You might also like
- Python Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreFrom EverandPython Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreNo ratings yet
- Performance TunningDocument7 pagesPerformance TunningSreenivasulu Reddy SanamNo ratings yet
- Equnix PostgreSQL Query TuningDocument45 pagesEqunix PostgreSQL Query TuningPutri Herdiyani100% (1)
- Using PostgreSQL in Web 2.0 ApplicationsDocument21 pagesUsing PostgreSQL in Web 2.0 ApplicationsNikolay Samokhvalov100% (8)
- Полнотекстовый Поиск В Postgresql За МиллисекундыDocument54 pagesПолнотекстовый Поиск В Postgresql За МиллисекундыSzERGNo ratings yet
- 46 PDFsam Redis CookbookDocument5 pages46 PDFsam Redis CookbookHữu Hưởng NguyễnNo ratings yet
- Fixed Point Algorithmic Math Package User's GuideDocument8 pagesFixed Point Algorithmic Math Package User's GuideemillianoNo ratings yet
- Gena RiseDocument32 pagesGena RiseAnonymous MqprQvjEKNo ratings yet
- Handling Missing Keys With Setdefault: Example 3-2 Example 3-2 Example 3-3Document5 pagesHandling Missing Keys With Setdefault: Example 3-2 Example 3-2 Example 3-3lokeswari538No ratings yet
- Spting BootDocument54 pagesSpting Bootediga madhuNo ratings yet
- 15 Advanced PostgreSQL CommandsDocument11 pages15 Advanced PostgreSQL CommandsAbdulHakim Khalib HaliruNo ratings yet
- Intermediate PythonDocument79 pagesIntermediate PythonGevorg A. GalstyanNo ratings yet
- Keyerror: 'Four'Document5 pagesKeyerror: 'Four'lokeswari538No ratings yet
- XG BoostDocument4 pagesXG BoostNur Laili100% (1)
- Aggregation and IndexingDocument7 pagesAggregation and IndexingSCOC03 Aditya ChaudhariNo ratings yet
- XgboostDocument4 pagesXgboostpohisNo ratings yet
- Advanced Usage of Indexes in CoherenceDocument24 pagesAdvanced Usage of Indexes in CoherencegpeevNo ratings yet
- BDA List of Experiments For Practical ExamDocument21 pagesBDA List of Experiments For Practical ExamPharoah GamerzNo ratings yet
- 14 Section HandoutDocument3 pages14 Section HandoutKhatia IvanovaNo ratings yet
- MONGODBINSTLLATION and LAB MANUALDocument15 pagesMONGODBINSTLLATION and LAB MANUALNeeraj KumarNo ratings yet
- Wiki - First - Grid - JqGrid WikiDocument9 pagesWiki - First - Grid - JqGrid WikiJavier MongeNo ratings yet
- Importer and Exporter Product For Data Analysis Based On Extract, Transform, Load (ETL) and Regular Expression With Python Programming .TewayDocument26 pagesImporter and Exporter Product For Data Analysis Based On Extract, Transform, Load (ETL) and Regular Expression With Python Programming .TewayBharat ThakurNo ratings yet
- Project 3Document5 pagesProject 3headgoonNo ratings yet
- Oodp Unit 5Document205 pagesOodp Unit 5Dhruv BhasinNo ratings yet
- Abinitio Faq'sDocument19 pagesAbinitio Faq'sparvEenNo ratings yet
- Comp 258: Assignment 2Document9 pagesComp 258: Assignment 2Hamza SheikhNo ratings yet
- Git-Update-Index (1) - Linux Manual PageDocument18 pagesGit-Update-Index (1) - Linux Manual PageJeya MuruganNo ratings yet
- C++ AssignmentDocument3 pagesC++ AssignmentVishal SubramanyamNo ratings yet
- C Interview Questions and AnswersDocument63 pagesC Interview Questions and AnswerskakashokNo ratings yet
- AggregatesDocument1 pageAggregatesMickhel Davee RemerataNo ratings yet
- PLSQLDocument28 pagesPLSQLskumar4787No ratings yet
- Flexible Indexing With Postgres: Ruce OmjianDocument52 pagesFlexible Indexing With Postgres: Ruce OmjianStephen EfangeNo ratings yet
- From Scratch: Writing Your Own FunctionsDocument15 pagesFrom Scratch: Writing Your Own FunctionsAnas JamshedNo ratings yet
- Testing Tools Ques, Notes, FAQ's EtcDocument93 pagesTesting Tools Ques, Notes, FAQ's Etcapi-3705219No ratings yet
- JDBC FinalDocument55 pagesJDBC FinalRahul Kumar SinghNo ratings yet
- 21 CS107 Practice MidtermDocument7 pages21 CS107 Practice MidtermClay SchubinerNo ratings yet
- Display ListDocument4 pagesDisplay ListGeorge PuiuNo ratings yet
- CSC 2200 P A 1 O C: Rogramming Ssignment Rdered OllectionDocument4 pagesCSC 2200 P A 1 O C: Rogramming Ssignment Rdered OllectionboomboomtwiceNo ratings yet
- MongoDB Quick BookDocument11 pagesMongoDB Quick Bookshahamit2No ratings yet
- IQ Bot Custom Logic Documentation - Advanced DraftDocument19 pagesIQ Bot Custom Logic Documentation - Advanced Draftshub001No ratings yet
- Secp 256 K 1Document11 pagesSecp 256 K 1alexandrNo ratings yet
- All APIDocument18 pagesAll APIajay wareNo ratings yet
- 10 Data-StructuresDocument25 pages10 Data-StructuresAndrea OliveriNo ratings yet
- Distributed PostgreSQLDocument118 pagesDistributed PostgreSQLtan hadiNo ratings yet
- Hibernate - Element:-: Implementations. There Are Shortcut Names For The Built-In GeneratorsDocument3 pagesHibernate - Element:-: Implementations. There Are Shortcut Names For The Built-In GeneratorsPrabhakar PrabhuNo ratings yet
- System Ver I LogDocument8 pagesSystem Ver I LogElisha KirklandNo ratings yet
- Data Structures AND Algorithms: Lecture Notes 11Document84 pagesData Structures AND Algorithms: Lecture Notes 11elemaniaqNo ratings yet
- Execution Flow of Trigger/salesforce/apex: This Can Not Be Controlled by ProgrammerDocument5 pagesExecution Flow of Trigger/salesforce/apex: This Can Not Be Controlled by Programmersaurabh pingaleNo ratings yet
- Quicktest Professional Scripting Standards: The Basic Format of The ScriptDocument15 pagesQuicktest Professional Scripting Standards: The Basic Format of The ScriptmunibalaNo ratings yet
- Cosmosdb StudyDocument41 pagesCosmosdb StudyBryan SanchezNo ratings yet
- DataStage Faq SDocument57 pagesDataStage Faq Sswaroop24x7No ratings yet
- Performance Tuning Addedinfo OracleDocument49 pagesPerformance Tuning Addedinfo OraclesridkasNo ratings yet
- C ReviewDocument115 pagesC ReviewFurkan KÖROĞLUNo ratings yet
- Khem Raj Embedded Linux Conference 2014, San Jose, CADocument29 pagesKhem Raj Embedded Linux Conference 2014, San Jose, CAproxymo1No ratings yet
- Day 17Document9 pagesDay 17Dawood urineNo ratings yet
- Curso MoshDocument7 pagesCurso MoshCesar MartinezNo ratings yet
- Using Triggers To Add An Audit Log To Postgres DatabasesDocument13 pagesUsing Triggers To Add An Audit Log To Postgres Databasesleonard1971No ratings yet
- 10 Functions: Main SwitchDocument46 pages10 Functions: Main Switchapi-3745065No ratings yet
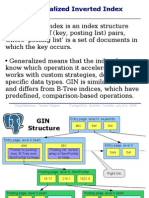
- Generalized Inverted Index An Inverted Index Is An IndexDocument14 pagesGeneralized Inverted Index An Inverted Index Is An IndexNikolay Samokhvalov100% (1)
- Gavin M. Roy: myYearBook - Com Architecture (Highload++, Moscow, Russia, October 2008)Document30 pagesGavin M. Roy: myYearBook - Com Architecture (Highload++, Moscow, Russia, October 2008)Nikolay Samokhvalov100% (1)
- Video Radar Tps 78Document14 pagesVideo Radar Tps 78Nikolay SamokhvalovNo ratings yet
- PostgreSQL Performance TuningDocument63 pagesPostgreSQL Performance TuningNikolay Samokhvalov100% (9)
- XML Support in PostgreSQLDocument6 pagesXML Support in PostgreSQLNikolay Samokhvalov100% (2)
- Full-Text Search in PostgreSQLDocument77 pagesFull-Text Search in PostgreSQLNikolay Samokhvalov100% (20)
- Final Project Report Barcode Scanner On A XScale PXA27xDocument5 pagesFinal Project Report Barcode Scanner On A XScale PXA27xkaxkusNo ratings yet
- Excel Practical 2 - Peppis Pizza (2014) PDFDocument8 pagesExcel Practical 2 - Peppis Pizza (2014) PDFrupende12No ratings yet
- Shoes GUI For RubyDocument63 pagesShoes GUI For RubySlametz PembukaNo ratings yet
- USMTGUI User GuideDocument11 pagesUSMTGUI User GuideNguyen Hoang AnhNo ratings yet
- SQL: LIKE ConditionDocument7 pagesSQL: LIKE ConditionjoseavilioNo ratings yet
- Pioneer CDJ 3000Document89 pagesPioneer CDJ 3000Ahmedić-Kovačević KrigeNo ratings yet
- AutoCAD Questions at GL BajajDocument6 pagesAutoCAD Questions at GL BajajHARISH VERMANo ratings yet
- Unit 15 - Assignment 1Document3 pagesUnit 15 - Assignment 1api-308615665No ratings yet
- B-85314EN-1 01 (Alpha-DiA5 Custom PMC) PDFDocument242 pagesB-85314EN-1 01 (Alpha-DiA5 Custom PMC) PDFmastorres87No ratings yet
- Basic VTP Configuration Lab Instructions 2Document8 pagesBasic VTP Configuration Lab Instructions 2Matchgirl42100% (1)
- Lab Manual For CCNPDocument180 pagesLab Manual For CCNPblck bxNo ratings yet
- Project Charter - Team Fine CrewDocument3 pagesProject Charter - Team Fine CrewGAME BUSTERNo ratings yet
- PortFast and UplinkFastDocument8 pagesPortFast and UplinkFastKhaled ShimiNo ratings yet
- Starting Out With Java From Control Structures Through Data Structures 3rd Edition Ebook PDFDocument62 pagesStarting Out With Java From Control Structures Through Data Structures 3rd Edition Ebook PDFluciano.gregory787100% (39)
- Ru Dublgis DgismobileDocument131 pagesRu Dublgis DgismobileАяна ТабалдиеваNo ratings yet
- CP 340 ManualDocument212 pagesCP 340 Manualthuong_hanNo ratings yet
- Overview IFMon Solution Manager 7.2Document25 pagesOverview IFMon Solution Manager 7.2Ahmed ShafirNo ratings yet
- Office Memorandum (Salary)Document2 pagesOffice Memorandum (Salary)PHED MizoramNo ratings yet
- ReferencesDocument2 pagesReferencesBrenda Rojas CardozoNo ratings yet
- BGA Breakout Challenges: by Charles Pfeil, Mentor GraphicsDocument4 pagesBGA Breakout Challenges: by Charles Pfeil, Mentor GraphicsBenyamin Farzaneh AghajarieNo ratings yet
- Operating System AssignmentDocument13 pagesOperating System AssignmentMarc AndalloNo ratings yet
- JUE200Document2 pagesJUE200ella100% (1)
- FLIP - FLOPS Lab-Sheet-Digital-ElectronicsDocument5 pagesFLIP - FLOPS Lab-Sheet-Digital-Electronicswakala manaseNo ratings yet
- Analog Input Module: SCM20XDocument5 pagesAnalog Input Module: SCM20XChethanNo ratings yet
- Worksheet 2.11 Unit TestingDocument10 pagesWorksheet 2.11 Unit TestingJuan Sebastian MendezNo ratings yet
- The Business Value of Oracle Database Appliance: Executive SummaryDocument16 pagesThe Business Value of Oracle Database Appliance: Executive SummaryyurijapNo ratings yet
- Google Academy - Publicidad DisplayDocument53 pagesGoogle Academy - Publicidad DisplaymatungooNo ratings yet
- SAP CRM For Higher Education Business BlueprintDocument31 pagesSAP CRM For Higher Education Business BlueprintmarkyrayNo ratings yet
- Using Icon Fonts - Go Make ThingsDocument17 pagesUsing Icon Fonts - Go Make ThingsFita S'namosi SiemNo ratings yet
- Static Variable and MethodDocument9 pagesStatic Variable and Methodsiddhant kudesiaNo ratings yet