You might also like
- Another Introduction To Ray TracingDocument308 pagesAnother Introduction To Ray Tracingdewddude100% (1)
- Staad - Pro V8iDocument42 pagesStaad - Pro V8iMayolites0% (1)
- Equivalent Force Systems: This Module Aims That The Students Will Be Able ToDocument11 pagesEquivalent Force Systems: This Module Aims That The Students Will Be Able ToMONIQUE UNICO100% (1)
- S Kuliah05 (3D-Force)Document36 pagesS Kuliah05 (3D-Force)Fattihi EkhmalNo ratings yet
- Quarter 2-Module 3: MathematicsDocument20 pagesQuarter 2-Module 3: MathematicsCherrilyn Enverzo100% (2)
- Sofistik Help PDFDocument115 pagesSofistik Help PDFMatija Vindis50% (2)
- Tai Lieu Creo SimulationDocument24 pagesTai Lieu Creo SimulationdatltNo ratings yet
- Chenming Hu Ch1 SlidesDocument31 pagesChenming Hu Ch1 SlidesdewddudeNo ratings yet
- EE368: Digital Image Processing Project Report: Ian Downes Downes@stanford - EduDocument6 pagesEE368: Digital Image Processing Project Report: Ian Downes Downes@stanford - EduMohit GuptaNo ratings yet
- Contour Detection Using Freeman Chain CodeDocument2 pagesContour Detection Using Freeman Chain CodelahariNo ratings yet
- Shishir Reddy 1.1Document8 pagesShishir Reddy 1.1ER Publications, IndiaNo ratings yet
- An Edge Detection Algorithm Using A Local Distribution: University of Science Technology Avatollahi@,iust - Ac.irDocument4 pagesAn Edge Detection Algorithm Using A Local Distribution: University of Science Technology Avatollahi@,iust - Ac.irravindrapadsalaNo ratings yet
- Anti-Personnel Mine Detection and Classification Using GPR ImageDocument4 pagesAnti-Personnel Mine Detection and Classification Using GPR ImageBHANDIWADMADHUMITANo ratings yet
- Image Segmentation by Using Edge DetectionDocument5 pagesImage Segmentation by Using Edge DetectionArivazhagan ArtNo ratings yet
- Chapter 9 Image Segmentation: 9.7 ThresholdingDocument25 pagesChapter 9 Image Segmentation: 9.7 ThresholdingOnkar JaokarNo ratings yet
- Implementing Security Using Iris Recognition Using MatlabDocument10 pagesImplementing Security Using Iris Recognition Using MatlabDeepak Kumar100% (1)
- Edited IPDocument10 pagesEdited IPdamarajuvarunNo ratings yet
- Presented By: Arz Kumar Satsangi & Vineet VermaDocument26 pagesPresented By: Arz Kumar Satsangi & Vineet VermagarunanarasNo ratings yet
- Fingerprint Image Enhancement Using Directional Morphological FilterDocument4 pagesFingerprint Image Enhancement Using Directional Morphological Filtergalodoido_13No ratings yet
- Digital Image Processing Project Report PDFDocument6 pagesDigital Image Processing Project Report PDFElsadig OsmanNo ratings yet
- Human Detection Using Depth Information by KinectDocument8 pagesHuman Detection Using Depth Information by KinectMudita ChandraNo ratings yet
- Comparison of Edge Detectors: Ayaz Akram, Asad IsmailDocument9 pagesComparison of Edge Detectors: Ayaz Akram, Asad IsmailRamSharmaNo ratings yet
- Image Forgery Detection Based On Quantization Table EstimationDocument4 pagesImage Forgery Detection Based On Quantization Table EstimationKhaled MaNo ratings yet
- Vision Based Lane Detection For Unmanned Ground Vehicle (UGV)Document19 pagesVision Based Lane Detection For Unmanned Ground Vehicle (UGV)AjayNo ratings yet
- Semi-Automatic Image Segmentation: A Bimodal Thresholding ApproachDocument15 pagesSemi-Automatic Image Segmentation: A Bimodal Thresholding ApproachShruthi GurunathNo ratings yet
- Improved Color Edge Detection by Fusion of Hue, PCA & Hybrid CannyDocument8 pagesImproved Color Edge Detection by Fusion of Hue, PCA & Hybrid CannyVijayakumarNo ratings yet
- Improved SIFT Algorithm Image MatchingDocument7 pagesImproved SIFT Algorithm Image Matchingivy_publisherNo ratings yet
- A Survey On Edge Detection Using Different Techniques: Volume 2, Issue 4, April 2013Document5 pagesA Survey On Edge Detection Using Different Techniques: Volume 2, Issue 4, April 2013International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Real-Time Image Processing Algorithms For Object and Distances Identification in Mobile Robot Trajectory PlanningDocument6 pagesReal-Time Image Processing Algorithms For Object and Distances Identification in Mobile Robot Trajectory PlanningamitsbhatiNo ratings yet
- CMR College of Engineering and TechnologyDocument19 pagesCMR College of Engineering and TechnologyBollu PrasadNo ratings yet
- Analysis of Feature Detection Method in Image RegistrationDocument4 pagesAnalysis of Feature Detection Method in Image RegistrationInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Multi-Source Image Registration Based On Log-Polar Coordinates and Extension Phase Correlation PDFDocument7 pagesMulti-Source Image Registration Based On Log-Polar Coordinates and Extension Phase Correlation PDFivy_publisherNo ratings yet
- Reading A QR CodeDocument5 pagesReading A QR CodeSerban PetrescuNo ratings yet
- 3D Map-Building From RGB-D Data Considering Noise Characteristics of KinectDocument6 pages3D Map-Building From RGB-D Data Considering Noise Characteristics of KinectPsycosiado DivertidoNo ratings yet
- Assignment-2:DIP: Mr. Victor Mageto CP10101610245Document10 pagesAssignment-2:DIP: Mr. Victor Mageto CP10101610245Vijayendravarma DanduNo ratings yet
- Overview and Comparative Analysis of Edge Detection Techniques in Digital Image ProcessingDocument8 pagesOverview and Comparative Analysis of Edge Detection Techniques in Digital Image ProcessingMohammed AnsafNo ratings yet
- Face Recognition Using The Most Representative Sift Images: Issam Dagher, Nour El Sallak and Hani HazimDocument10 pagesFace Recognition Using The Most Representative Sift Images: Issam Dagher, Nour El Sallak and Hani Hazimtidjani86No ratings yet
- 04-12-18 - Notice On 2nd Stage CBT - Section Wise MarksDocument6 pages04-12-18 - Notice On 2nd Stage CBT - Section Wise MarksraghuNo ratings yet
- Vertical Lane Line Detection Technology Based On Hough TransformDocument7 pagesVertical Lane Line Detection Technology Based On Hough Transformpepethefrogg45No ratings yet
- Seeded Region Growing Using Line Scan Algorithm - Stack Base ImplementationDocument15 pagesSeeded Region Growing Using Line Scan Algorithm - Stack Base Implementationpi194043No ratings yet
- Denoising and Edge Detection Using SobelmethodDocument6 pagesDenoising and Edge Detection Using SobelmethodIJMERNo ratings yet
- ChoThetMon (Paper) CU (Ma U Bin)Document7 pagesChoThetMon (Paper) CU (Ma U Bin)K KayeNo ratings yet
- Region Growing Algorithm For UnderWater Image SegmentationDocument8 pagesRegion Growing Algorithm For UnderWater Image Segmentationpi194043No ratings yet
- AnprDocument18 pagesAnprVNo ratings yet
- Marker Detection For Augmented Reality Applications: Martin HirzerDocument27 pagesMarker Detection For Augmented Reality Applications: Martin HirzerSarra JmailNo ratings yet
- Modified Color Based Edge Detection of Remote Sensing Images Using Fuzzy LogicDocument5 pagesModified Color Based Edge Detection of Remote Sensing Images Using Fuzzy LogicInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- 13-Detecção de Sinais de Trânsito Usando MatlabDocument4 pages13-Detecção de Sinais de Trânsito Usando MatlabIsabela LopesNo ratings yet
- Recognizing Pictures at An Exhibition Using SIFTDocument5 pagesRecognizing Pictures at An Exhibition Using SIFTAmit Kumar MondalNo ratings yet
- Edge Detectors: Deptofcs& EDocument26 pagesEdge Detectors: Deptofcs& Eishant7890No ratings yet
- Real Time Traffic Light Control Using Image ProcessingDocument5 pagesReal Time Traffic Light Control Using Image ProcessingCharan KilariNo ratings yet
- Research and Application of The EAN-13 Barcode Recognition On IphoneDocument4 pagesResearch and Application of The EAN-13 Barcode Recognition On IphoneDự Thái HoàngNo ratings yet
- Edge Detection PDFDocument12 pagesEdge Detection PDFchaithra580No ratings yet
- Automated 3D Scenes Reconstruction For Mobile Robots Using Laser ScanningDocument6 pagesAutomated 3D Scenes Reconstruction For Mobile Robots Using Laser ScanningIan MedeirosNo ratings yet
- Comparison of Gpu and Fpga Hardware Acceleration of Lane Detection AlgorithmDocument10 pagesComparison of Gpu and Fpga Hardware Acceleration of Lane Detection AlgorithmsipijNo ratings yet
- Eye Detection Project Report. 7/19/2005 Project Description: 1. Edge Detection - Canny Edge DetectorDocument8 pagesEye Detection Project Report. 7/19/2005 Project Description: 1. Edge Detection - Canny Edge DetectorKaif KhanNo ratings yet
- Speedy Detection Algorithm of Underwater MovingDocument13 pagesSpeedy Detection Algorithm of Underwater MovingvenuputtamrajuNo ratings yet
- iMAGE BASED DISTANCE MEASUREMENTDocument8 pagesiMAGE BASED DISTANCE MEASUREMENTDr. A S AhlawatNo ratings yet
- Calculating Distance To Tomato Using Stereo Vision For Automatic HarvestingDocument9 pagesCalculating Distance To Tomato Using Stereo Vision For Automatic HarvestingÁnh Phạm NgọcNo ratings yet
- 7 Shape FeaturesDocument9 pages7 Shape FeaturesKareem SamirNo ratings yet
- 3d Mapping Iser 10 FinalDocument15 pages3d Mapping Iser 10 FinalHieu TranNo ratings yet
- Sketch-to-Sketch Match With Dice Similarity MeasuresDocument6 pagesSketch-to-Sketch Match With Dice Similarity MeasuresInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Barcode LocalizationDocument3 pagesBarcode LocalizationFrederico LopesNo ratings yet
- Marker Detection For Augmented Reality Applications: Martin HirzerDocument27 pagesMarker Detection For Augmented Reality Applications: Martin HirzerMohamad YusronNo ratings yet
- Automatic Rectification of Perspective Distortion From A Single Image Using Plane Homography PDFDocument12 pagesAutomatic Rectification of Perspective Distortion From A Single Image Using Plane Homography PDFAnonymous lVQ83F8mCNo ratings yet
- Tone Mapping: Tone Mapping: Illuminating Perspectives in Computer VisionFrom EverandTone Mapping: Tone Mapping: Illuminating Perspectives in Computer VisionNo ratings yet
- Histogram Equalization: Enhancing Image Contrast for Enhanced Visual PerceptionFrom EverandHistogram Equalization: Enhancing Image Contrast for Enhanced Visual PerceptionNo ratings yet
- Alignment of Non-Overlapping ImagesDocument8 pagesAlignment of Non-Overlapping ImagesdewddudeNo ratings yet
- Surface LayoutDocument23 pagesSurface LayoutdewddudeNo ratings yet
- CLAHE in ColorDocument6 pagesCLAHE in ColordewddudeNo ratings yet
- Prevelance of Autism in United StatesDocument24 pagesPrevelance of Autism in United StatesdewddudeNo ratings yet
- Independent Component AnalysisDocument13 pagesIndependent Component AnalysisdewddudeNo ratings yet
- Large-Scale and Drift-Free Surface Reconstruction Using Online Subvolume RegistrationDocument9 pagesLarge-Scale and Drift-Free Surface Reconstruction Using Online Subvolume RegistrationdewddudeNo ratings yet
- Another Tutorial On Independent Component AnalysisDocument30 pagesAnother Tutorial On Independent Component AnalysisdewddudeNo ratings yet
- DeblurringDocument15 pagesDeblurringdewddudeNo ratings yet
- Prob. ReviewDocument20 pagesProb. ReviewdewddudeNo ratings yet
- Highlighting Parts of GUI Text - Unity AnswersDocument5 pagesHighlighting Parts of GUI Text - Unity AnswersdewddudeNo ratings yet
- Half Projective WarpsDocument8 pagesHalf Projective WarpsdewddudeNo ratings yet
- RasterTek: Direct3D IntroductionDocument710 pagesRasterTek: Direct3D IntroductiondewddudeNo ratings yet
- Short Introduction To Radon and Hough TransformDocument11 pagesShort Introduction To Radon and Hough TransformdewddudeNo ratings yet
- Ofdm Receiver DesignDocument18 pagesOfdm Receiver DesignsriIITNo ratings yet
- CH 1Document34 pagesCH 1hefftyaNo ratings yet
- Renng ThesisDocument203 pagesRenng ThesisdewddudeNo ratings yet
- Lecture1 - ReviewsDocument15 pagesLecture1 - ReviewsdewddudeNo ratings yet
- Setting Up GLUT: CS 148 Autumn 2011-2012 September 24, 2012Document3 pagesSetting Up GLUT: CS 148 Autumn 2011-2012 September 24, 2012dewddudeNo ratings yet
- Experience Implementing An Elliptical Head Tracker in MatlabDocument7 pagesExperience Implementing An Elliptical Head Tracker in MatlabdewddudeNo ratings yet
- Lecture 04Document40 pagesLecture 04dewddudeNo ratings yet
- Lecture1 2upDocument11 pagesLecture1 2updewddudeNo ratings yet
- Maths P1 QP GR11 Nov 2020 Eng DDocument8 pagesMaths P1 QP GR11 Nov 2020 Eng DThoba LalisaNo ratings yet
- 7th Grade Module 1 Lesson 6Document5 pages7th Grade Module 1 Lesson 6api-369302912No ratings yet
- CNC and The EMCO Compact 5 Lathe PDFDocument19 pagesCNC and The EMCO Compact 5 Lathe PDFabyzenNo ratings yet
- CIMATRON SketcherDocument71 pagesCIMATRON Sketcherpepepomez3No ratings yet
- Lesson 1-1 - STEM 1BDocument25 pagesLesson 1-1 - STEM 1BJune Patricia AraizNo ratings yet
- Hurco Lathe NC Programming r0114-301BDocument80 pagesHurco Lathe NC Programming r0114-301Brastaegg100% (1)
- Straight LineDocument17 pagesStraight LineAdrita KakotyNo ratings yet
- CREO PARAMETRIC 2.0 SYLLABUS. Career Courses CAD & Design EngineerDocument2 pagesCREO PARAMETRIC 2.0 SYLLABUS. Career Courses CAD & Design Engineeromkar patilNo ratings yet
- G7 Q4 Week 04Document9 pagesG7 Q4 Week 04jell estabilloNo ratings yet
- International Mathematics Olympiad SyllabusDocument5 pagesInternational Mathematics Olympiad Syllabussubashavvaru100% (1)
- 9709 s10 QP 11Document4 pages9709 s10 QP 11roukaiya_peerkhanNo ratings yet
- Microstation CommandsDocument32 pagesMicrostation Commandsjibran42No ratings yet
- RoboDK Doc EN Getting StartedDocument20 pagesRoboDK Doc EN Getting Startedtayari_lNo ratings yet
- AriHant MATHEMATICSDocument15 pagesAriHant MATHEMATICSNareshJagathkar100% (1)
- Um Sca 20 eDocument43 pagesUm Sca 20 eBonjanNo ratings yet
- On The Practical Implementation of A Geometric Voting Algorithm For Star TrackersDocument8 pagesOn The Practical Implementation of A Geometric Voting Algorithm For Star TrackersabwickesNo ratings yet
- Integral CalculusDocument2 pagesIntegral CalculusEricson CapuaNo ratings yet
- Manual GiDDocument224 pagesManual GiDVictor SosaNo ratings yet
- Adept Scara FullDocument30 pagesAdept Scara FullAyman HadiNo ratings yet
- CXC (Csec) Mathematics May 2011 Bootcamps #1Document20 pagesCXC (Csec) Mathematics May 2011 Bootcamps #1glacsecgroupNo ratings yet
- Crystal Structures IIDocument35 pagesCrystal Structures IISamNo ratings yet
- Major and Minor Elements GeochemistryDocument7 pagesMajor and Minor Elements GeochemistryShah FahadNo ratings yet
- Assembly ModelingDocument222 pagesAssembly ModelingjdfdfererNo ratings yet
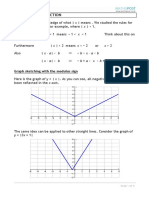
- C3 Modulus Functions PDFDocument5 pagesC3 Modulus Functions PDFatul kumarNo ratings yet