You might also like
- Low Complexity Multi-Exposure Image FusionDocument15 pagesLow Complexity Multi-Exposure Image FusionSriram AtronixNo ratings yet
- Adaptive Mixed Norm Optical Flow Estimation Vcip 2005Document8 pagesAdaptive Mixed Norm Optical Flow Estimation Vcip 2005ShadowNo ratings yet
- Wavelet Enhancement of Cloud-Related Shadow Areas in Single Landsat Satellite ImageryDocument6 pagesWavelet Enhancement of Cloud-Related Shadow Areas in Single Landsat Satellite ImagerySrikanth PatilNo ratings yet
- Camera Models and Image Processing TechniquesDocument38 pagesCamera Models and Image Processing TechniquesElisa PopNo ratings yet
- InTech-High Speed Architecure Based On Fpga For A Stereo Vision AlgorithmDocument18 pagesInTech-High Speed Architecure Based On Fpga For A Stereo Vision AlgorithmdvtruongsonNo ratings yet
- Multi-Focus Image Fusion For Extended Depth of Field: Wisarut Chantara and Yo-Sung HoDocument4 pagesMulti-Focus Image Fusion For Extended Depth of Field: Wisarut Chantara and Yo-Sung Hofiza ashfaqNo ratings yet
- Hyper-spectra Image denoising with bilateral filterDocument7 pagesHyper-spectra Image denoising with bilateral filterHonghong PengNo ratings yet
- DWT-DCT Iris Recognition Using SOM Neural NetworkDocument7 pagesDWT-DCT Iris Recognition Using SOM Neural Networkprofessor_manojNo ratings yet
- International Refereed Journal of Engineering and Science (IRJES)Document8 pagesInternational Refereed Journal of Engineering and Science (IRJES)www.irjes.comNo ratings yet
- A Novel Statistical Fusion Rule For Image Fusion and Its Comparison in Non Subsampled Contourlet Transform Domain and Wavelet DomainDocument19 pagesA Novel Statistical Fusion Rule For Image Fusion and Its Comparison in Non Subsampled Contourlet Transform Domain and Wavelet DomainIJMAJournalNo ratings yet
- An Efficient Image Denoising Method Using SVM ClassificationDocument5 pagesAn Efficient Image Denoising Method Using SVM ClassificationGRENZE Scientific SocietyNo ratings yet
- Wavelet PDFDocument5 pagesWavelet PDFvlsivirusNo ratings yet
- Adaptive Filtering in Astronomical Image Processing: Very Deep Convolutional Networks For Large-Scale Image RecognitionDocument6 pagesAdaptive Filtering in Astronomical Image Processing: Very Deep Convolutional Networks For Large-Scale Image RecognitionKartikeya ChauhanNo ratings yet
- High Accuracy Wave Filed Reconstruction Decoupled Inverse Imaging With Sparse Modelig of Phase and AmplitudeDocument11 pagesHigh Accuracy Wave Filed Reconstruction Decoupled Inverse Imaging With Sparse Modelig of Phase and AmplitudeAsim AsrarNo ratings yet
- Calibration For Increased Accuracy of The Range Imaging Camera SwissrangerDocument6 pagesCalibration For Increased Accuracy of The Range Imaging Camera SwissrangerEgemet SatisNo ratings yet
- Sliced Ridgelet Transform For Image DenoisingDocument5 pagesSliced Ridgelet Transform For Image DenoisingInternational Organization of Scientific Research (IOSR)No ratings yet
- Rescue AsdDocument8 pagesRescue Asdkoti_naidu69No ratings yet
- Object Detection and Shadow Removal From Video StreamDocument10 pagesObject Detection and Shadow Removal From Video StreamPaolo PinoNo ratings yet
- Denoising Process Based On Arbitrarily Shaped WindowsDocument7 pagesDenoising Process Based On Arbitrarily Shaped WindowsAI Coordinator - CSC JournalsNo ratings yet
- Image Processing DFT, DCT and DWTDocument12 pagesImage Processing DFT, DCT and DWTMoe LokNo ratings yet
- Different Image Fusion Techniques - A Critical ReviewDocument4 pagesDifferent Image Fusion Techniques - A Critical ReviewIJMERNo ratings yet
- An Efficient Auto Focus Method For Digital Still CameraDocument12 pagesAn Efficient Auto Focus Method For Digital Still CameraBhaskar RaoNo ratings yet
- Image Scaling AlgorithmsDocument69 pagesImage Scaling AlgorithmsSumeet SauravNo ratings yet
- (Yu2018) Haze Removal Algorithm Using Color Attenuation Prior and Guided FilterDocument5 pages(Yu2018) Haze Removal Algorithm Using Color Attenuation Prior and Guided FilterK SavitriNo ratings yet
- Generating Arbitrary Laser Beam Shapes Through Phase-Mapped Designed Beam SplittingDocument12 pagesGenerating Arbitrary Laser Beam Shapes Through Phase-Mapped Designed Beam SplittingTristan Valenzuela SalazarNo ratings yet
- Image Registration For AgriculturDocument7 pagesImage Registration For AgriculturImranNo ratings yet
- Implementing a waveform recovery algorithm on FPGAs using a zonal method (HudginDocument10 pagesImplementing a waveform recovery algorithm on FPGAs using a zonal method (Hudginmanuales1000No ratings yet
- Lab ManualDocument13 pagesLab ManualcrpriyankhaaNo ratings yet
- Rectilinear Texture Warping For Fast Adaptive Shadow MappingDocument3 pagesRectilinear Texture Warping For Fast Adaptive Shadow Mappingm_hasani9702No ratings yet
- Block-Matching Sub-Pixel Motion Estimation From Noisy, Under-Sampled Frames - An Empirical Performance EvaluationDocument10 pagesBlock-Matching Sub-Pixel Motion Estimation From Noisy, Under-Sampled Frames - An Empirical Performance Evaluationjuan.vesaNo ratings yet
- Image Processing SeminarDocument48 pagesImage Processing SeminarAnkur SinghNo ratings yet
- CCR Clustering and Collaborative RepresentationDocument93 pagesCCR Clustering and Collaborative Representationg_31682896No ratings yet
- Detecting obstacles in foggy environments using dark channel prior and image enhancementDocument4 pagesDetecting obstacles in foggy environments using dark channel prior and image enhancementBalagovind BaluNo ratings yet
- Radar Tomography For The Generation of Three-Dimensional ImagesDocument7 pagesRadar Tomography For The Generation of Three-Dimensional ImagesMuhammad RosliNo ratings yet
- Performance Enhancement of Video Compression Algorithms With SIMDDocument80 pagesPerformance Enhancement of Video Compression Algorithms With SIMDCarlosNo ratings yet
- Image Scaling AlgorithmsDocument70 pagesImage Scaling AlgorithmsSumeet SauravNo ratings yet
- Multi-Source Image Registration Based On Log-Polar Coordinates and Extension Phase Correlation PDFDocument7 pagesMulti-Source Image Registration Based On Log-Polar Coordinates and Extension Phase Correlation PDFivy_publisherNo ratings yet
- Phase-Based Iris Recognition Using Fourier TransformsDocument10 pagesPhase-Based Iris Recognition Using Fourier TransformsSudipto MandalNo ratings yet
- GW3rdchp2prbs PDFDocument4 pagesGW3rdchp2prbs PDFOsama EhsanNo ratings yet
- 15arspc Submission 109Document9 pages15arspc Submission 109reneebartoloNo ratings yet
- Reconstruction of Low Light Images Using The Vector Wiener FilterDocument22 pagesReconstruction of Low Light Images Using The Vector Wiener Filterasdf344No ratings yet
- Palm Vein Verification Using SIFT Keypoint MatchingDocument10 pagesPalm Vein Verification Using SIFT Keypoint MatchingGautham ShettyNo ratings yet
- Focus Set Based Reconstruction of Micro-ObjectsDocument4 pagesFocus Set Based Reconstruction of Micro-ObjectsJan WedekindNo ratings yet
- A New Pixel-Wise Mask For Watermarking: Corina NafornitaDocument8 pagesA New Pixel-Wise Mask For Watermarking: Corina NafornitaSairam SaiNo ratings yet
- Directional Light MapsDocument9 pagesDirectional Light MapsAndrei BadilaNo ratings yet
- Higher Spatial Resolution Integral PhotographyDocument10 pagesHigher Spatial Resolution Integral Photography劉永日樂No ratings yet
- Image Restoration Part 1Document5 pagesImage Restoration Part 1Nishi YadavNo ratings yet
- Aerial Image Simulation For Partial Coherent System With Programming Development in MATLABDocument7 pagesAerial Image Simulation For Partial Coherent System With Programming Development in MATLABocb81766No ratings yet
- 3D Visualisation - Castanie Et Al - 2005 - First BreakDocument4 pages3D Visualisation - Castanie Et Al - 2005 - First Breakmsh0004No ratings yet
- An Improved Edge Detection in SAR Color ImagesDocument5 pagesAn Improved Edge Detection in SAR Color ImagesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- SPIE Lankoande-2005Document12 pagesSPIE Lankoande-2005nNo ratings yet
- Recovering High Dynamic Range Radiance Maps From PhotographsDocument10 pagesRecovering High Dynamic Range Radiance Maps From PhotographsAkshay PhadkeNo ratings yet
- Ractal Image Compression Using Uadtree Decomposition and Huffman CodingDocument6 pagesRactal Image Compression Using Uadtree Decomposition and Huffman CodingSylvain KamdemNo ratings yet
- Yr2 Computing Ray Tracer FinalDocument8 pagesYr2 Computing Ray Tracer Finalasdg asdgNo ratings yet
- B.Tech-Information Technology Sixth Semester Digital Image Processing (IT 603) NotesDocument19 pagesB.Tech-Information Technology Sixth Semester Digital Image Processing (IT 603) NotesnannurahNo ratings yet
- Topics On Optical and Digital Image Processing Using Holography and Speckle TechniquesFrom EverandTopics On Optical and Digital Image Processing Using Holography and Speckle TechniquesNo ratings yet
- Computer Processing of Remotely-Sensed Images: An IntroductionFrom EverandComputer Processing of Remotely-Sensed Images: An IntroductionNo ratings yet
- LicenseDocument6 pagesLicensemerrysun22No ratings yet
- LicenseffDocument1 pageLicenseffDaniela CotomanNo ratings yet
- Ceramic Capacitor Products: AVX Surface MountDocument109 pagesCeramic Capacitor Products: AVX Surface Mountnpadma_6No ratings yet
- Cxo 3225Document1 pageCxo 3225npadma_6No ratings yet
- (SPIE2013 8704-8) High-Performance and Long-Range Cooled IR Technologies...Document14 pages(SPIE2013 8704-8) High-Performance and Long-Range Cooled IR Technologies...npadma_6No ratings yet
- 3224 - 4 MM SMD Trimpot Trimming Potentiometer: FeaturesDocument2 pages3224 - 4 MM SMD Trimpot Trimming Potentiometer: Featuresnpadma_6No ratings yet
- CCD 1Document4 pagesCCD 1npadma_6No ratings yet
- ReadmeDocument1 pageReadmeasdflkj_No ratings yet
- W Elcom e Guest: Select Date Select EditionDocument1 pageW Elcom e Guest: Select Date Select Editionnpadma_6No ratings yet
- Ceramic Capacitor Products: AVX Surface MountDocument109 pagesCeramic Capacitor Products: AVX Surface Mountnpadma_6No ratings yet
- 3224 - 4 MM SMD Trimpot Trimming Potentiometer: FeaturesDocument2 pages3224 - 4 MM SMD Trimpot Trimming Potentiometer: Featuresnpadma_6No ratings yet
- ADuM3440 3441 3442Document24 pagesADuM3440 3441 3442npadma_6No ratings yet
- AD9648Document44 pagesAD9648npadma_6No ratings yet
- AD9650Document44 pagesAD9650npadma_6No ratings yet
- Digital Signal ProcessorsDocument6 pagesDigital Signal ProcessorsVenkatesh SubramanyaNo ratings yet
- AD9648Document44 pagesAD9648npadma_6No ratings yet
- Ciarp2011 Submission 85Document8 pagesCiarp2011 Submission 85Daniela BonillaNo ratings yet
- AD9648Document44 pagesAD9648npadma_6No ratings yet
- Nano 51pinDocument9 pagesNano 51pinnpadma_6No ratings yet
- Matlab Untuk StatistikaDocument33 pagesMatlab Untuk StatistikaprotogiziNo ratings yet
- Conn PricingDocument1 pageConn Pricingnpadma_6No ratings yet
- Image Processing Basics Using Matlab (C) M. Thaler (Image Processing Basics Using Matlab (C) M PDFDocument4 pagesImage Processing Basics Using Matlab (C) M. Thaler (Image Processing Basics Using Matlab (C) M PDFDaladier LópezNo ratings yet
- TTDocument68 pagesTTnpadma_6No ratings yet
- Image Processing Basics Using Matlab (C) M. Thaler (Image Processing Basics Using Matlab (C) M PDFDocument4 pagesImage Processing Basics Using Matlab (C) M. Thaler (Image Processing Basics Using Matlab (C) M PDFDaladier LópezNo ratings yet
- DC/DC C 28 V I: Onverters OLT NputDocument21 pagesDC/DC C 28 V I: Onverters OLT Nputnpadma_6No ratings yet
- AD9248Document48 pagesAD9248npadma_6No ratings yet
- 3CanonDSLRs ATT09Document9 pages3CanonDSLRs ATT09npadma_6No ratings yet
- DC/DC C 28 V I: Onverters OLT NputDocument21 pagesDC/DC C 28 V I: Onverters OLT Nputnpadma_6No ratings yet
- AD9244Document36 pagesAD9244npadma_6No ratings yet
- Ceramic Terminal BlocksDocument1 pageCeramic Terminal BlockselijbbNo ratings yet
- Roebuck 1942Document12 pagesRoebuck 1942Imam Saja DechNo ratings yet
- Using Electricity SafelyDocument1 pageUsing Electricity SafelymariaNo ratings yet
- ApaveMare Training 2013Document41 pagesApaveMare Training 2013fbarakaNo ratings yet
- 2009 Energy Storage-U.S. Department of EnergyDocument380 pages2009 Energy Storage-U.S. Department of EnergydiwhiteNo ratings yet
- Unit Conversion Heat TransferDocument5 pagesUnit Conversion Heat TransferFamela GadNo ratings yet
- 2014 Solder Joint ReliabilityDocument18 pages2014 Solder Joint ReliabilitychoprahariNo ratings yet
- XHLE Long Coupled Centrifugal Pump EnglishDocument8 pagesXHLE Long Coupled Centrifugal Pump Englishgagi1994brahimNo ratings yet
- Bottom Ash HopperDocument8 pagesBottom Ash HopperBhargav ChaudhariNo ratings yet
- Excellent Hex Key Wrench: English VersionDocument54 pagesExcellent Hex Key Wrench: English Versionmg pyaeNo ratings yet
- 6GK52160BA002AA3 Datasheet en PDFDocument6 pages6GK52160BA002AA3 Datasheet en PDFgrace lordiNo ratings yet
- Oksd Icwh 1993 RoisumDocument40 pagesOksd Icwh 1993 RoisumKamalam CloudsoftNo ratings yet
- NUSTian Final July SeptDocument36 pagesNUSTian Final July SeptAdeel KhanNo ratings yet
- Department of Mechanical Engineering, Uet Lahore Refrigeration and Air Conditioning LaboratoryDocument7 pagesDepartment of Mechanical Engineering, Uet Lahore Refrigeration and Air Conditioning LaboratoryTauQeer ShahNo ratings yet
- IEC CsODESDocument2 pagesIEC CsODESArun KumarNo ratings yet
- Smarter and Safer: Cordless Endodontic HandpieceDocument2 pagesSmarter and Safer: Cordless Endodontic Handpiecesonu1296No ratings yet
- 02 - Critical Customers Complains enDocument8 pages02 - Critical Customers Complains enKJDNKJZEF100% (1)
- Duet CE-3301 Geotechnical Engineering - IDocument37 pagesDuet CE-3301 Geotechnical Engineering - IShekh Muhsen Uddin AhmedNo ratings yet
- Please Note That This Form Details Exploration and Production Api Titles Available For OrderDocument8 pagesPlease Note That This Form Details Exploration and Production Api Titles Available For Orderhaotran68No ratings yet
- Operating Instructions, FormulaDocument35 pagesOperating Instructions, FormulaandymulyonoNo ratings yet
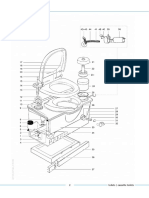
- Cassette toilet spare parts guide for models C2, C3 and C4Document21 pagesCassette toilet spare parts guide for models C2, C3 and C4georgedragosNo ratings yet
- Dimensions of Physical Quantities DensityDocument100 pagesDimensions of Physical Quantities DensityGerman Rincon UrregoNo ratings yet
- End All Red Overdrive: Controls and FeaturesDocument6 pagesEnd All Red Overdrive: Controls and FeaturesBepe uptp5aNo ratings yet
- SHB 2503-3703 en 1000081433Document192 pagesSHB 2503-3703 en 1000081433Alberto100% (1)
- 06 HVAC Plumbing PDFDocument727 pages06 HVAC Plumbing PDFTamNo ratings yet
- Smart Access 1105Document12 pagesSmart Access 1105Gerson Freire De Amorim FilhoNo ratings yet
- J 1 B 1211 CCDDocument3 pagesJ 1 B 1211 CCDRegion 51No ratings yet
- Developing Recycled PET Fiber for Concrete ReinforcementDocument8 pagesDeveloping Recycled PET Fiber for Concrete ReinforcementJunaid Ahmad100% (1)
- Vehicle Air Conditioning (VAC) : System Operation and The Refrigerant CycleDocument49 pagesVehicle Air Conditioning (VAC) : System Operation and The Refrigerant CycleVarun RaizadaNo ratings yet
- Manual Service Aoc - E943fwskDocument51 pagesManual Service Aoc - E943fwskEduardo BentoNo ratings yet