You might also like
- Fuente Segura Hose 10 Edicion InglesDocument470 pagesFuente Segura Hose 10 Edicion InglesAnonymous voPTZ0r00100% (2)
- C D SeriesDocument16 pagesC D SeriesAlejandro AguirreNo ratings yet
- Idl 001-09 Idler CatalogDocument68 pagesIdl 001-09 Idler Catalogpramuda sirodzNo ratings yet
- Manual PartsDocument125 pagesManual PartsAlejandro AguirreNo ratings yet
- 1993 - Bernhardt - Shape Factors of BagasseDocument4 pages1993 - Bernhardt - Shape Factors of BagasseAlejandro AguirreNo ratings yet
- Gravity Separation of ParticulateDocument20 pagesGravity Separation of ParticulateAlejandro AguirreNo ratings yet
- Bagasse Compaction - Interim Report Research Report No 5 81 PDFDocument51 pagesBagasse Compaction - Interim Report Research Report No 5 81 PDFCrisanto JimmyNo ratings yet
- WG 90021Document17 pagesWG 90021Alejandro AguirreNo ratings yet
- Startup Fluid Analysis: Department Editor: Rebekkah MarshallDocument1 pageStartup Fluid Analysis: Department Editor: Rebekkah MarshallAlejandro AguirreNo ratings yet
- 2000 - Moor - Belt Vs Chain-Slat BagasseDocument5 pages2000 - Moor - Belt Vs Chain-Slat BagasseAlejandro AguirreNo ratings yet
- Pneumatic ConveyorDocument5 pagesPneumatic ConveyorAhom CKNo ratings yet
- 1994 - Bernhardt - Dry Cleaning of SugarcaneDocument6 pages1994 - Bernhardt - Dry Cleaning of SugarcaneAlejandro AguirreNo ratings yet
- Gravity Separation of ParticulateDocument20 pagesGravity Separation of ParticulateAlejandro AguirreNo ratings yet
- Air SeparatorsDocument8 pagesAir SeparatorssaeedhoseiniNo ratings yet
- Before You Design An Inertial SeparatorDocument4 pagesBefore You Design An Inertial SeparatorAlejandro AguirreNo ratings yet
- Particle SeparationDocument13 pagesParticle SeparationAlejandro AguirreNo ratings yet
- Airflow Inside A Vane Separator Zigzag DeflectorsDocument5 pagesAirflow Inside A Vane Separator Zigzag DeflectorsAlejandro AguirreNo ratings yet
- Heat Transfer - System Design IIDocument1 pageHeat Transfer - System Design IIAnonymous 1zdRSWskhgNo ratings yet
- Design & Application of FeederDocument39 pagesDesign & Application of Feedermaran.suguNo ratings yet
- Statics 2Document4 pagesStatics 2Alejandro AguirreNo ratings yet
- Heat BalanceDocument18 pagesHeat BalanceVinish Shankar100% (1)
- Pbe2009 Screening GlossaryDocument4 pagesPbe2009 Screening GlossaryAlejandro AguirreNo ratings yet
- Statics 5: Internal Forces & MomentsDocument6 pagesStatics 5: Internal Forces & MomentsAlejandro AguirreNo ratings yet
- Vibration TechnologyDocument18 pagesVibration TechnologySakthimgsNo ratings yet
- Bro Dle603 enDocument1 pageBro Dle603 enAlejandro AguirreNo ratings yet
- CHE Facts 1008Document1 pageCHE Facts 1008Alejandro AguirreNo ratings yet
- CHE Facts 1008Document1 pageCHE Facts 1008Alejandro AguirreNo ratings yet
- Boiler Terms and DefinitionsDocument23 pagesBoiler Terms and DefinitionsAbdallah MansourNo ratings yet
- PS SB 5502 Eng 99Document28 pagesPS SB 5502 Eng 99Alejandro AguirreNo ratings yet
- Acceleration in Paper MachinesDocument4 pagesAcceleration in Paper MachinesAlejandro AguirreNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- 04d Process Map Templates-V2.0 (PowerPiont)Document17 pages04d Process Map Templates-V2.0 (PowerPiont)Alfredo FloresNo ratings yet
- Sci Problem SolutionsDocument10 pagesSci Problem SolutionsVS PUBLIC SCHOOL BangaloreNo ratings yet
- Qbake - Production Planning Guide - Bread Line.Document27 pagesQbake - Production Planning Guide - Bread Line.ahetNo ratings yet
- TK-315 CPI2 - 1 - NonReacting SystemsDocument34 pagesTK-315 CPI2 - 1 - NonReacting SystemsMuhammad IkbalNo ratings yet
- NuPolar Quality Testing and ComparisonsDocument12 pagesNuPolar Quality Testing and Comparisonsou82muchNo ratings yet
- Bioinstrumentation III SemDocument2 pagesBioinstrumentation III SemAnonymous Jp9PvVkZNo ratings yet
- Lipid WorksheetDocument2 pagesLipid WorksheetMANUELA VENEGAS ESCOVARNo ratings yet
- Percentiles (Measures of Positions)Document4 pagesPercentiles (Measures of Positions)Leidel Claude TolentinoNo ratings yet
- Engineeringinterviewquestions Com RCC Structures Design Multiple Choice QuestionDocument87 pagesEngineeringinterviewquestions Com RCC Structures Design Multiple Choice QuestionRajeev BansalNo ratings yet
- Geometry and Trigonometry PDFDocument46 pagesGeometry and Trigonometry PDFnewspaperNo ratings yet
- Troubleshooting BGPDocument144 pagesTroubleshooting BGPinnovativekalu100% (3)
- LN 10.5 Ttdomug En-UsDocument82 pagesLN 10.5 Ttdomug En-UstomactinNo ratings yet
- Mathematics - Iii: Instructions To CandidatesDocument2 pagesMathematics - Iii: Instructions To Candidatessimar batraNo ratings yet
- RONDO 2 Audio Processor: Product CatalogueDocument24 pagesRONDO 2 Audio Processor: Product CatalogueLong An DoNo ratings yet
- 2150708Document3 pages2150708UDV DevelopersNo ratings yet
- Mach 3 MillDocument157 pagesMach 3 Millafricano333100% (1)
- Predicting Residual Stresses Due To Solidification in Cast Plastic Plates VladoTropsaPhDDocument225 pagesPredicting Residual Stresses Due To Solidification in Cast Plastic Plates VladoTropsaPhDAghajaniNo ratings yet
- Structure of Atom - Class 11thDocument38 pagesStructure of Atom - Class 11thAdil KhanNo ratings yet
- Chapter 6 - Ion ChannelsDocument12 pagesChapter 6 - Ion ChannelsntghshrNo ratings yet
- Conte R Fort WallDocument30 pagesConte R Fort Wallmirko huaranccaNo ratings yet
- 05 Traps PDFDocument17 pages05 Traps PDFDevinaacsNo ratings yet
- 1) Semester II /1 / IV Exam 2020 (Even) (Old / New Syllabus) BacklogDocument5 pages1) Semester II /1 / IV Exam 2020 (Even) (Old / New Syllabus) BacklogHarsh VardhanNo ratings yet
- 2020 Specimen Paper 1Document16 pages2020 Specimen Paper 1YuanWei SiowNo ratings yet
- Presupposition: A Short PresentationDocument13 pagesPresupposition: A Short PresentationShaimaa SuleimanNo ratings yet
- BPCL Training ReportDocument34 pagesBPCL Training ReportVishalVaishNo ratings yet
- Tanaka, Murakami, Ooka - Effects of Strain Path Shapes On Non-Proportional Cyclic PlasticityDocument17 pagesTanaka, Murakami, Ooka - Effects of Strain Path Shapes On Non-Proportional Cyclic PlasticityDavid C HouserNo ratings yet
- Ieee 1584 Guide Performing Arc Flash Calculations ProcedureDocument6 pagesIeee 1584 Guide Performing Arc Flash Calculations ProcedureBen ENo ratings yet
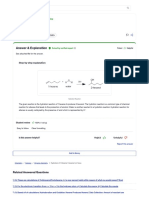
- (Solved) Hydration of 1-Hexene 1-Hexene To 2 Hexanol Equation Write The Equation of The Reaction - Course HeroDocument2 pages(Solved) Hydration of 1-Hexene 1-Hexene To 2 Hexanol Equation Write The Equation of The Reaction - Course HeroJdkrkejNo ratings yet
- Semiconductor Devices and Circuits LaboratoryDocument53 pagesSemiconductor Devices and Circuits LaboratoryKaryampudi RushendrababuNo ratings yet
- Flashprint UserGuide en USDocument44 pagesFlashprint UserGuide en USdreamelarn100% (2)