document15 pagesDetailed Lesson Plan: (Abm - Bm11Pad-Iig-2)Princess Duqueza100% (1)
- Paul A. Longley, Michael F. Goodchild, David J. Maguire, David W. Rhind-Geographic Information Systems and Science-Wiley (2005)Document539 pagesPaul A. Longley, Michael F. Goodchild, David J. Maguire, David W. Rhind-Geographic Information Systems and Science-Wiley (2005)Alda0% (1)
- It's Not Luck (1994) Is A Business: Novel Manufacturer Eliyahu M. GoldrattDocument2 pagesIt's Not Luck (1994) Is A Business: Novel Manufacturer Eliyahu M. Goldrattpoish1No ratings yet
- Awareness and Perception of HousewivesDocument9 pagesAwareness and Perception of HousewivesChrislyn CalinggalNo ratings yet
- Research Sb19Document30 pagesResearch Sb19Henry LopezNo ratings yet
- Comparison of PubMed, Scopus, Web of Science, and Google Scholar - Strengths and WeaknessesDocument5 pagesComparison of PubMed, Scopus, Web of Science, and Google Scholar - Strengths and WeaknessesMostafa AbdelrahmanNo ratings yet
- The Impact of Ownership Structure On Corporate Debt Policy: A Time-Series Cross-Sectional AnalysisDocument14 pagesThe Impact of Ownership Structure On Corporate Debt Policy: A Time-Series Cross-Sectional Analysisyudhi prasetiyoNo ratings yet
- Mat 2377 Final 2011Document12 pagesMat 2377 Final 2011David LinNo ratings yet
- Delta MethodDocument11 pagesDelta MethodRaja Fawad ZafarNo ratings yet
- Article-8066-Coressponding author-AdiFRDocument7 pagesArticle-8066-Coressponding author-AdiFRafran ramadhanNo ratings yet
- Micro OB Syllabus - 18-20Document2 pagesMicro OB Syllabus - 18-20Abhishek rajNo ratings yet
- Art Vs NatureDocument12 pagesArt Vs NatureAgnes Enya LorraineNo ratings yet