You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- HLD - PM08Document28 pagesHLD - PM08Sravya ReddyNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- HLD - CS07Document27 pagesHLD - CS07Sravya ReddyNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- HLD - PM06Document27 pagesHLD - PM06Sravya ReddyNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Difference Between Layout and Depth in Ab InitioDocument1 pageDifference Between Layout and Depth in Ab InitioSravya ReddyNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- T Des Es ResumeDocument2 pagesT Des Es ResumeSravya ReddyNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Ab Initio - Parameter Kung Fu: Remediator CommentsDocument2 pagesAb Initio - Parameter Kung Fu: Remediator CommentsSravya ReddyNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Time Saving TipsDocument2 pagesTime Saving TipsSravya ReddyNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- A FundamentalsDocument16 pagesA Fundamentalsapi-3706175No ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Comm 3 Tips For Public SpeakingDocument1 pageComm 3 Tips For Public SpeakingSravya ReddyNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- How to reach the top in lifeDocument3 pagesHow to reach the top in lifeShriram GundaNo ratings yet
- Sequential DatawarehousingDocument25 pagesSequential DatawarehousingSravya ReddyNo ratings yet
- Nex in SequenceDocument1 pageNex in SequenceSravya ReddyNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Multiple Rows To Single Row in Informatica: Summary: Full ArticleDocument1 pageMultiple Rows To Single Row in Informatica: Summary: Full ArticleSravya ReddyNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- What Is A Sandbox in Ab Initio?Document1 pageWhat Is A Sandbox in Ab Initio?Sravya ReddyNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- ErrorsDocument1 pageErrorsSravya ReddyNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Flat File With NULLS in The OutputDocument1 pageFlat File With NULLS in The OutputSravya ReddyNo ratings yet
- Ab Initio - Lookups On Oracle Database: Summary: Full ArticleDocument1 pageAb Initio - Lookups On Oracle Database: Summary: Full ArticleSravya ReddyNo ratings yet
- Multiple Rows To Single Row in Informatica: Summary: Full ArticleDocument1 pageMultiple Rows To Single Row in Informatica: Summary: Full ArticleSravya ReddyNo ratings yet
- Rows Per Commit Utility Mode MSSQLDocument1 pageRows Per Commit Utility Mode MSSQLSravya ReddyNo ratings yet
- The Ascii and Ebcdic TablesDocument4 pagesThe Ascii and Ebcdic TablesSravya ReddyNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Surrogate Key1Document3 pagesSurrogate Key1Sravya ReddyNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Ab Initio - Lookups On Oracle Database: Summary: Full ArticleDocument1 pageAb Initio - Lookups On Oracle Database: Summary: Full ArticleSravya ReddyNo ratings yet
- Reformat Before Table Load: Necessary for StabilityDocument1 pageReformat Before Table Load: Necessary for StabilitySravya ReddyNo ratings yet
- Stop AbortDocument2 pagesStop AbortSravya ReddyNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- ComponentsDocument11 pagesComponentsSravya ReddyNo ratings yet
- Ab Initio Productivity Features Vs Informatica: SummaryDocument2 pagesAb Initio Productivity Features Vs Informatica: SummarySravya ReddyNo ratings yet
- Tune A Graph Against Excessive CPU Consumption in Ab InitioDocument1 pageTune A Graph Against Excessive CPU Consumption in Ab InitioSravya ReddyNo ratings yet
- Key-Change Vs Key-Specifier in Ab InitioDocument1 pageKey-Change Vs Key-Specifier in Ab InitioSravya ReddyNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- AB - JOB Variable in Ab InitioDocument1 pageAB - JOB Variable in Ab InitioSravya ReddyNo ratings yet
- S5-155U CPU 948 Programming GuideDocument548 pagesS5-155U CPU 948 Programming GuideCristian CanalesNo ratings yet
- JdbcquestionsDocument73 pagesJdbcquestionssubhabirajdarNo ratings yet
- Online Billing and Invoice System SynopsisDocument3 pagesOnline Billing and Invoice System SynopsisVAIBHAVI VISHENo ratings yet
- DecommissioningDocument10 pagesDecommissioningKapil KulkarniNo ratings yet
- Oracle Install Base ImplementationDocument34 pagesOracle Install Base ImplementationPreethi KishoreNo ratings yet
- Cassandra Brass Tacks Q&ADocument4 pagesCassandra Brass Tacks Q&AVenkatesh BabuNo ratings yet
- VDCA550 Exam PreparationDocument57 pagesVDCA550 Exam Preparationshyco007No ratings yet
- CS Practicals 11-17Document11 pagesCS Practicals 11-17ankushrio83006No ratings yet
- 7 Layer OSI Model ExplainedDocument34 pages7 Layer OSI Model ExplainedDivya GuptaNo ratings yet
- MesomaticDocument37 pagesMesomaticaswin0% (4)
- What is a File SystemDocument23 pagesWhat is a File Systemdemissie ejoNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Legacy VS Apps Interface DesignDocument3 pagesLegacy VS Apps Interface DesignashibekNo ratings yet
- Chapter 2: Data Mapping and Exchange: VisitDocument99 pagesChapter 2: Data Mapping and Exchange: VisitDejenie DereseNo ratings yet
- Codigo Fecha SerieDocument23 pagesCodigo Fecha Serieomarciito ruaNo ratings yet
- Ts 72 Admin enDocument302 pagesTs 72 Admin enGautam PopliNo ratings yet
- PassLeader 300-375 Exam Dumps (21-30)Document4 pagesPassLeader 300-375 Exam Dumps (21-30)Janek PodwalaNo ratings yet
- Q Rep DB2 OracleDocument34 pagesQ Rep DB2 OracleRamchandra RaikarNo ratings yet
- Microprocessor and Microcontrroller Module 1 - Calicut UniversityDocument32 pagesMicroprocessor and Microcontrroller Module 1 - Calicut UniversityAshwin GopinathNo ratings yet
- Use SQLMAP SQL Injection To Hack A Website and Database in Kali LinuxDocument21 pagesUse SQLMAP SQL Injection To Hack A Website and Database in Kali LinuxShahid Rahman100% (1)
- 8085 1Document17 pages8085 1Amar GhogaleNo ratings yet
- Oltp vs. Olap and How Do They Connect To SAP?: Last Updated On January 21, 2020Document12 pagesOltp vs. Olap and How Do They Connect To SAP?: Last Updated On January 21, 2020FurqanNo ratings yet
- PHP: Hypertext Preprocessor: Correct Answer!Document6 pagesPHP: Hypertext Preprocessor: Correct Answer!jasminaNo ratings yet
- Nutanix Premium NCP-MCI-6 5 30Document11 pagesNutanix Premium NCP-MCI-6 5 30Nilesh GaikwadNo ratings yet
- All MongoDb CommandsDocument4 pagesAll MongoDb CommandsTobiNo ratings yet
- SAP Directory Structure for UNIX SystemsDocument10 pagesSAP Directory Structure for UNIX SystemsDevender5194No ratings yet
- Lesson 6 - Hibernate Queries and RelationshipDocument70 pagesLesson 6 - Hibernate Queries and RelationshipNaveen KumarNo ratings yet
- Geeksforgeeks Org C Programming LanguageDocument2 pagesGeeksforgeeks Org C Programming LanguageTest accNo ratings yet
- Accounting Information Systems 13th Edition Romney Test BankDocument25 pagesAccounting Information Systems 13th Edition Romney Test Bankrobingomezwqfbdcaksn100% (32)
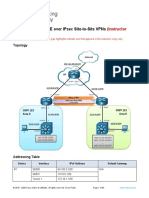
- 16.1.4 Lab - Implement GRE Over IPsec Site-To-Site VPNs - ILMDocument33 pages16.1.4 Lab - Implement GRE Over IPsec Site-To-Site VPNs - ILMAndrei Petru PârvNo ratings yet
- QnapDocument5 pagesQnapadokamNo ratings yet
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Monitored: Business and Surveillance in a Time of Big DataFrom EverandMonitored: Business and Surveillance in a Time of Big DataRating: 4 out of 5 stars4/5 (1)