You might also like
- 40 Top Potential Viva Questions (Diambil DariDocument1 page40 Top Potential Viva Questions (Diambil Dari3rlangNo ratings yet
- Kruskal-Wallis H TableDocument1 pageKruskal-Wallis H Table3rlangNo ratings yet
- KW Expanded Tables 4groupsDocument19 pagesKW Expanded Tables 4groups3rlangNo ratings yet
- 04.3-MSN-Dua Sampel Berpasangan-Uji Ranking Bertanda Wilcoxon CDocument22 pages04.3-MSN-Dua Sampel Berpasangan-Uji Ranking Bertanda Wilcoxon C3rlangNo ratings yet
- Manual - SUSENAS - Overall and Survey Process - v1.2 PDFDocument232 pagesManual - SUSENAS - Overall and Survey Process - v1.2 PDF3rlangNo ratings yet
- KW Expanded Tables 3groupsDocument196 pagesKW Expanded Tables 3groups3rlangNo ratings yet
- Run TestDocument26 pagesRun TestRohaila Rohani100% (2)
- 04.3-MSN-Dua Sampel Berpasangan-Uji Ranking Bertanda Wilcoxon CDocument22 pages04.3-MSN-Dua Sampel Berpasangan-Uji Ranking Bertanda Wilcoxon C3rlangNo ratings yet
- MSN Uji U Mann WhitneyDocument29 pagesMSN Uji U Mann Whitney3rlangNo ratings yet
- 04.2-MSN-Dua Sampel Berhubungan-Uji Tanda CDocument28 pages04.2-MSN-Dua Sampel Berhubungan-Uji Tanda C3rlangNo ratings yet
- 04.3-MSN-Dua Sampel Berpasangan-Uji Ranking Bertanda Wilcoxon CDocument22 pages04.3-MSN-Dua Sampel Berpasangan-Uji Ranking Bertanda Wilcoxon C3rlangNo ratings yet
- 1 Parametrik Dan NonparametrikDocument14 pages1 Parametrik Dan Nonparametrik3rlangNo ratings yet
- 0000Document14 pages00003rlangNo ratings yet
- Call For Papers-IRSA2016Document1 pageCall For Papers-IRSA20163rlangNo ratings yet
- Biclust STIS Jan 2017Document39 pagesBiclust STIS Jan 20173rlangNo ratings yet
- Discriminant Analysis Functions Predict Group MembershipDocument20 pagesDiscriminant Analysis Functions Predict Group MembershipUmar Farooq AttariNo ratings yet
- Exercises SsDocument12 pagesExercises Ss3rlangNo ratings yet
- 2012 Mean ComparisonDocument35 pages2012 Mean Comparison3rlangNo ratings yet
- Count Regression ModelsDocument4 pagesCount Regression Models3rlangNo ratings yet
- 5.5 Normal Approximations To Binomial DistributionsDocument27 pages5.5 Normal Approximations To Binomial Distributions3rlangNo ratings yet
- 01 Family TypesDocument14 pages01 Family Types3rlangNo ratings yet
- RGUIDocument37 pagesRGUI3rlangNo ratings yet
- 0 A 85 e 5304 B 918 DB 67 F 000000Document2 pages0 A 85 e 5304 B 918 DB 67 F 0000003rlangNo ratings yet
- JURNALDocument8 pagesJURNAL3rlangNo ratings yet
- 03 lp2Document35 pages03 lp23rlangNo ratings yet
- R L L I - W H B D W N B D ?: Esearch On Apse in IFE Nsurance HAT AS EEN One and HAT Eeds TO E ONEDocument28 pagesR L L I - W H B D W N B D ?: Esearch On Apse in IFE Nsurance HAT AS EEN One and HAT Eeds TO E ONE3rlangNo ratings yet
- IRSA 2015 AbsractDocument1 pageIRSA 2015 Absract3rlangNo ratings yet
- Male Engagement in FP Brief 10.10.14Document12 pagesMale Engagement in FP Brief 10.10.143rlangNo ratings yet
- HDR 1990 en Complete NostatsDocument141 pagesHDR 1990 en Complete Nostats3rlangNo ratings yet
- How to Interpret the Constant (Y Intercept) in Regression AnalysisDocument9 pagesHow to Interpret the Constant (Y Intercept) in Regression Analysis3rlangNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5784)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Assignment (40%) : A) Formulate The Problem As LPM B) Solve The LPM Using Simplex AlgorithmDocument5 pagesAssignment (40%) : A) Formulate The Problem As LPM B) Solve The LPM Using Simplex Algorithmet100% (1)
- Port Ps PDFDocument2 pagesPort Ps PDFluisNo ratings yet
- UniSim Heat Exchangers User Guide PDFDocument22 pagesUniSim Heat Exchangers User Guide PDFzhangyiliNo ratings yet
- WP 13 General Annexes - Horizon 2023 2024 - enDocument43 pagesWP 13 General Annexes - Horizon 2023 2024 - enLuchianNo ratings yet
- 08 - Chapter 1 - Waveguide-Transmission Line - Microstrip LinesDocument76 pages08 - Chapter 1 - Waveguide-Transmission Line - Microstrip Linesgilberto araujoNo ratings yet
- Quantitative Metallography Lab Report: Grain Size and Carbon Volume FractionDocument14 pagesQuantitative Metallography Lab Report: Grain Size and Carbon Volume FractionMhd. Didi Endah PranataNo ratings yet
- GITAM Guidelines For MBA Project Work - 2018Document6 pagesGITAM Guidelines For MBA Project Work - 2018Telika RamuNo ratings yet
- Summative Test in Grade 10 ScienceDocument2 pagesSummative Test in Grade 10 ScienceRomeo GabitananNo ratings yet
- Mechanics of FlightDocument1 pageMechanics of FlightMoh Flit25% (4)
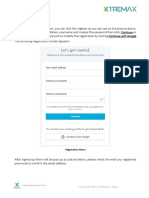
- Register for a WordPress account in 5 easy stepsDocument5 pagesRegister for a WordPress account in 5 easy stepsPutriNo ratings yet
- Container Stuffing Advice for Reducing Cargo DamageDocument16 pagesContainer Stuffing Advice for Reducing Cargo DamageBerkay TürkNo ratings yet
- SurveillanceDocument17 pagesSurveillanceGaurav Khanna100% (1)
- Report CategoryWiseSECCVerification 315700301009 08 2019Document2 pagesReport CategoryWiseSECCVerification 315700301009 08 2019Sandeep ChauhanNo ratings yet
- How To Think Like Leonarda Da VinciDocument313 pagesHow To Think Like Leonarda Da VinciAd Las94% (35)
- Embraer ePerf Tablet App Calculates Takeoff & Landing Performance OfflineDocument8 pagesEmbraer ePerf Tablet App Calculates Takeoff & Landing Performance OfflinewilmerNo ratings yet
- "Roughness": Filtering and Filtering and Filtering and Filtering and Surface Surface Texture TextureDocument29 pages"Roughness": Filtering and Filtering and Filtering and Filtering and Surface Surface Texture TextureZouhair BenmabroukNo ratings yet
- Barco High Performance MonitorsDocument34 pagesBarco High Performance Monitorskishore13No ratings yet
- Chapter 2 - Key Themes of Environmental ScienceDocument34 pagesChapter 2 - Key Themes of Environmental ScienceJames Abuya BetayoNo ratings yet
- Onward Journey Ticket Details E Ticket Advance ReservationDocument1 pageOnward Journey Ticket Details E Ticket Advance ReservationAnonymous yorzHjDBdNo ratings yet
- 2219 Aluminium Alloy - WikipediaDocument2 pages2219 Aluminium Alloy - WikipediaVysakh VasudevanNo ratings yet
- Unit 30 WorkDocument2 pagesUnit 30 WorkThanh HàNo ratings yet
- ADV7513 Hardware User GuideDocument46 pagesADV7513 Hardware User Guide9183290782100% (1)
- Diagrama Montacargas AlmacenDocument8 pagesDiagrama Montacargas AlmacenMiguel Gutierrez100% (1)
- Muhammad Ajmal: Electrical EngineerDocument1 pageMuhammad Ajmal: Electrical EngineerMuhammad AbrarNo ratings yet
- Steam Technical InfoDocument2 pagesSteam Technical InfoAnonymous 7z6OzoNo ratings yet
- How To Set Up Simulator Ard MMDocument12 pagesHow To Set Up Simulator Ard MMJayakrishnaNo ratings yet
- Fc6a Plus (MQTT)Document44 pagesFc6a Plus (MQTT)black boxNo ratings yet
- ECOSYS FS-2100D Ecosys Fs-2100Dn Ecosys Fs-4100Dn Ecosys Fs-4200Dn Ecosys Fs-4300Dn Ecosys Ls-2100Dn Ecosys Ls-4200Dn Ecosys Ls-4300DnDocument33 pagesECOSYS FS-2100D Ecosys Fs-2100Dn Ecosys Fs-4100Dn Ecosys Fs-4200Dn Ecosys Fs-4300Dn Ecosys Ls-2100Dn Ecosys Ls-4200Dn Ecosys Ls-4300DnJosé Bonifácio Marques de AmorimNo ratings yet
- Atuador Ip67Document6 pagesAtuador Ip67Wellington SoaresNo ratings yet
- Calicut University: B. A PhilosophyDocument6 pagesCalicut University: B. A PhilosophyEjaz KazmiNo ratings yet