Professional Documents
Culture Documents
SPSS Manual
Uploaded by
Lumy UngureanuCopyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
SPSS Manual
Uploaded by
Lumy UngureanuCopyright:
Available Formats
i
SPSS for INSTITUTIONAL RESEARCHERS
TABLE OF CONTENTS
Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
PART 1: A BEGINNERS GUIDE TO SPSS 10.1
Starting SPSS & Screen Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
The Data Editor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Creating a New data Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Inserting and Deleting Variables and/or Cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Importing Data from Excel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Saving Your Data File . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
The Output Viewer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Making New Combination Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Reverse Scoring Questionnaire Items . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Sorting & Selecting Cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Descriptive Statistics
Double Checking Your Data File . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
Descriptive Statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
Crosstabs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Inferential Statistics
Chi Square . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
Correlation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Testing the Difference Between Means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
One Sample t-test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
Independent Groups t-ratio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
Repeated Measures t-test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
One-Way Analysis of Variance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
Creating Charts and Graphs in SPSS
Quantile Plot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Bar Graphs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Pie Charts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Simple Scatterplots . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Histograms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
ii
PART 2: ADVANCED SPSS 10.1 STATISTICAL PROCEDURES
Linear Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Binary Logistic Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
Discriminant Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
ANALYZING AND INTERPRETING SURVEY RESULTS . . . . . . . . . . . . . . . . . . . . . . . . . 64
USING SPSS OUTPUT IN OTHER PROGRAMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
APPENDIX A. Parametric and Nonparametric Statistics:
Selection Criteria for Various Research Methods . . . . . . . . . . . . . . . 68
INTRODUCTION
The functions of a typical institutional research office are varied based on the
organizational structure of the college/university and, most importantly, staff size. More
often than not, the list of projects we would like to do exceed what we reasonably can
do. Although the differences in the scope of responsibility may exceed the similarities, there
are some fundamental truths of our business. Reliable analyses based on sound research
methodology are expected regardless of whether the college/university employs a 5-person
staff or is one person shop. Further as the job description on the institutional researcher
expands to include assessment and accreditation, the knowledge and skills required to be
successful in the field also expands. These knowledge and skills now include a wider set of
computer competencies.
Most institutional researchers are very adept at using Microsoft Excel or another spreadsheet
program to perform many of the basic functions of our profession. As the sophistication of the
analysis increases, however, the usefulness of Excel decreases. Statistical software packages
allow institutional researchers to conduct the rigorous analyses needed to answer many of the
research questions we are asked to investigate. SPSS and SAS are the two most often used by
institutional researchers. For reasons of design, support, and cost, SPSS is the software
package that is preferred by small institutional research offices.
Understandably, questions are posed about the value of taking the time to learn a new
software program when the need may not be immediate. Isnt Excel good enough? There
are numerous answers to this question that persuasively suggest that institutional researchers
expand their software competencies to include a statistical software package.
1. The programs are fundamentally different
SPSS is a statistical analysis program, whereas Excel is a spreadsheet program designed
to manage data rather than analyze it. Excel is appropriate for basic descriptives and possibly
correlations, but is inadequate for most other statistical analyses.
2. Excel cannot handle multiple analyses
Microsoft Excel is not programmed to effectively handle a variety of procedures using
the same data set. To do so would require numerous sorting and reorganizing of a basic data
set. Each analysis in Excel requires a different data organization. In SPSS, the data set is in a
very user friendly format which allows for the specification of multiple analyses of the
same data set.
3. Excel does not provide a road map of the analysis
Conducting statistical analyses in Excel does not track the steps in your analysis. This
is especially important if you wanted to conduct a similar analysis at a later date. SPSS
provides a log of the steps taken to complete an analysis.
4. Excel cannot manage large data sets
Excel is limited to a finite number of variables. As the size of our data sets increase,
the statistical packages we use must be able to grow. SPSS has the capability to accept as
many variables as you need.
5. Excel functions and formula may need to be defined personally
For some necessary functions, you may need to define your own formulae which can
lead to errors. In SPSS, the full range statistical analyses are provided. This is not to say that
errors are prevented; however, the analyst must know the right buttons to push.
SPSS for Institutional Researchers 2
6. Excel output is not particularly useful
The Excel output for statistical analyses is typically disorganized and difficult to
follow. SPSS logically organizes output with distinct labels to facilitate its use.
7. Excel was not designed to analyze survey results
Excel was developed as a spreadsheet program and is not adaptable to institutional
research needs in terms of survey analysis. SPSS was developed as a social science package
and provides as part of its basic functions reliability analyses, factor analyses, and
multivariate techniques that are essential to survey research.
8. Excel is incompatible with non-Microsoft programs
Copy and pasting tables, charts, and graphs from Excel to Microsoft Word is easy.
Other data sources cannot be imported easily into Excel. SPSS data sets can convert Excel,
ASCII and database files for analysis and may also be exported into other programs. The
versatility of the program allows for multiple uses of one data set.
HOWEVER, for some institutional research functions, Excel is the preferred program. Excel is
much more useful for:
1. Creating charts and graphs for the presentation of data.
SPSS output can be exported to Excel for design and use in presentations.
2. Developing projections
SPSS can provide base analyses, but projections are best done in Excel.
3. Communication of results
Most professionals in higher education are well versed in Microsoft Office applications
and are accustomed to manipulating a set of data for individual priorities. A limitation of SPSS
is the limited expertise of many professionals; therefore, SPSS output is often reformatted
into a Microsoft Office application for communication. While this is included as an advantage
of Excel, it is also an example of the versatility of SPSS.
In summary, each program has strengths and challenges when used in the practice of
institutional research. It is to our benefit that we become skilled in the use of both.
SPSS for Institutional Researchers 3
A BEGINNERS GUIDE TO SPSS 10.1
STARTING SPSS
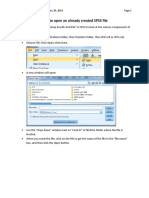
From the Start menu, choose Programs. Select SPSS from Programs Q-Z. This
organization is specific to Bucknell University. If the list of programs has not been
categorized, simply select SPSS from the Programs menu. You may also open SPSS by
double-clicking on an SPSS file.
The dialog box titled SPSS for Windows opens and asks What do you want to do?
Select Type in Data and click OK.
o Once a data file is created, you may select Open an Existing File and double
click on the file name
SPSS SCREEN LAYOUT AND FILES
SPSS users work in three windows. The contents of each can be saved as separate files.
The Data Editor Window, the first you will see when the program opens, is used to enter,
define, and analyze data. The Output Window shows the results of your analyses (useful
to print out, but not necessarily save). Finally, the Syntax Window keeps a record of
operations that are pasted. It is also possible to run analyses from the Syntax Window
(in command language).
To save the contents of a window, first make sure that window is active. Activate a
window by using the Window menu. Click File and then Save to save the contents of that
window.
SPSS uses a three-letter suffix to distinguish between file types. For ease of file
management, it would be wise to save each file with the same filename pertinent to your
project.
o .sav for Data Editor files
o .spo for Output files
o .sps for Syntax files
THE DATA EDITOR
SPSS for Institutional Researchers 4
SPSS MAIN MENU
Using the menu selections can help optimize your use of SPSS. In addition to the pulldown
menus, a number of shortcut buttons appear below the menu bar. A brief description of each
of the menu options is provided below.
File. Allows you to open, print, and save data files and results, to close files and to quit
SPSS.
Edit. Allows you to modify or copy text or graphs from the output window or modify
entries in the data window.
View. Determines which features such as toolbars and status bars are visible.
Data. Allows you to make global changes to SPSS data files, such as selecting a subset of
cases for analysis. These changes are temporary unless you explicitly save the file with
the changes.
Transform. Allows you to make changes to selected variables in the data file and to
compute new variables based on the values of existing ones. These changes are temporary
unless you explicitly change the file with the changes.
Analyze. Allows you to select the various statistical procedures.
Graphs. Allows you to create histograms, bar charts, scatterplots, boxplots, etc. All
graphs can be customized.
Utilities. Allows you to change fonts, display information about the contents of data files,
etc.
Window. Allows you arrange, select, and control the attributes of the various SPSS
windows. Also navigate among the data and the output window.
Help. Self-explanatory.
When you choose a procedure from the menus, a dialog box appears on the screen. The main
dialog box for each procedure has 3 basic components: the source variable list, the selected
variables list(s), and the command push buttons (OK, Paste, Reset, Cancel, Help).
ENTERING DATA
Before analyzing data in SPSS, a data set needs to be created. There are two ways to do this.
You can create a data set from scratch, or an existing data set can be imported from Excel.
SPSS for Institutional Researchers 5
CREATING A NEW DATA SET
The Data Editor Window (data set) is set up in a 2-tab spreadsheet format: Data View and
Variable View. All data are entered using Data View (variables in columns and cases in
rows). Variable View is used to define each variable included in the data file, but does not
contain any data.
To begin, click on the Variable View tab to define the variables you will be using in this
analysis. You can also access this sheet by double-clicking on one of the gray boxes at the
top of the columns in Data View. Several of the cells include hidden dialog boxes used to
further define the variable. If you see a gray box with three periods appear flush right when
you click on a cell, this means a hidden dialog box that can be accessed by clicking on the
gray box. Navigate the columns using the tab key.
Name The variable name is 8 characters (no symbols or spaces) or less and
will appear as a column heading in Data View. The name must begin
with a letter.
Type Several options exist in the hidden dialog box. Click on the gray box to
reveal the dialog box. The most common types are Numeric and
Dollar. You can also set Width and Decimals in this dialog box.
Width The default here is 8 spaces. You can change this to the number of
spaces your variable will take up (including a decimal). Add a space or
two for easy viewing. This can also be changed in Data View by
dragging the divider between the columns.
Decimals Set for the number of decimal places you need.
Label You may wish to specify a longer, more descriptive variable name.
This will appear in your output
Values Use for categorical data where you are using numbers to identify
groups. Click on the gray box and a dialog box will appear.
Value Type in 1
Value Label Type in Male
Click on Add
Value Type in 2
Value Label Type in Female
Click on Add
Missing Values Can be set for a certain value that will be recognized by the computer
as a missing data point (usually something like 99 that will not be
score). Click on the gray box and select Discrete missing values.
Enter an identifier in the space provided and click OK. After your data
is entered, you will go back and replace missing values with a measure
of central tendency or by using SPSS Missing Data Analysis.
Columns Set to match the Width set earlier
Scale Use the pulldown menu to change the level of measurement.
Notes: The variables should be defined in the order they appear on your raw data. This makes for
easier data entry. The data in variable view can be changed anytime. Variables can be added,
deleted, or modified as needed. Also, the Copy/Paste function can be used when defining
variables.
SPSS for Institutional Researchers 6
When the variables have been defined, click on the Data View tab to begin entering your
data.
The columns on the top of the data file will have the variable names you defined in lower
case letters. The rows of the spreadsheet represent participants (people who have supplied
data). BEFORE entering any data, be sure to assign each participant a number. Write the
number on the raw data where you will be able to find it easily. The number of the row you
are entering and the number you assigned that person should match. This will help later on if
you need to double-check someones data. Enter all data for one participant before moving
on. You may move through the data file using the arrow keys.
HOT TIP: VARIABLE SUMMARIES IN THE UTILITIES MENU
Remembering the numerical values you assigned to groups can be a challenge. SPSS
has a cheat sheet of sorts to guide you. Click on Utilities Variables. A small
dialog box will appear. For each variable, all the information included in Variable
View is summarized. Click on the variable name to reveal the information. The
dialog box will stay open as you enter data. When you are ready to close the box,
click in the X in the upper right corner.
INSERTING AND DELETING VARIABLES AND/OR CASES
The process of inserting and deleting variables and cases in SPSS is very similar to that of
other programs. To insert a Variable (column), click on the variable name to select the
column you would like to insert. (Note: the column will be inserted to the left of the column
selected). To add a case (row), select the row by clicking on the row number. (Note: the row
will be inserted above the row selected).
Data Right click on the mouse
Insert Variable Select insert variables
Insert Case insert cases
The same process can be used to rearrange variables in a data file using the copy/paste
function. Add the columns for the variable first, then copy and paste.
IMPORTING DATA FROM EXCEL
After opening the SPSS program from the Start Menu, click on Open an Existing Data
Source from SPSS for Windows dialog box and click OK. In the Open File dialog box,
choose Excel from Files of Type. Select the drive and the directory in which your Excel
file is located by navigating through the list marked Look in:. Your file should appear as one
of the choices in the list.
Open the file you want to convert. In the Opening File Options dialog box, select Read
variable names by checking the box next to it, and type in the range in which your data is
located. [A1:E11] Click on the OK button.
After the data are processed, they will appear in a spreadsheet-like window titled untitled.
Double check that all cases and variables have been read into the data set.
Note: there are some slight terminology differences in SPSS as compared to Excel. For
example, the term case is used instead of record, and variable instead of field.
SPSS for Institutional Researchers 7
SAVING YOUR DATA FILE
You may save your data file as .sav for use in SPSS using the File Save command. Exporting
your data file to other applications (such as Excel) is also an option.
File
Save as..
Choose another format from the Save as type menu.
THE OUTPUT VIEWER
Whenever you run a statistical analysis using SPSS, the results will appear in the Output
Viewer. Other information that will appear using the Output Viewer include error messages,
command syntax, and titles.
The Output Viewer will open as a separate window. The content can be saved separately
using the .spo extension.
Each table of information is called an object and can be copied to the clipboard for
placement in another document.
Analyses can be run from the Output Viewer without going back to the Data Editor
An example of the Output Viewer is shown below.
WORKING WITH THE OUTPUT VIEWER
The Output View can be edited in much the same way as any other document. Double
click on the object to activate editing. The attributes of the object can be changed to
your specifications.
You can also change all the attributes of your output using
Edit
Options
Now that we are familiar with the SPSS layout, lets work with some data.
SPSS for Institutional Researchers 8
TASK: Open the file faculty.sav from the IR public file space.
File
Open
From the pulldown menu, select admin on admin_depts (R:).
Select inst_research. Double click on the folder named
Public. Double click on the AICUP SPSS Workshop folder.
Double click on faculty.sav.
This fake data set will be used to demonstrate some of the basic tasks in SPSS. Lets review
what weve learned so far.
Notice the different variable formats that are used. Each column represents a
variable and each row is a case
SPSS for Institutional Researchers 9
MAKING NEW COMBINATION VARIABLES
For various reasons, you may wish to modify the raw data to create a new variable that
combines data from two or more existing variables. For example, you may wish to calculate
the change in faculty salary as current salary minus starting salary. A new variable can be
computed for this new variable using a Transform - Compute statement.
Transform
Compute the large dialog box below will appear In the top left corner is
a space to define the new variable you are creating. A list of all
variables in the data file is below the target variable box. The
large empty box on the top right, labeled Numeric Expression
is where you will type the formula for your new variable.
Below this box is a keypad which looks like a calculator.
To create a new variable, type its name in the Target Variable box (remember, only 8
characters are allowed). The formula defining the variable will appear in the Numeric
Expression box. You may type the formula in directly using the variable names, or you
may click over the variables from the left hand menu and the keypad.
SPSS for Institutional Researchers 10
REVERSE SCORING QUESTIONNAIRE ITEMS
For questionnaires or other assessments with negatively worded items, the data needs
to be reverse scored so that lower scores indicate more favorable responses.
For example, a question on an Alumni Survey (scored from 1-5) is negatively worded
(I will not contribute to the ___________ University Annual Fund), therefore, needs
to be reverse scored because higher scores on the assessment would indicate a greater
likelihood that the respondent will contribute to the Annual Fund. Note: To avoid
having to reverse score items, phrase all questionnaire items positively.
Reverse scored items AFTER ALL DATA ARE ENTERED. Keep the scores on the same 1-5
scale until data for all participants are entered.
In older versions of SPSS, reverse scoring was accomplished using Transform Compute
statements to change the existing variable. The procedure for this method is as
follows:
Transform
Compute
Target Variable Numeric Expression
Q5 = (6-Q5) for items rated 1-5
Q5 = (4-Q5) for items rated 0-4
Q5 = (8-Q5) for items rated 1-7
OK
YES to Change Existing Variable
In SPSS 10, you can easily reverse score items using Transform Automatic Recode.
The drawback to this method is that a new variable name must be created. Move the
variable you wish to recode into the Variables box and create a new variable name.
The variable will be inserted as the last column in your data set. Select Recode from
Highest Value and OK. You may wish to replace the original variable with the new
variable to avoid confusion.
SORTING CASES
Once your data are entered, you may find it helpful to reorganize the data in ascending or
descending order. For example, you may wish to reorder the data so that the data for all
males are grouped together. Data could also be sorted by more than one variable.
Data
Sort Cases
In the dialog box that appears, select and move the variables by which you wish to sort to the
right box. Select whether you want to sort in Ascending or Descending order and click OK.
SELECTING CASES
For some analyses, you may wish to analyze only a subset of a data file. This can be done
using the Select Cases menu option. Cases can be temporarily or permanently removed from
the data file. For example, if you wanted to explore data for Assistant Professors only, the
Professor, Associate Professors, and Instructors can be removed from the data file.
SPSS for Institutional Researchers 11
Data
Select Cases
On the left are the variables in your data file. On the right are several options to select the
cases. Selecting an option will bring up another dialog box to further specify your
preferences.
Click on the If condition is satisfied button. You will see that the If button is now active.
Click this button to open a second dialog box where you will specify the minimum criteria for
keeping a case. To use the rank example given above, select the Rank variable from the left
variable list and click the arrow to bring the variable over to the other side. Now add the
criteria. To keep only the Assistant Professors, the statement should read Rank = 3. Click
Continue.
The next step is to specify how you want the unused data treated. In the Unselected Cases
Are box, you have 2 options:
Filtered: Unselected cases are not deleted from the data file. A new variable is
created (filter_$). Cases that meet your criteria are coded with a 1, unselected cases are
coded with a 0.
Deleted: Unselected cases are removed from the data file. If the data file is
subsequently saved, the cases will be permanently lost.
Right now, we are not going to select any specific cases, so well return to the full
data file.
Data
Select Cases
Reset
SPSS for Institutional Researchers 12
DESCRIPTIVE STATISTICS
The first step in data analysis is to double check your data for entry errors. In SPSS,
this is easily done with basic descriptive statistics. Descriptives are also useful to
summarize your data using measures of central tendency and variance.
Double Checking Your Data File
When all of your data are entered, run the following program to double check the entries
before running any statistical analyses.
Analyze
Descriptive Statistics
Frequencies
All the variables in your data set will be listed on the left in the order in
which they were defined. Highlight and move all the variables you wish
to analyze to the Variables box on the right (using the little arrow
pointing right between the boxes to move the variables over).
OK
Gender
4 40.0 40.0 40.0
6 60.0 60.0 100.0
10 100.0 100.0
Male
female
Total
Valid
Frequency Percent Valid Percent
Cumulative
Percent
Printing this out and looking over it carefully to make sure the data have been entered
correctly is helpful. Look for any data points that are not possible given your range of data (a
22 when your range is 1-5). Make sure the values you have are reasonable (do you have
someone in your sample that is 123 years old?).
HOT TIP: BE SURE TO SAVE YOUR DATA FILE OFTEN!!!
Click File Save or click the disk icon from the menu bar.
Descriptive Statistics
Analyze
Descriptive Statistics
Descriptives
Highlight the variables you want to analyze and move them over to the
Variables box
Options
Check the ones you want or uncheck the ones you dont.
OK
SPSS for Institutional Researchers 13
Descriptive Statistics
10 1 3 1.50 .707
10 25 65 42.60 12.510
10 1 10 5.50 3.028
10
Tenure Status
Age
Discipline
Valid N (listwise)
N Minimum Maximum Mean Std. Deviation
Several important pieces of information are included in this output. The number of cases is
listed under N. The range is given in the Minimum and Maximum columns. Central tendency
and variance are in the Mean and Std. Deviation columns, respectively.
HOT TIP: RESULTS COACH
Each column in the Output Viewer has a Results Coach that will assist you in
interpreting the statistic. Right click on your mouse over the term you need help
on. The SPSS tutorial for that topic will open.
CROSSTABS
Frequencies and descriptives can provide you important information about your variables. The
limitation is that each variable is analyzed independently. For example, you can determine
the number of males and females AND the number of faculty in each rank. You cannot
determine the number of men and women IN each rank. This type of analysis can be
completed using Crosstabs.
Analyze
Descriptive Statistics
Crosstabs
The Crosstabs dialog box will appear with the variables defined on the left. Select Gender for
Row and Rank for Column to produce a crosstabulation of Gender by Rank.
The Statistics button provides other options for analyzing the data beyond a simple count.
The Cells button allows you to select additional detail for your analysis.
SPSS for Institutional Researchers 14
Case Processing Summary
10 100.0% 0 .0% 10 100.0% Gender * Rank
N Percent N Percent N Percent
Valid Missing Total
Cases
Gender * Rank Crosstabulation
3 0 1 4
2.0 .8 1.2 4.0
75.0% .0% 25.0% 100.0%
60.0% .0% 33.3% 40.0%
30.0% .0% 10.0% 40.0%
2 2 2 6
3.0 1.2 1.8 6.0
33.3% 33.3% 33.3% 100.0%
40.0% 100.0% 66.7% 60.0%
20.0% 20.0% 20.0% 60.0%
5 2 3 10
5.0 2.0 3.0 10.0
50.0% 20.0% 30.0% 100.0%
100.0% 100.0% 100.0% 100.0%
50.0% 20.0% 30.0% 100.0%
Count
Expected Count
% within Gender
% within Rank
% of Total
Count
Expected Count
% within Gender
% within Rank
% of Total
Count
Expected Count
% within Gender
% within Rank
% of Total
Male
female
Gender
Total
Professor
Associate
Professor
Assistant
Professor
Rank
Total
SPSS for Institutional Researchers 15
INFERENTIAL STATISTICS
Inferential statistics are used to makes inferences about characteristics of the population
based on characteristics of a sample. Various parametric and nonparametric statistics are
available in SPSS to test numerous hypotheses. The availability of rigorous statistical
procedures beyond simple descriptive statistics distinguishes SPSS from spreadsheet programs
such as Microsoft Excel. A summary of the selection criteria for parametric and nonparametric
tests is available in Appendix A.
CHI SQUARE
The chi square is a non-parametric test used to determine the differences in two
categorical variables.
Analyze
Descriptives
Crosstabs
Highlight the and move Gender and Rank to be Row and Column boxes
Statistics
Chi Square
OK
The following objects will appear in the viewer:
Case Processing Summary
10 100.0% 0 .0% 10 100.0% Gender * Rank
N Percent N Percent N Percent
Valid Missing Total
Cases
Gender * Rank Crosstabulation
Count
3 1 4
2 2 2 6
5 2 3 10
Male
female
Gender
Total
Professor
Associate
Professor
Assistant
Professor
Rank
Total
SPSS for Institutional Researchers 16
Chi-Square Tests
2.222
a
2 .329
2.911 2 .233
.711 1 .399
10
Pearson Chi-Square
Likelihood Ratio
Linear-by-Linear
Association
N of Valid Cases
Value df
Asymp. Sig.
(2-sided)
6 cells (100.0%) have expected count less than 5. The
minimum expected count is .80.
a.
Interpreting the output: The above object includes the results for the test of the hypothesis
that the numbers of male and female faculty in each rank are significantly different. The
finding is based on the differences in expected and observed frequencies.
CORRELATION
Correlational procedures are used to determine the linear relationship between 2 or more
continuous variables.
Correlation is very common in institutional research for analyzing survey results.
Correlation coefficients range from -1 to +1 with strength of association indicated by
higher absolute values. The sign of the correlation describes the type of relationship.
o Positive: as one variable increases, so does the other
o Negative: increases in one variable are associated with a decrease in the other
Analyze
Correlate
Bivariate
Highlight the variables you want to correlate and move them to the Variables
box. (For example, Age and 2001 Salary)
Select either Pearson (parametric) or Spearman (non-parametric). Pearson is
the default, therefore, if you want Spearman, be sure to uncheck Pearson. If
you select both, youll get both. (Note: although our N = 10, parametric
statistics are used for example purposes)
OK
SPSS for Institutional Researchers 17
Correlations
1 .752* -.617
. .012 .057
10 10 10
.752* 1 -.506
.012 . .135
10 10 10
-.617 -.506 1
.057 .135 .
10 10 10
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Age
2001 Salary
Beginning Salary
Age 2001 Salary
Beginning
Salary
Correlation is significant at the 0.05 level (2-tailed).
*.
Interpreting the output: The correlation matrix includes 9 cells, although only three are of
interest. The principal diagonal consists of the correlation of each variable with itself.
Statistically significant correlations are flagged by SPSS with one (.05 level) or two (.01 level)
asterisks.
TESTING THE DIFFERENCES BETWEEN MEANS
Group differences can be tested several ways in SPSS.
Appendix A provides an overview of the selection criteria for each analysis.
One Sample t-test
Used to compare a single sample with a specified value.
Example: the difference in SAT scores for first year students with the national mean.
Example: differences in assistant professor salary at your school as compared with the
median of your peer group.
o Use Select Cases to analyze only the assistant professors
Analyze
Compare Means
One-Sample t-test
Select variable to analyze and move it to the Test Variable(s) box
Insert the hypothesized value in the Test Value box
One-Sample Statistics
3
$51,607.67
$526.428 $303.933 Beginning Salary
N Mean Std. Deviation
Std. Error
Mean
One-Sample Test
51.352 2 .000 $15,607.67
$14,299.95 $16,915.39 Beginning Salary
t df Sig. (2-tailed)
Mean
Difference Lower Upper
95% Confidence
Interval of the
Difference
Test Value = 36000
SPSS for Institutional Researchers 18
Interpreting the output: Because we selected only the assistant professors to analyze, N
decreased from 10 to 3. The descriptive statistics are provided in the first object. The second
object specifies the Test Value and other criteria for evaluating the t test.
Independent Groups t-ratio
Used to determine the differences in the means of two groups on one dependent variable
Example: Differences in male and female salaries.
Analyze
Compare Means
Independent Samples t test
Highlight the Dependent Variable(s) and move to Test Variable box
Highlight the Independent Variable(s) and move to Grouping Variable box
Click on Define Groups (use codes defined in Variable View) and a small dialog
box will appear
Type in 1
Type in 2 (or other 2 groups being compared)
Continue
OK
Group Statistics
4 $81,160 $18,861 $9,430
6 $72,436 $21,262 $8,680
Gender
Male
female
2001 Salary
N Mean Std. Deviation
Std. Error
Mean
Independent Samples Test
.166 .694 .663 8 .526 $8,724 13164.74 -$21,634 $39,082
.681 7.155 .517 $8,724 12817.11 -$21,451 $38,899
Equal variance
assumed
Equal variance
not assumed
2001 Salar
F Sig.
Levene's Test for
Equality of Variances
t df Sig. (2-tailed)
Mean
Difference
Std. Error
Difference Lower Upper
95% Confidence
Interval of the
Difference
t-test for Equality of Means
HOT TIP: CELL PROPERTIES
Each cell in the Output Viewer has a set of defaults for viewing. Especially when
analyzing salary, data wont fit in the cell as it is defined. In this case, ******** will
appear instead. To redefine the cell properties, double click on the cell(s) you
wish to change. This will bring up the Formatting Toolbar. Click once again on the
cell to highlight the contents (a shadow box will appear around the cell). One
option is to change the font size to something smaller. Another option is to change
the cell properties. Right click and select Cell Properties. Select the variable type
(Currency) and change the decimal places to 0. Click Apply, then OK
SPSS for Institutional Researchers 19
Interpreting the output: Again, descriptive statistics are displayed in the first object. In the
second object, the specific test criteria are included. For this example, the equal variances
can be assumed (indicated by a nonsignificant Levenes test).
Repeated Measures (Paired Samples t-test)
A paired samples t-test is used to compare 2 scores from the same person.
For example, differences in willingness to contribute to the Annual Fund in their senior
year as compared to 5 years after graduation. The same respondent is providing both data
points.
Data must be entered in Data View as 2 separate variables. Be sure to clearly label each.
For our data, compare the differences in beginning and current salary
Analyze
Compare Means
Paired Samples
Highlight and click over the 2 variables: Select one, hold down the shift key
and select the second variable.
OK
Paired Samples Statistics
$49,002 10 $9,905 $3,132
$75,926 10 $19,749 $6,245
Beginning Salary
2001 Salary
Pair
1
Mean N Std. Deviation
Std. Error
Mean
Paired Samples Correlations
10 -.506 .135
Beginning Salary
& 2001 Salary
Pair
1
N Correlation Sig.
SPSS for Institutional Researchers 20
Paired Samples Test
-$26,923 $26,196 $8,284 -$45,663 -$8,183 -3.250 9 .010
Beginning Salary
- 2001 Salary
Pair
1
Mean Std. Deviation
Std. Error
Mean Lower Upper
95% Confidence
Interval of the
Difference
Paired Differences
t df Sig. (2-tailed)
ONE-WAY ANALYSIS OF VARIANCE (ANOVA)
Used to compare three or more means on one dependent variable
2-step process
1. Omnibus F test to determine differences among means
2. Post hoc tests to determine where the significance lies
Analyze
Compare Means
One-Way ANOVA
2001 Salary --> Dependent Variable Box
Rank ---> Factor Box
Continue
Post Hoc
Scheffe
Tukey
Continue
Options
Descriptives
Homogeneity of Variance
Continue
OK
ANOVA OUTPUT
Descriptives
2001 Salary
5 $93,377 $7,177 $3,210 $84,466 $102,289 $89333 105900
2 $67,249 $1,061 $751 $57,712 $76,785 $66498 $67999
3 $52,624 $629 $363 $51,062 $54,186 $51898 $52987
10 $75,926 $19,749 $6,245 $61,798 $90,053 $51898 105900
Professor
Associate Professor
Assistant Professor
Total
N Mean Std. Deviation Std. Error Lower Bound Upper Bound
95% Confidence Interval for
Mean
Minimum Maximum
SPSS for Institutional Researchers 21
Test of Homogeneity of Variances
2001 Salary
2.121 2 7 .190
Levene
Statistic df1 df2 Sig.
ANOVA
2001 Salary
3.30E+09 2 1651134765 55.579 .000
2.08E+08 7 29708078.76
3.51E+09 9
Between Groups
Within Groups
Total
Sum of
Squares df Mean Square F Sig.
Multiple Comparisons
Dependent Variable: 2001 Salary
$26,129* $4,560 .002 $12,698 $39,559
$40,753* $3,980 .000 $29,030 $52,476
-$26,129* $4,560 .002 -$39,559 -$12,698
$14,625 $4,976 .050 -$29 $29,278
-$40,753* $3,980 .000 -$52,476 -$29,030
-$14,625 $4,976 .050 -$29,278 $29
$26,129* $4,560 .002 $12,092 $40,166
$40,753* $3,980 .000 $28,501 $53,006
-$26,129* $4,560 .002 -$40,166 -$12,092
$14,625 $4,976 .060 -$691 $29,940
-$40,753* $3,980 .000 -$53,006 -$28,501
-$14,625 $4,976 .060 -$29,940 $691
(J) Rank
Associate Professor
Assistant Professor
Professor
Assistant Professor
Professor
Associate Professor
Associate Professor
Assistant Professor
Professor
Assistant Professor
Professor
Associate Professor
(I) Rank
Professor
Associate Professor
Assistant Professor
Professor
Associate Professor
Assistant Professor
Tukey HSD
Scheffe
Mean
Difference
(I-J) Std. Error Sig. Lower Bound Upper Bound
95% Confidence Interval
The mean difference is significant at the .05 level.
*.
Interpreting the Output:
The first object in the output is the basic descriptive statistics we requested.
The second object is the Levenes Test for Homogeneity of Variance. Remember, this
should be nonsignificant (p > .05), indicating that the group variances are similar.
The ANOVA box includes the F ratio and significance value for our analysis. In this
example, F = 55.579 (p = .000). The means of the ranks are significantly different;
however, we dont know which means were significantly different.
Examine the Multiple Comparisons box. For Tukey and Scheffe, the mean difference,
standard error, significance values, and confidence intervals are included for each
combination of independent variables. Means that are significantly different are labeled
with an asterisk. For our example, the mean salary for professors was significantly higher
than the means for associate and assistant professors; however, the salaries for associate
and assistant professors were not significantly different.
SPSS for Institutional Researchers 22
CREATING CHARTS AND GRAPHS IN SPSS
An accompanying chart or graph exists for nearly every statistical analysis offered in SPSS. All
charts and graphs are stored in the Output Viewer. Click on Graphs from the top menu bar.
Notice the range of options available!
There are two primary types of graphing options: Regular Graphs, and Interactive Graphs.
Regular graphs are much more common in IR and will be the focus here.
Regular Graphs
These charts can be obtained using the Graphs menu from the toolbar or by requesting a
graph when specifying a statistical procedure in the Frequencies menu.
Because inferential procedures assume a normal distribution, creating a quantile plot is useful
to inspect the distribution of the data.
Graphs
Q-Q
Move the variable to examine over to the Variable box
Select Normal from the Test Distribution pulldown menu
OK
The data comes from a normal
distribution if the dots in the plot fall on
a straight line (at least approximately so)
Normal Q-Q Plot of Age
Observed Value
70 60 50 40 30 20
E
x
p
e
c
t
e
d
N
o
r
m
a
l
V
a
l
u
e
70
60
50
40
30
20
SPSS for Institutional Researchers 23
CREATING A BAR GRAPH
Graphs
Bar
Select simple, clustered, or stacked
Define
Select the variable to graph and move it to the Category Axis box and select
what you want the bars to represent.
Titles
Choose a title for the bar graph
OK
OK
Number of Faculty in Each Rank
Rank
Assistant Professor
Associate Professor
Professor
C
o
u
n
t
5.5
5.0
4.5
4.0
3.5
3.0
2.5
2.0
1.5
SPSS for Institutional Researchers 24
EDITING A BAR GRAPH
In the Output Viewer, double click on the bar graph to open the Chart Editor Window. The
chart attributes, like alignment and color, are changed in this window.
The axis labels and title can be centered by double clicking on the text and selecting
center from the Title Justification pull down menu.
Menu Items
o File Menu: Save a template or export a graph
o Edit Menu: Copy chart or change options
o Gallery: Different types of charts available
o Chart Menu: Functions for editing title footnote, legend, etc.
o Series Menu: Displaying and transporting serial data
o Analyze Menu: available statistical procedures
o Help
Shortcut Icons (Buttons):
o Color (looks like a crayon): change the color of the bars by clicking on the bar and
choosing a new color from the color palette.
o Bar Style: 3-D, Drop Shadow options
o Bar Label Styles: include data labels in the bars
o Marker: Choose different styles for the markers
o Swap Axes
o Go to Case
o Go to Data
CREATE BAR GRAPHS FOR CONDITIONAL DISTRIBUTIONS
Data
Split File
Compare Groups
Move Gender to the Groups Based On box
Graphs
Bar
Simple
Summaries for groups of cases
Define
Bars represent % of cases
Move Rank to the Category Axis box
Options
Display Groups defined by missing values
GENDER: 1 Male
Rank
Assistant Professor Professor
P
e
r
c
e
n
t
100
80
60
40
20
0
GENDER: 2 female
Rank
Assistant Professor
Associate Professor
Professor
P
e
r
c
e
n
t
100
90
80
70
60
50
40
30
20
10
0
To select all cases again, go back to Data Split File. Select Analyze all cases, do not
create groups.
SPSS for Institutional Researchers 25
CREATING A CLUSTERED BAR GRAPH
Clustered bar graphs are another way of comparing conditional distributions without
splitting files. For this example, use rank as the category variable and define clusters by
gender.
Clustered graphs may be made to compare two groups only.
Graphs
Bar
Clustered
Define
Move Rank to the Category Variable box and Gender to the Define Clusters By
box
Add a title if desired
OK
Rank
Assistant Professor Associate Professor Professor
C
o
u
n
t
3.5
3.0
2.5
2.0
1.5
1.0
.5
0.0
Gender
Male
female
CREATING A REGULAR PIE CHART
Graphs
Pie
Select how the data will be grouped
Define
Move the variable to chart over to the Define Slices By box
Click on Titles to add a title
OK
OK
SPSS for Institutional Researchers 26
CREATING A SIMPLE SCATTERPLOT
Graphs
Scatter
Move the variables for the Y and X axes to the appropriate boxes
Add a title (if desired)
OK
OK
SPSS for Institutional Researchers 27
The Relationship Between Age and Current Salary
Bucknell University
2001 Salary
110000 100000 90000 80000 70000 60000 50000
A
g
e
70
60
50
40
30
20
Adding the Regression Line
Open the Chart Editor Window for the scatterplot
Chart
Options
Fit Line Total
Close Window (x in upper right corner)
2001 Salary
110000 100000 90000 80000 70000 60000 50000
A
g
e
70
60
50
40
30
20
SPSS for Institutional Researchers 28
Scatterplots for Subgroups
Allows you to examine the strength of association between groups
Graphs
Scatter
Move the variables for the Y and X axes to the appropriate boxes
Move categorical variable to Set Markers By box
Add a title (if desired)
OK
OK
Open the Chart Editor Window for the scatterplot
Chart
Options
Fit Line Subgroups
If printing in black and white, change the marker for one of the groups by
selecting a marker. Then, click the Marker shortcut button, choose another
option. Click Apply, then Close.
Close Window (x in upper right corner)
2001 Salary
110000 100000 90000 80000 70000 60000 50000
A
g
e
70
60
50
40
30
20
Gender
female
Male
SPSS for Institutional Researchers 29
Creating Histograms
Graphs
Histogram
Move the variable to graph into the Variable box
Check the box to overlay the normal curve
2001 Salary
110000.0
100000.0
90000.0
80000.0
70000.0
60000.0
50000.0
Sample Histogram
5
4
3
2
1
0
Std. Dev = 19749.05
Mean = 75925.5
N = 10.00
SPSS automatically creates intervals based on the data. You may create your own
intervals using the Chart Editing Window. Double click on the histogram to activate editing.
Chart
Axis
Select Interval
The dialog box below will appear.
Under Intervals, select Custom and click define.
SPSS for Institutional Researchers 30
Define the number and width of intervals and Click OK.
Limitations of SPSS graphsThey arent very pretty /however; simplicity is favored
in the presentation of graphs and charts. The most important characteristic of a
statistical graph is to portray the data accurately and not be misleading. Some
jazzed up graphs can distort reality. While maintaining simplicity, SPSS offers colors
patterns and shapes for markers that can improve the presentation of data. For
multimedia presentations, yu may find that other programs (Excel, PowerPoint,
SigmaPlot, Fireworks) provide better visual presentations of the data.
SPSS for Institutional Researchers 31
ADVANCED SPSS 10.1 STATISTICAL PROCEDURES
TASK: Open the file retention.sav
File
Open
From the pulldown menu, select admin on
admin_depts (R:). Select inst_research. Double click
on the folder named Public. Double click on the
AICUP SPSS Workshop folder. Double click on
retention.sav.
This fake data set will be used to demonstrate some of the advanced tasks in SPSS,
such as multiple linear regression, logistic regression and discriminant analysis.
LINEAR REGRESSION
As part of enrollment projections, first year GPA (a measure of academic success), and
retention are in important variables to consider. Well use this fake data set to develop
regression models to find the variables that contribute to first year GPA.
Linear regression analysis describes statistical relationships between variables.
Regression analysis is used to describe the distribution of values of one variable, the
dependent or response variable, as a function of otherindependent, or explanatory,
or predictorvariables.
SPSS for Institutional Researchers 32
The purposes of regression analysis are:
to find a good fitting model for the response mean
to word the questions of interest in terms of the regression coefficients
to estimate the parameters with the available data
to employ appropriate inferential procedures for answering the questions of interest and
for expressing the uncertainty in the answers (p-values, confidence levels)
Well develop a model for predicting first year GPA based on the SAT verbal score, the SAT
math score and the high school GPA.
Graphical Analysis
The first step in any data analysis is to plot the data. We can produce a matrix scatterplot
(an array of two-dimensional scatterplots) to examine the relationship between first year GPA
and each of the independent variables as well as the relationship between each pair of
predictors.
Graphs
Scatter
Matrix
Define
Move the variables to be plotted to Matrix Variables box
Add a title if desired
OK
First Year GPA
F
i
r
s
t
Y
e
a
r
G
P
A
S
A
T
V
e
r
b
a
l
SAT Verbal
S
A
T
M
a
t
h
SAT Math
First Year GPA
H
i
g
h
S
c
h
o
o
l
G
P
A
SAT Verbal SAT Math
High School GPA
High School GPA
The variable listed in the row corresponds to the variable plotted in the vertical axis in the
scatterplots in that row of the array. It is only necessary to examine the scatterplots above
the diagonal.
The scatterplots suggest that there is a positive linear association between first year GPA and
high school GPA, but no association between first year GPA and SAT-V and SAT-M scores.
Also, there seem to be no relationships among the independent variables (This is good
because collinearity poses a problem in regression).
SPSS for Institutional Researchers 33
The regression model:
Data. The dependent and independent variables should be quantitative. Categorical
variables, such as gender, ethnicity, or major field of study, need to be recoded to binary
(dummy) variables or other types of contrast variables.
Assumptions. For each value of the independent variable, the distribution of the dependent
variable must be normal. The variance of the distribution of the dependent variable should be
constant for all values of the independent variable. The relationship between the dependent
variable and each predictor variable should be linear, and all observations should be
independent.
For each student in our data set his/her first year GPA can be represented by the equation
FYGPA =
0
+
1
SATV +
2
SATM +
3
HSGPA + error
where the errors are independent normal variables with mean 0 and standard deviation ,
unknown. Here
0
,
1
,
2
and
3,
and represent unknown parameters that will be estimated
from the data. The process of estimating these parameters is commonly known as fitting the
model.
Analyze
Regression
Linear
Grade Point Average Dependent (must be a continuous variable)
SAT Verbal Score, SAT Math Score, High School Grade Point Average
Independent(s)
Method Enter
Statistics
Estimates
Confidence intervals
Model Fit
Descriptives
Continue
Plots
SRESID Y:
ZPRED X:
Histogram
Normal Probability Plot
Produce all partial plots
Continue
Save
Predicted values
Unstandardized
Prediction Intervals
Mean
Individual
Continue
OK
SPSS for Institutional Researchers 34
HOT TIP: DIALOG BOX PROPERTY
Click your right mouse button
on any item in the dialog box
for a description of the item.
LINEAR REGRESSION OUTPUT
Descriptive Statistics
3.3564 .43558 50
536.30 131.617 50
605.90 114.590 50
3.4738 .41038 50
Grade Point
Average - First Year
SAT Verbal Score
SAT Math Score
High School Grade
Point Average
Mean Std. Deviation N
Correlations
1.000 -.063 -.082 .560
-.063 1.000 .156 .045
-.082 .156 1.000 -.095
.560 .045 -.095 1.000
. .332 .286 .000
.332 . .139 .378
.286 .139 . .257
.000 .378 .257 .
50 50 50 50
50 50 50 50
50 50 50 50
50 50 50 50
Grade Point
Average - First Year
SAT Verbal Score
SAT Math Score
High School Grade
Point Average
Grade Point
Average - First Year
SAT Verbal Score
SAT Math Score
High School Grade
Point Average
Grade Point
Average - First Year
SAT Verbal Score
SAT Math Score
High School Grade
Point Average
Pearson Correlation
Sig. (1-tailed)
N
Grade Point
Average -
First Year
SAT Verbal
Score
SAT Math
Score
High School
Grade Point
Average
Model Summary
.567
a
.321 .277 .37043
Model
1
R R Square
Adjusted
R Square
Std. Error of
the Estimate
Predictors: (Constant), High School Grade Point
Average, SAT Verbal Score, SAT Math Score
a.
SPSS for Institutional Researchers 35
ANOVA
b
2.985 3 .995 7.251 .000
a
6.312 46 .137
9.297 49
Regression
Residual
Total
Model
1
Sum of
Squares df Mean Square F Sig.
Predictors: (Constant), High School Grade Point Average, SAT Verbal Score, SAT
Math Score
a.
Dependent Variable: Grade Point Average - First Year
b.
Coefficients
a
1.472 .574 2.565 .014 .317 2.627
-2.84E-04 .000 -.086 -.697 .489 -.001 .001
-5.72E-05 .000 -.015 -.122 .904 -.001 .001
.596 .130 .562 4.596 .000 .335 .858
(Constant)
SAT Verbal Score
SAT Math Score
High School Grade
Point Average
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardi
zed
Coefficien
ts
t Sig. Lower Bound Upper Bound
95% Confidence Interval for B
Dependent Variable: Grade Point Average - First Year
a.
Regression Standardized Residual
2
.0
0
1
.7
5
1
.5
0
1
.2
5
1
.0
0
.7
5
.5
0
.2
5
0
.0
0
-.2
5
-.5
0
-.7
5
-1
.0
0
-1
.2
5
-1
.5
0
-1
.7
5
-2
.0
0
-2
.2
5
Histogram
Dependent Variable: Grade Point Average - Fir
F
r
e
q
u
e
n
c
y
10
8
6
4
2
0
Std. Dev = .97
Mean = 0.00
N = 50.00
Partial Regression Plot
Dependent Variable: Grade Point Average - F
SAT Verbal Score
300 200 100 0 -100 -200 -300
G
r
a
d
e
P
o
in
t
A
v
e
r
a
g
e
-
F
ir
s
t
Y
e
a
r
1.0
.5
0.0
-.5
-1.0
Normal P-P Plot of Regression Stand
Dependent Variable: Grade Point Ave
Observed Cum Prob
1.00 .75 .50 .25 0.00
E
x
p
e
c
t
e
d
C
u
m
P
r
o
b
1.00
.75
.50
.25
0.00
Partial Regression Plot
Dependent Variable: Grade Point Average - F
SAT Math Score
300 200 100 0 -100 -200 -300 -400
G
r
a
d
e
P
o
in
t
A
v
e
r
a
g
e
-
F
ir
s
t
Y
e
a
r
1.0
.5
0.0
-.5
-1.0
Scatterplot
Dependent Variable: Grade Point Average - Fir
Regression Standardized Predicted Value
2 1 0 -1 -2 -3 -4
R
e
g
r
e
s
s
io
n
S
t
u
d
e
n
t
iz
e
d
R
e
s
id
u
a
l
3
2
1
0
-1
-2
-3
Partial Regression Plot
Dependent Variable: Grade Point Average - F
High School Grade Point Average
1.0 .5 0.0 -.5 -1.0 -1.5
G
r
a
d
e
P
o
in
t
A
v
e
r
a
g
e
-
F
ir
s
t
Y
e
a
r
1.0
.5
0.0
-.5
-1.0
SPSS for Institutional Researchers 36
Interpreting the Output
Descriptive statistics. Provides the means, standard deviations and number of
observations for all the variables in the analysis.
Correlations. Shows the correlations for all the variables in the analysis. The
correlation between HSGPA and FYGPA is .560. This is the only significant correlation
on the table.
Model Summary. This table gives the multiple R value, the R-squared value, the
adjusted R-squared value and the standard error of the estimate. Notice that the
multiple R is not the same as the correlation coefficient and it will always be a
positive number. The R-squared and the adjusted R-squared values are descriptive
measures of goodness of fit of the model. Values close to 1 indicate a good fit. In
multiple regression it is better to use the adjusted R-squared because it takes into
account the number of independent variables in the model. Including additional
variables in a regression models will always increase the value of R-squared.
ANOVA. This table provides the value of the F-statistic and its significance. In this
example F= 7.251 (p = .000). There is a linear relationship between first year GPA and
the entire set of independent variables, Verbal SAT scores, Math SAT scores and High
School GPA.
Coefficients. This table provides the (partial) regression coefficients, their standard
errors and confidence intervals for each of them. The least squares regression
equation, i.e., the regression model is:
First year GPA = 1.472 - 2.844E-04 SAT Verbal Score - 5.723E-05 SAT
Math Score + .596 High School GPA.
This equation can be used to predict the first year GPA for an entering student
with say, SAT-V = 452, SAT-M = 500, and HSGPA = 3.70
Pred. FY GPA = 1.472 (2.844E-04) (452) (5.723E-05) (500) + (.596) (3.70) = 3.52.
The regression equation also tells us that if we compare two students with high school
GPAs say, 2.50 and 3.50, respectively and both with SAT-V = 452, and SAT-M = 500,
then the predicted first year GPA for the second student will be .596 higher than that
of the first one.
The coefficients table also provides the value of the t-statistic and its
significance for each of the variables in the regression equation. The
hypothesis being tested in each case is whether each of the independent
variables is linearly related to the dependent variable. In this example, only
high school GPA is linearly related to first year GPA.
The beta coefficients are (to some extent) indicators of the relative importance of
the independent variables in the model. However, their values are contingent on the
other independent variables in the model. Beta coefficients are affected by the
correlations of the independent variables and do not in any absolute sense reflect the
importance of the various independent variables.
The graphs shown on the first row of the handout are from left to right: histogram of
standardized residuals, normal probability plot of the residuals, and the plot of the
studentized residuals versus the standardized predicted values. When the
standardized residuals are a sample from a normal distribution the dots in the normal
probability plot will fall on a diagonal straight line. In this example the normality
assumption seems to hold. The plot of the studentized residuals is used to determine
whether the relationship is linear and whether the variance of the residuals is
constant, that is, does not depend on the values of the independent variables.
SPSS for Institutional Researchers 37
Because of its random pattern, this plot indicates that the relationship between first
year GPA and the independent variables is linear and that the variance of the residuals
is constant.
In the second row we have the partial plots we requested. Partial plots are useful
when studying the contribution of one of the independent variables after one or more
independent variables are already included in the regression model. The partial plots
indicate that neither verbal nor math SAT scores are linearly related to first year GPA
after accounting for the other two variables. The first two plots show a random
pattern. The partial plots also indicate that after controlling for verbal and math SAT
scores the first year GPA is linearly related to the high school GPA. Notice the upward
trend in the last plot.
The Save command we issued created several new variables that are stored in the
data file. The unstandardized predicted values (pre_1), the lower and upper
endpoints of the confidence interval for the mean (lmci_1 and umci_1, respectively),
and the lower and upper endpoints of the prediction interval for an individual
observation (lici_1 and uici_1, respectively). For instance if we consider the
subpopulation of all entering students with SAT-V = 486, SAT-M = 556 and HSGPA =
3.10 then an estimate of their mean first year GPA is 3.15 and we are 95% confident
that their mean first year GPA will be between 2.99 and 3.31. On the other hand, if
we look at a single student with SAT-V = 486, SAT-M = 556 and HSGPA = 3.10 we
predict that his/her first year GPA will be 3.15 and we are 95% confident that his/her
first year GPA will be between 2.39 and 3.91.
REFINING THE REGRESSION MODEL
From the previous analysis we learned that although all three variables together are helpful
for predicting first year GPA we also learned that SAT scores do not seem to be good
determinants of the first year GPA. Is it possible to build a leaner model that does a good
job predicting first year GPA? There are a variety of techniques for variable selection that
facilitate models building. All of these procedures are easily implemented in SPSS. A
summary of these techniques follows.
Enter. All the explanatory variables are entered into the equation (this is the one we used in
our example).
SPSS for Institutional Researchers 38
Forward Selection.
The first variable considered for entry into the equation is the one with the largest
positive or negative correlation with the dependent variable. The F test for the
hypothesis that the coefficient of the entered variable is 0 (H
0
: = 0) is then calculated.
To determine whether this variable (and each succeeding variable) is entered, the F value
is compared to an established criterion. The default criterion in SPSS is to compare the p-
value of this test with the probability of F-to-enter (PIN), set at .05 by default. That is, if
the p-value for the test is less than .05 the variable is entered into the equation. If the
first variable selected for entry meets the criterion for inclusion, forward selection
continues. Otherwise, the procedure terminates with no variables in the equation. An
alternative criterion is to compare the value of the F-statistic to a predetermined value
(F-to-enter, SPSS default is 3.84). If the (extra sum of squares) F-statistic > 3.84, the
variable is entered into the equation.
The partial correlation between the dependent variable and each of the independent
variables not currently in the equation adjusted for the independent variables currently in
the equation are examined. This partial correlation coefficient measures the strength of
the association between the response variable and each of the explanatory variables not
currently in the equation after removing the effect of the variables currently in the
equation. The variable with the largest partial correlation (positive or negative) is the
next candidate. If the criterion is met, this variable is entered into the equation and the
procedure is repeated. The procedure stops when there are no other variables that meet
the entry criterion.
Backward Elimination
This procedure starts with all the variables in the equation and sequentially removes
them. Instead of entry criteria, removal criteria are used. The default SPSS criterion for
removal is the maximum probability of F-to-remove (POUT) that a variable can have. The
default POUT value is .10. For each of the variables in the equation the p-value of the test
H
0
: = 0 against H
a
: 0 is computed. The variable with the largest p-value greater than
.10, is removed from the equation. The alternative criterion for removal is to compare
the (extra sum of squares) F-statistic to a specified value (F-to-remove, SPSS default is
2.71). The variable is removed if F-statistic < 2.71.
A new model with the remaining independent variables is fitted, and the elimination
procedure continues until there are no variables in the equation that meet the removal
criterion.
Stepwise Regression.
This procedure is a combination of the backward and forward procedures. The first
variable is selected in the same manner as in forward selection. If the variable fails to
meet the entry requirement (PIN or F-to-enter) the procedure terminates with no
explanatory variables in the equation. If a variable passes the entry criterion, the second
variable is selected based on the highest partial correlation. If it passes entry criteria, it
also enters the equation.
After the first variable is entered, stepwise selection differs from forward selection: the
first variable is examined to see whether it should be removed according to the removal
criterion POUT (or F-to-remove) as in backward elimination.
In the next step variables not yet in the equation are examined for entry. After each step,
variables already in the equation are examined for removal. Variables are removed until
none remain that meet the removal criterion. To prevent the same variable from being
repeatedly entered and removed, the PIN (F-to enter) must be less (greater) than POUT
(F-to remove). Variable selection terminates when no more variables meet entry and
removal criteria.
SPSS for Institutional Researchers 39
Analyze
Regression
Linear
Grade Point Average Dependent
SAT Verbal Score, SAT Math Score, High School Grade Point Average
Independent(s)
Method Forward (Backward, Stepwise, or Enter as desired)
Statistics
Estimates
Confidence intervals
Model Fit
R-square change
Continue
Save
Predicted values
Unstandardized
Continue
OK
Forward Selection
Variables Entered/Removed
a
High School
Grade Point
Average
.
Forward (Criterion:
Probability-of-F-to-enter
<= .050)
Model
1
Variables
Entered
Variables
Removed Method
Dependent Variable: Grade Point Average - First Year
a.
Model Summary
b
.560
a
.313 .299 .36476 .313 21.874 1 48 .000
Model
1
R R Square
Adjusted
R Square
Std. Error of
the Estimate
R Square
Change F Change df1 df2 Sig. F Change
Change Statistics
Predictors: (Constant), High School Grade Point Average
a.
Dependent Variable: Grade Point Average - First Year
b.
ANOVA
b
2.910 1 2.910 21.874 .000
a
6.386 48 .133
9.297 49
Regression
Residual
Total
Model
1
Sum of
Squares df Mean Square F Sig.
Predictors: (Constant), High School Grade Point Average
a.
Dependent Variable: Grade Point Average - First Year
b.
SPSS for Institutional Researchers 40
Coefficients
a
1.293 .444 2.912 .005 .400 2.186
.594 .127 .560 4.677 .000 .339 .849
(Constant)
High School Grade
Point Average
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardi
zed
Coefficien
ts
t Sig. Lower Bound Upper Bound
95% Confidence Interval for B
Dependent Variable: Grade Point Average - First Year
a.
Excluded Variables
b
-.088
a
-.734 .466 -.107 .998
-.029
a
-.239 .812 -.035 .991
SAT Verbal Score
SAT Math Score
Model
1
Beta In t Sig.
Partial
Correlation Tolerance
Collinearit
y
Statistics
Predictors in the Model: (Constant), High School Grade Point Average
a.
Dependent Variable: Grade Point Average - First Year
b.
The forward selection procedure stops after the first step and the only variable entered into
the model is the high school GPA. The ANOVA and Coefficients tables show the same
information as in the previous analysis (now for the single predictor model). Information
about the change in statistics is added to the Model Summary table. The R-squared change
and the F change compare the model containing the high school GPA as a predictor to the
model that contains only a constant. Notice that the value of the F change is the same as the
value of the F ratio in the ANOVA table. The final model is: FYGPA = 1.293 + .594 HSGPA +
error, and high school GPA explains 31.3% of the variability observed in the first year GPA.
The t-ratios and their significance together with the partial correlations for SAT verbal and
SAT Math scores are listed in the Excluded Variables table. Notice that both variables are
nonsignificant and the partial correlations are small; especially that associated with the SAT
math score. This means that, after high school GPA is included into the model the SAT Math
score does not contribute any additional information for predicting first year GPA.
Backwards Elimination
Variables Entered/Removed
b
High School Grade
Point Average, SAT
Verbal Score, SAT
Math Score
a
. Enter
.
SAT Math
Score
Backward (criterion: Probability of
F-to-remove >= .100).
.
SAT Verbal
Score
Backward (criterion: Probability of
F-to-remove >= .100).
Model
1
2
3
Variables Entered
Variables
Removed Method
All requested variables entered.
a.
Dependent Variable: Grade Point Average - First Year
b.
SPSS for Institutional Researchers 41
Model Summary
d
.567
a
.321 .277 .37043 .321 7.251 3 46 .000
.566
b
.321 .292 .36653 .000 .015 1 48 .904
.560
c
.313 .299 .36476 -.008 .539 1 49 .466
Model
1
2
3
R R Square
Adjusted
R Square
Std. Error of
the Estimate
R Square
Change F Change df1 df2 Sig. F Change
Change Statistics
Predictors: (Constant), High School Grade Point Average, SAT Verbal Score, SAT Math Score
a.
Predictors: (Constant), High School Grade Point Average, SAT Verbal Score
b.
Predictors: (Constant), High School Grade Point Average
c.
Dependent Variable: Grade Point Average - First Year
d.
ANOVA
d
2.985 3 .995 7.251 .000
a
6.312 46 .137
9.297 49
2.983 2 1.491 11.101 .000
b
6.314 47 .134
9.297 49
2.910 1 2.910 21.874 .000
c
6.386 48 .133
9.297 49
Regression
Residual
Total
Regression
Residual
Total
Regression
Residual
Total
Model
1
2
3
Sum of
Squares df Mean Square F Sig.
Predictors: (Constant), High School Grade Point Average, SAT Verbal Score, SAT
Math Score
a.
Predictors: (Constant), High School Grade Point Average, SAT Verbal Score
b.
Predictors: (Constant), High School Grade Point Average
c.
Dependent Variable: Grade Point Average - First Year
d.
Coefficients
a
1.472 .574 2.565 .014 .317 2.627
-2.84E-04 .000 -.086 -.697 .489 -.001 .001
-5.72E-05 .000 -.015 -.122 .904 -.001 .001
.596 .130 .562 4.596 .000 .335 .858
1.436 .486 2.951 .005 .457 2.414
-2.92E-04 .000 -.088 -.734 .466 -.001 .001
.598 .128 .563 4.683 .000 .341 .855
1.293 .444 2.912 .005 .400 2.186
.594 .127 .560 4.677 .000 .339 .849
(Constant)
SAT Verbal Score
SAT Math Score
High School Grade
Point Average
(Constant)
SAT Verbal Score
High School Grade
Point Average
(Constant)
High School Grade
Point Average
Model
1
2
3
B Std. Error
Unstandardized
Coefficients
Beta
Standardi
zed
Coefficien
ts
t Sig. Lower Bound Upper Bound
95% Confidence Interval for B
Dependent Variable: Grade Point Average - First Year
a.
SPSS for Institutional Researchers 42
Excluded Variables
c
-.015
a
-.122 .904 -.018 .965
-.029
b
-.239 .812 -.035 .991
-.088
b
-.734 .466 -.107 .998
SAT Math Score
SAT Math Score
SAT Verbal Score
Model
2
3
Beta In t Sig.
Partial
Correlation Tolerance
Collinearit
y
Statistics
Predictors in the Model: (Constant), High School Grade Point Average, SAT Verbal Score
a.
Predictors in the Model: (Constant), High School Grade Point Average
b.
Dependent Variable: Grade Point Average - First Year
c.
The backward elimination procedure took 3 steps. The first variable to be removed was SAT
Math score (step 2), and then SAT Verbal score was removed (step 3). For each step we have
separate Model Summary, Coefficients, ANOVA and Excluded variables tables. In the Model
Summary table the F-change statistic compares the new model with the previous one. Thus,
at the last step (Model 3) the F-change statistic compares the model that contains only high
school GPA as the independent variable, with the model that contains high school GPA and
SAT Verbal scores as predictors. The value of the F-change = .539 and its significance is .466
> .05. The hypothesis that the model including only one predictor does no worse than the
model with two predictors cannot be rejected.
Stepwise Regression
Variables Entered/Removed
a
High School
Grade Point
Average
.
Stepwise (Criteria:
Probability-of-F-to-enter <=
.050,
Probability-of-F-to-remove >=
.100).
Model
1
Variables
Entered
Variables
Removed Method
Dependent Variable: Grade Point Average - First Year
a.
Since the only variable that it is entered in the stepwise regression is the high school GPA, the
rest of the stepwise regression output looks the same as that for the forward selection
procedure.
Another way to control the selection of variables is by entering the explanatory variables into
blocks. Each block starts with the final model from the previous block if there is one. The
variables in each block are entered or removed from the equation according to the specified
method: Enter, Forward, Backward, Stepwise or Remove.
SPSS for Institutional Researchers 43
CATEGORICAL INDEPENDENT VARIABLES
First Year GPA, High School GPA and Gender
High School Grade Point Average
4.5 4.0 3.5 3.0 2.5 2.0 1.5
G
r
a
d
e
P
o
i
n
t
A
v
e
r
a
g
e
-
F
i
r
s
t
Y
e
a
r
4.5
4.0
3.5
3.0
2.5
2.0
Gender
Female
Male
First Year GPA, High School GPA and Gender
High School Grade Point Average
4.5 4.0 3.5 3.0 2.5 2.0 1.5
G
r
a
d
e
P
o
i
n
t
A
v
e
r
a
g
e
-
F
i
r
s
t
Y
e
a
r
4.5
4.0
3.5
3.0
2.5
2.0
Gender
Female
Male
We can incorporate information about the categorical variable gender by defining an
indicator (or dummy) variable. An indicator variable is a variable that takes only two
values: 0 and 1. The value 1 is assigned if the attribute of interest is present and the value
zero if the attribute is absent. Then an indicator variable to represent the gender (Male) will
be defined as 1 if the student is male and 0 if the student is female. We can then use the
following multiple linear regression model:
FYGPA =
0
+
1
HSGPA +
2
Male + error
Coefficients
a
1.362 .482 2.826 .007 .392 2.331
.580 .133 .547 4.365 .000 .313 .848
-4.16E-02 .108 -.048 -.386 .702 -.259 .176
(Constant)
High School Grade
Point Average
Male
Model
1
B Std. Error
Unstandardized
Coefficients
Beta
Standardi
zed
Coefficien
ts
t Sig. Lower Bound Upper Bound
95% Confidence Interval for B
Dependent Variable: Grade Point Average - First Year
a.
By including gender into the model we see that R-squared = .315 and the adjusted R-squared
= .286. Notice that gender is not a significant determinant of first year GPA.
We can incorporate information about the ethnicity into the regression model in a similar way
by defining one indicator variable for each ethnicity category. Thus, we can define six
indicator variables: White, Black, Asian, Amerind, Hawaiian and Latino, where White = 1 if
the student is white and 0 otherwise. The other variables defined in a similar way. In order
to incorporate the ethnicity information into the model we only need to use 5 of these
indicator variables. The value of the categorical variable whose indicator variable is not used
in the model is called the reference level. Thus if we use Black, Asian, Amerind, Hawaiian,
and Latino, to represent ethnicity in the multiple regression model the reference level will be
White.
The multiple linear regression model will this time be:
FYGPA =
0
+
1
HSGPA +
2
Black +
3
Asian +
4
Amerind+
5
Hawaiian +
6
Latino +
error
SPSS for Institutional Researchers 44
When setting one of the indicator variables equal to 1 (all the others will be zero, by the
definition of the indicator variables) the model above will produce a straight line with slope
1
and a different y-intercept. For example when Asian = 1 the y-intercept is (
0
+
3
). In this
model setting all the indicator variables equal to zero represents White.
In the regression context a categorical variable is called a factor and its values are called
levels. Rule for categorical variables in regression: Whenever a factor has k levels it can be
included into the multiple regression model by using (k-1) indicator variables.
BINARY LOGISTIC REGRESSION
As part of enrollment projections, retention analyses are an important variable to
consider. Well use our fake data set is to illustrate the use of logistic regression models
and discriminant analysis to identify the variables that contribute to retention.
Institutional characteristics and mission drive the variables that contribute to retention.
The fake data set is purposely elementary to demonstrate the statistical technique.
Notice that in the data set the variable retention is already coded as a dummy variable
with 1 representing retention, and 0 representing did not retain.
One of the consequences of the linear regression model is that the dependent variable must
be a continuous variable because the condition of normal error terms implies that the
dependent variable has a normal distribution. Thus, we cannot use linear regression to
predict retention status. Logistic regression models a function of the probability of retaining
the student.
Let p = Pr(retention = 1), the probability that the value of retention is 1, that is, the
probability that the student comes back. The logistic regression approach models the
function
(
=
=
) 1 Pr( 1
) 1 Pr(
retention
retention
ln as a linear function of say, the first year GPA, financial aid,
social, gender and ethnicity as follows:
LATINO BLACK FEMALE SOCIAL FINAID FYGPA
p
p
9 5 4 3 2 1 0
1
ln + + + + + + + =
|
|
.
|
\
|
L
where
0
, ...,
9
are unknown parameters to be estimated from the data.
Data. The dependent variable should be dichotomous. Independent variables can be interval
level or categorical; if categorical, they should be dummy or indicator coded (there is an
option in the procedure to recode categorical variables automatically).
Assumptions. Logistic regression does not rely on distributional assumptions in the same
sense that discriminant analysis does. However, your solution may be more stable if your
predictors have a multivariate normal distribution. Additionally, as with other forms of
regression, multicollinearity among the predictors can lead to biased estimates and inflated
standard errors. The procedure is most effective when group membership is a truly
categorical variable; if group membership is based on values of a continuous variable (for
example, "high GPA" versus "low GPA"), you should consider using linear regression to take
advantage of the richer information offered by the continuous variable itself.
SPSS for Institutional Researchers 45
Graphical Analysis
A plot of the binary dependent variable versus an independent variable is not worthwhile,
since there are only two distinct values for the dependent variable. Although no graphical
approach can be prescribed for all problems, it is occasionally useful to examine a scatterplot
of one of the independent variables versus another, with codes to indicate whether the
dependent variable is 0 or 1.
Graphs
Scatter
Matrix
Define
Move the variables to be plotted to the Matrix Variables box
Retention Set Markers by
Add a title if desired
OK
Grade Point Average
Amount of Financial
NSSE Q10a
Retention Status
Retain
Did not return/Not r
etained
The plot above shows no clear differences in the association between financial aid and NSSE
Q10a (social), and the association between first year GPA and NSSE Q10a for returning and
non- returning students. Returning students seem to have slightly lower first year GPA and
lower amounts of financial aid than non-returning students.
Analyze
Regression
Binary Logistic
Retention Dependent
Finaid, social
1
, First year Grade Point Average, ethnicity, gender
Covariate(s)
Method Enter (forward conditional, forward LR, forward Wald,
backward conditional, backward LR, or backward Wald, as desired)
Categorical
Ethnicity Categorical Covariates
Gender Categorical Covariates
Ethnicity
1
Social refers to Question 10a on the National Survey of Student Engagement. Mark the box that best
represents the quality of your relationships with people at your institution: Other Students - Friendly,
supportive, sense of belonging. It is scored on a 7-point Likert scale so higher scores are better.
SPSS for Institutional Researchers 46
First
Change
Gender
First
Change
Continue
Save
Predicted values
Probabilities
Group Membership
Residuals
Standardized
Deviance
Continue
Options
Statistics and Plots
Classification plots
Hosmer-Lemeshow goodness of fit
CI for Exp(B)
Continue
OK
Dependent Variable Encoding
0
1
Original Value
Did not return/Not
retained
Retain
Internal Value
SPSS for Institutional Researchers 47
Categorical Variables Codings
23 .000 .000 .000 .000 .000
17 1.000 .000 .000 .000 .000
3 .000 1.000 .000 .000 .000
3 .000 .000 1.000 .000 .000
3 .000 .000 .000 1.000 .000
1 .000 .000 .000 .000 1.000
25 .000
25 1.000
White
Black or African American
Asian
American Indian or
Alaska Native
Native Hawaiian or Other
Pacific Islander
Hispanic or Latino
Ethnicity
Male
Female
Gender
Frequency (1) (2) (3) (4) (5)
Parameter coding
Classification Table
a,b
0 19 .0
0 31 100.0
62.0
Observed
Did not return/Not
retained
Retain
Retention Status
Overall Percentage
Step 0
Did not
return/Not
retained Retain
Retention Status
Percentage
Correct
Predicted
Constant is included in the model.
a.
The cut value is .500
b.
Variables in the Equation
.490 .291 2.823 1 .093 1.632 Constant Step 0
B S.E. Wald df Sig. Exp(B)
Variables not in the Equation
a
5.148 1 .023
1.311 1 .252
.300 1 .584
2.122 1 .145
6.209 5 .286
.080 1 .777
1.113 1 .291
1.113 1 .291
1.113 1 .291
1.665 1 .197
FYGPA
FINAID
SOCIAL
GENDER(1)
ETHNICIT
ETHNICIT(1)
ETHNICIT(2)
ETHNICIT(3)
ETHNICIT(4)
ETHNICIT(5)
Variables Step
0
Score df Sig.
Residual Chi-Squares are not computed because of redundancies.
a.
SPSS for Institutional Researchers 48
Omnibus Tests of Model Coefficients
12.405 9 .191
12.405 9 .191
12.405 9 .191
Step
Block
Model
Step 1
Chi-square df Sig.
Model Summary
54.001 .220 .299
Step
1
-2 Log
likelihood
Cox & Snell
R Square
Nagelkerke
R Square
Hosmer and Lemeshow Test
3.304 8 .914
Step
1
Chi-square df Sig.
Classification Table
a
10 9 52.6
5 26 83.9
72.0
Observed
Did not return/Not
retained
Retain
Retention Status
Overall Percentage
Step 1
Did not
return/Not
retained Retain
Retention Status
Percentage
Correct
Predicted
The cut value is .500
a.
Variables in the Equation
-1.558 .879 3.146 1 .076 .210 .038 1.178
.000 .000 .222 1 .638 1.000 1.000 1.000
-.157 .182 .742 1 .389 .855 .598 1.221
-.461 .821 .315 1 .575 .631 .126 3.154
3.428 5 .634
-.702 .795 .779 1 .377 .496 .104 2.355
-1.596 1.363 1.371 1 .242 .203 .014 2.932
-1.791 1.505 1.416 1 .234 .167 .009 3.185
-1.921 1.550 1.537 1 .215 .146 .007 3.053
-7.028 36.707 .037 1 .848 .001 .000 1.6E+28
7.516 3.148 5.699 1 .017 1837.557
FYGPA
FINAID
SOCIAL
GENDER(1)
ETHNICIT
ETHNICIT(1)
ETHNICIT(2)
ETHNICIT(3)
ETHNICIT(4)
ETHNICIT(5)
Constant
Step
1
a
B S.E. Wald df Sig. Exp(B) Lower Upper
95.0% C.I.for EXP(B)
Variable(s) entered on step 1: FYGPA, FINAID, SOCIAL, GENDER, ETHNICIT.
a.
SPSS for Institutional Researchers 49
Step number: 1
Observed Groups and Predicted Probabilities
4 R
R
R
F R
R 3 RRR R R R
E RRR R R R
Q RRR R R R
U RRR R R R
E 2 D R D R DRRR R R RRRR
N D R D R DRRR R R RRRR
C D R D R DRRR R R RRRR
Y D R D R DRRR R R RRRR
1 D D D RD DRD DDR DRDRDD D D RRRRR DDRR R
D D D RD DRD DDR DRDRDD D D RRRRR DDRR R
D D D RD DRD DDR DRDRDD D D RRRRR DDRR R
D D D RD DRD DDR DRDRDD D D RRRRR DDRR R
Predicted
Prob: 0 .25 .5 .75 1
Group: DDDDDDDDDDDDDDDDDDDDDDDDDDDDDDRRRRRRRRRRRRRRRRRRRRRRRRRRRRRR
Predicted Probability is of Membership for Retain
The Cut Value is .50
Symbols: D - Did not return/Not retained
R - Retain
Each Symbol Represents .25 Cases.
Interpreting the output
Dependent variable Encoding. This table informs you of how the procedure handled the
dichotomous dependent variable, which helps you to interpret the values of the
parameter coefficients. Since Retain was coded as 1 the probabilities computed using the
model will correspond to the probability that the student will return.
Categorical variables codings. This table supplies information about how categorical
predictors were treated. In this case White was used as the reference category for
ethnicity and Male was used as the reference category for gender. The variable
Ethnicity(1) will be associated with black students, Ethnicity(2) with Asian students, and
so on.
Classification Table. The classification table helps you assess the performance of your
model by crosstabulating the observed response categories with the predicted response
categories. There are two classification tables in the output. The first classification table
(Step 0) corresponds to a model that does not include any independent (predictor)
variables. This model correctly classifies all the 31 returning students, but incorrectly
classifies the 19 non-returning students as being retained. The overall misclassification
rate is 38%. The second classification table (Step 1) when all the independent variables
are in the model shows an overall misclassification rate of 28%. Nine of the non-returning
students and five of the returning students were misclassified.
SPSS for Institutional Researchers 50
Variables in the Equation. This table summarizes the roles of the parameters in the
model. In Step 0, there is only a constant in the model (an estimate of
0
). This estimate
is .49. Thus,
. 632 . 1
1
, 49 . 0
1
ln =
=
|
|
.
|
\
|
p
p
and
p
p
The latter quotient is called the odds. The probability of a
student returning is 1.632 times the probability of a student not returning.
For the model that include all the variables we have
LATINO BLACK FEMALE SOCIAL FINAID FYGPA
p
p
028 . 7 702 . 461 . 157 . 000 . 558 . 1 516 . 7
1
ln =
|
|
.
|
\
|
L
The
expression 210 .
) 5 . 2 | 1 Pr( 1
) 5 . 2 | 1 Pr(
) 5 . 3 | 1 Pr( 1
) 5 . 3 | 1 Pr(
) 5 . 2 5 . 3 )( 558 . 1 (
= =
= =
= =
= =
= =
FYGPA retention
FYGPA retention
FYGPA retention
FYGPA retention
e compares the odds of retaining a
student with first year GPA of 3.5 to the odds of retaining a student with first year GPA of
2.5 when the values of all the other independent variables are the same for both
students. This quotient is called the odds ratio, and the model predicts that all else being
equal, the odds of returning for a student with a 3.5 first year GPA is .21 times the odds
of returning for a student with a 2.5 first year GPA, that is, the odds of retaining the
student with the lower first year GPA are higher. If the difference in first year GPA were
only .3 the odds ratio would be .63 = e
(-1.558)(.3)
.
For each of the covariates (independent variables) the table provides the value of the
sample odds ratio, the significance of the estimated coefficient and a confidence interval
for the population odds ratio. A significance value < .05 indicates a potential good
predictor of retention status.
Variables not in the Equation. In Block 0, the variable with the highest score (if
significant) is included first by Forward stepwise regression methods. This information is
ignored if we use Enter as the method.
Omnibus Test for Model Coefficients. This is the analogous of the ANOVA test in linear
regression. This test compares the likelihood of the data as measured by the current
model to the likelihood of the data under the model containing only a constant term.
Large Chi-square values with a small significance value (< .05) indicate that the data is
better explained by the current model than by the constant term only model. In this
example, the chi-square value is 12.405 with a p-value = .191. The model that includes
first year GPA, financial aid, social, ethnicity and gender does not explain the data
significantly better than the constant only model.
Model Summary. The 2 log-likelihood and pseudo r-square statistics are computed. When
the procedure is a backward, forward or stepwise selection these values are computed at
each step. The 2 log-likelihood is a measure of the likelihood of the data under the
current model. The Cox & Snell R-squared, and the Nagelkerke adjusted R-squared are
descriptive measures of the fit of the model, these are measurements similar to the R-
squared in regression. The model explains 29.9% of the variation seen in retention status.
Hosmer and Lemeshow Test. This is a goodness-of-fit test of the null hypothesis that
the model adequately fits the data. If the chi-square value is small and the p-value for
this test is greater than .05 we should conclude that the model fits the data well. In this
example the p-value is .914, thus a good fit.
SPSS for Institutional Researchers 51
Observed Groups and Predicted Probabilities. Visual display of predicted group
membership. A case is classified into group 1 if the predicted Pr(retention =1) > .5. The 5
misclassified cases in the did not retain group are represented by the five sets of 4 Rs.
Each set of four Rs represents one observation.
The Save command we issued created four additional variables that are stored in the data
worksheet. They are the retention probabilities (pre_3), the predicted group membership
(pgr_3), standardized residuals (zre_3) and deviance residuals (dev_3). Plots of the residuals
can be used to ascertain whether the logistic model fits the data well. When the fit is
adequate and the sample size is large, the standardized residuals will follow a standard
normal distribution. The deviance residuals will also be approximately normally distributed
when the model fits the data well. Normal quantile plots of these residuals can be plotted
for examination.
REFINING THE MODEL
In logistic regression we can perform several types of variable selection in order to streamline
the model. The choices are forward Wald, forward conditional, forward LR, backward Wald,
backward conditional and backward LR. The difference resides on the criterion used in order
to enter (forward) or remove (backward) variables from the model. Below are some highlights
of the Backward LR procedure applied to these data.
SPSS for Institutional Researchers 52
Omnibus Tests of Model Coefficients
12.405 9 .191
12.405 9 .191
12.405 9 .191
-.223 1 .637
12.182 8 .143
12.182 4 .016
-.157 1 .692
12.025 7 .100
12.025 3 .007
-.833 1 .362
11.193 6 .083
11.193 2 .004
-5.691 5 .337
5.502 1 .019
5.502 1 .019
Step
Block
Model
Step
Block
Model
Step
Block
Model
Step
Block
Model
Step
Block
Model
Step 1
Step 2
a
Step 3
a
Step 4
a
Step 5
a
Chi-square df Sig.
A negative Chi-squares value indicates that the
Chi-squares value has decreased from the
previous step.
a.
Model Summary
54.001 .220 .299
54.224 .216 .294
54.381 .214 .291
55.214 .201 .273
60.905 .104 .142
Step
1
2
3
4
5
-2 Log
likelihood
Cox & Snell
R Square
Nagelkerke
R Square
Hosmer and Lemeshow Test
3.304 8 .914
6.531 8 .588
10.290 8 .245
7.265 8 .508
4.514 7 .719
Step
1
2
3
4
5
Chi-square df Sig.
SPSS for Institutional Researchers 53
Variables not in the Equation
e
.224 1 .636
.224 1 .636
.064 1 .800
.158 1 .691
.216 1 .642
.828 1 .363
.047 1 .829
.343 1 .558
.302 1 .583
1.187 1 .276
5.444 5 .364
.019 1 .891
.597 1 .440
1.074 1 .300
1.753 1 .185
.810 1 .368
FINAID Variables
Overall Statistics
Step 2
a
FINAID
GENDER(1)
Variables Step 3
b
FINAID
SOCIAL
GENDER(1)
Variables Step 4
c
FINAID
SOCIAL
GENDER(1)
ETHNICIT
ETHNICIT(1)
ETHNICIT(2)
ETHNICIT(3)
ETHNICIT(4)
ETHNICIT(5)
Variables Step 5
d
Score df Sig.
Variable(s) removed on step 2: FINAID.
a.
Variable(s) removed on step 3: GENDER.
b.
Variable(s) removed on step 4: SOCIAL.
c.
Variable(s) removed on step 5: ETHNICIT.
d.
Residual Chi-Squares are not computed because of redundancies.
e.
Step Summary
a,b
-.223 1 .637 12.182 8 .143 72.0%
OUT:
FINAID
-.157 1 .692 12.025 7 .100 72.0%
OUT:
GENDER
-.833 1 .362 11.193 6 .083 76.0%
OUT:
SOCIAL
-5.691 5 .337 5.502 1 .019 70.0%
OUT:
ETHNICIT
Step
2
3
4
5
Chi-square df Sig.
Improvement
Chi-square df Sig.
Model
Correct
Class % Variable
No more variables can be deleted from or added to the current model.
a.
End block: 1
b.
The procedure took 5 steps. The first variable removed was financial aid followed by gender,
social and ethnicity in that order. Notice that removal of the variable ethnicity that is coded
as five separate indicator variables results in the simultaneous removal of all 5 indicators.
The final model is FYGPA
p
p
73 . 1 38 . 6
1
ln =
(
. The coefficient of first year GPA is
significantly different from zero (p-value = .03). The omnibus test of the coefficients, model
summary, Hosmer and Lemeshow Tests, and variables not in the equation are provided for
each step. Noteworthy facts:
SPSS for Institutional Researchers 54
The omnibus test of coefficients is significant for the final model.
The value of 2 log-likelihood reaches its maximum value 60.905 for the final model,
but Cox & Snell and Nagelkerke R-squared are smaller for the final model.
The Hosmer and Lemeshow test remains nonsignificant throughout all the steps,
indicating a good fit.
In the variables not in the equation table all the variables listed at each step have a
significance value greater than .05.
Finally, the Step Summary table gives a step-by-step account of the improvement chi-square,
the model chi-square, its significance level, the percent of correctly classified observations,
and the name of the variable removed.
In this example all the stepwise procedures lead to the same final model.
DISCRIMINANT ANALYSIS
Another technique for classifying individuals into two or more distinct groups is discriminant
analysis. An advantage discriminant analysis has over logistic regression is that it can handle
more than two groups. Compared to logistic regression, a disadvantage of discriminant
analysis is that it heavily relies on the assumption that the independent variables have a
multivariate normal distribution. Well illustrate the procedure by predicting retention
status as a function of amount of financial aid received, social, first year GPA, SAT verbal
score and SAT math score.
In discriminant analysis, a linear combination of the independent variables is formed and
serves as the basis for assigning cases to groups. Thus, information contained in multiple
independent variables is summarized in a single index. Therefore, by finding a weighted
average of financial aid received, social, first year GPA, SAT verbal score and SAT math score
we can obtain a score that distinguishes returning students from non-returning ones. In
discriminant analysis, the weights are estimated so that they result in the best separation
between the groups.
The linear discriminant equation
D =
0
+
1
FINAID +
2
SOCIAL +
3
FYGPA +
4
SATV +
5
SATM
is similar to the linear regression equation but this time the 's are chosen so that the value
of the discriminant function differ as much as possible between the two groups so that for the
discriminant scores the ratio
squares of sum groups - within
squares of sum groups - between
is a maximum.
Data. The grouping variable must have a limited number of distinct categories, coded as
integers. Independent variables that are nominal must be recoded to dummy or contrast
variables.
Assumptions. Cases should be independent. Predictor variables should have a multivariate
normal distribution, and within-group variance-covariance matrices should be equal across
groups. Group membership is assumed to be mutually exclusive (that is, no case belongs to
more than one group) and collectively exhaustive (that is, all cases are members of a group).
The procedure is most effective when group membership is a truly categorical variable; if
SPSS for Institutional Researchers 55
group membership is based on values of a continuous variable (for example, high GPA versus
low GPA), you should consider using linear regression to take advantage of the richer
information offered by the continuous variable itself.
Analyze
Classify
Discriminant
Retention Dependent Variable
Click on Define Range and a small dialog box will appear
Type in 0 (or the smallest group identifier)
Type in 1 (or the largest group identifier)
Continue
Finaid, social, fygpa, SAT-V, SAT-M Independents
Statistics
Means
Univariate ANOVAs
Function Coefficients
Fishers
Unstandardized
Continue
Classify
Prior Probabilities
Compute from group sizes
Use covariance matrix
Within groups
Plots
Separate plots
Display
Casewise results
Summary table
Continue
Save
Predicted group membership
Discriminant scores
Probabilities of group membership
Continue
OK
SPSS for Institutional Researchers 56
Group Statistics
9118.7895 10243.37690 19 19.000
4.5263 2.09148 19 19.000
3.5332 .39574 19 19.000
538.7895 127.51888 19 19.000
561.4211 119.67099 19 19.000
6039.9032 8679.27550 31 31.000
4.2258 1.80203 31 31.000
3.2481 .42896 31 31.000
534.7742 136.13026 31 31.000
633.1613 104.08365 31 31.000
7209.8800 9324.36522 50 50.000
4.3400 1.90177 50 50.000
3.3564 .43558 50 50.000
536.3000 131.61729 50 50.000
605.9000 114.58982 50 50.000
Amount of Financial
Aid Received
NSSE Q10a
Grade Point Average
- First Year
SAT Verbal Score
SAT Math Score
Amount of Financial
Aid Received
NSSE Q10a
Grade Point Average
- First Year
SAT Verbal Score
SAT Math Score
Amount of Financial
Aid Received
NSSE Q10a
Grade Point Average
- First Year
SAT Verbal Score
SAT Math Score
Retention Status
Did not return/Not
retained
Retain
Total
Mean Std. Deviation Unweighted Weighted
Valid N (listwise)
Tests of Equality of Group Means
.974 1.292 1 48 .261
.994 .290 1 48 .593
.897 5.511 1 48 .023
1.000 .011 1 48 .918
.906 4.994 1 48 .030
Amount of Financial
Aid Received
NSSE Q10a
Grade Point Average
- First Year
SAT Verbal Score
SAT Math Score
Wilks'
Lambda F df1 df2 Sig.
SPSS for Institutional Researchers 57
Canonical Discriminant Function Coefficients
.000
.064
1.681
.001
-.006
-2.921
Amount of Financial
Aid Received
NSSE Q10a
Grade Point Average
- First Year
SAT Verbal Score
SAT Math Score
(Constant)
1
Function
Unstandardized coefficients
Standardized Canonical Discriminant Function Coefficients
.106
.122
.700
.174
-.688
Amount of Financial
Aid Received
NSSE Q10a
Grade Point Average
- First Year
SAT Verbal Score
SAT Math Score
1
Function
Prior Probabilities for Groups
.380 19 19.000
.620 31 31.000
1.000 50 50.000
Retention Status
Did not return/Not
retained
Retain
Total
Prior Unweighted Weighted
Cases Used in Analysis
Casewise Statistics
1 1 .109 1 .928 2.575 0 .072 6.713 -1.980
1 1 .944 1 .712 .005 0 .288 .839 -.304
1 1 .490 1 .573 .477 0 .427 .087 .316
1 1 .395 1 .534 .725 0 .466 .018 .477
1 0** .430 1 .685 .624 1 .315 3.154 1.401
1 1 .308 1 .879 1.038 0 .121 4.019 -1.393
1 1 .719 1 .650 .130 0 .350 .392 -.014
1 1 .025 1 .960 5.045 0 .040 10.447 -2.621
1 1 .448 1 .849 .575 0 .151 3.043 -1.133
1 1 .701 1 .645 .147 0 .355 .363 .009
Case Number
1
2
3
4
5
6
7
8
9
10
Original
Actual Group
Predicted
Group p df
P(D>d | G=g)
P(G=g | D=d)
Squared
Mahalanobis
Distance to
Centroid
Highest Group
Group P(G=g | D=d)
Squared
Mahalanobis
Distance to
Centroid
Second Highest Group
Function 1
Discrimin
ant
Scores
Misclassified case
**.
SPSS for Institutional Researchers 58
Classification Results
a
6 13 19
5 26 31
31.6 68.4 100.0
16.1 83.9 100.0
Retention Status
Did not return/Not
retained
Retain
Did not return/Not
retained
Retain
Count
%
Original
Did not
return/Not
retained Retain
Predicted Group
Membership
Total
64.0% of original grouped cases correctly classified.
a.
Functions at Group Centroids
.611
-.375
Retention Status
Did not return/Not
retained
Retain
1
Function
Unstandardized canonical discriminant
functions evaluated at group means
2.91 2.22 1.53 .84 .15 -.54 -1.23 -1.92 -2.61
Canonical Discriminant Function 1
Retention Status = Not retained
10
8
6
4
2
0
Std. Dev = .93
Mean = .61
N = 19.00
2.94
2.32
1.70
1.08
.46
-.16
-.78
-1.40
-2.02
-2.64
Canonical Discriminant Function 1
Retention Status = Retain
12
10
8
6
4
2
0
Std. Dev = 1.04
Mean = -.37
N = 31.00
Classification Function Coefficients
-9.214E-05 -1.03E-04
1.265 1.202
21.510 19.852
2.628E-02 2.499E-02
3.974E-02 4.589E-02
-59.644 -56.157
Amount of Financial
Aid Received
NSSE Q10a
Grade Point Average
- First Year
SAT Verbal Score
SAT Math Score
(Constant)
Did not
return/Not
retained Retain
Retention Status
Fisher's linear discriminant functions
SPSS for Institutional Researchers 59
Output Interpretation
Group Statistics. This table displays descriptive statistics (means, standard deviations
and number of observations) for each variable across groups and for the total sample.
Tests of Equality of Group Means. Shows significance tests for equality of group
means for each variable. The F values and their significance levels are the same as
those calculated from a one-way analysis of variance with retention status as the
grouping variable. The mean first year GPA and the mean SAT-Math are significantly
different for returning and non-returning students; the p-values are .023 and .03,
respectively.
Canonical Discriminant Function Coefficients. The coefficients displayed in this table
are the coefficients of the discriminant function. Multiplying the unstandardized
coefficients by the values of the variables, summing these products and adding the
constant compute the discriminant score for a particular individual. For the first
student in the file the value of the discriminant score is:
D1 = -2.921 + (.000)(0) + (.064)(3) + (1.681)(2.64) + (.001)(625) (.006)(722) = -1.9982
Standardized Discriminant Function Coefficients. When variables are measured in
different units, the magnitude of an unstandardized coefficient provides little
indication of the relative contribution of the variable to the overall discrimination.
These standardized coefficients are the canonical discriminant function coefficients
when the procedure is ran on the values of the standardized independent variables
(each of them standardized to mean 0 and standard deviation 1). In this case the
magnitude of the standardized coefficient is a good index of relative contribution of
the variable to the overall discriminant function. The first year GPA and the SAT-Math
score are the two variables with the highest standardized coefficients .700 and -.688,
respectively.
Prior Probabilities For Groups. This table displays the prior probabilities for
membership in groups. The prior probability is an estimate of the likelihood that a
case belongs to a particular group when no information about it is available. Since in
the data set we have that 31 of the 50 students were retained and 19 of the 50
students were not retained the prior retention and non-retention probabilities are .62
and .38, respectively.
Casewise Statistics. This table displays the actual group, predicted group, posterior
probabilities, squared Mahalanobis distance to centroid (see definition below), and
discriminant scores. The posterior probabilities are the updated probabilities of group
membership using the information provided by the independent variables.
Classification Results. This table measures the degree of success of the classification
for this sample. The model correctly classified 31.6% of the non-returning students
and 83.9 % of the returning students. The model correctly classified 64% of all cases.
Histograms of Discriminant Scores. To see how much the two groups overlap and to
examine the distribution of the discriminant scores, it is often useful to plot the
discriminant scores for the groups. The average score for a group is called the group
centroid and is listed in each histogram and on the Functions at Group Centroids
table. The least the amount of overlap in these histograms the more successful the
classification will be. In this example, although the distributions of the discriminant
scores for the 2 groups are very different, there is a substantial amount of overlap
between them since many of the non-returning students have low discriminant scores
they are misclassified as retained.
SPSS for Institutional Researchers 60
Classification Function Coefficients. Each column contains estimates of the
coefficients for a classification function for one group. These are also known as
Fishers linear discrimination function coefficients and can be used directly for
classification. A set of coefficients is obtained for each group, and a case is assigned
to the group for which it has the largest discriminant score. The classification results
are identical to that provided by the canonical discriminant function coefficients. The
first student in the data file has the following values for the predictor variables finaid
= $0, social = 3.00, fygpa = 2.64, SATV = 625 and SATM = 722. His Fishers
discriminant functions scores are 46.5468 and 48.60961 for the not-retained and
retained groups, respectively. Thus, the student is classified as retained (group 1).
REFINING THE MODEL
Just as in linear and logistic regression it is possible to identify the variables that are most
effective for discriminating among the groups. Our analysis suggests that the two most
discriminating variables are first year GPA and SAT-Math score. Well implement a stepwise
procedure for finding the best discriminating model.
Analyze
Classify
Discriminant
Use stepwise method
Method
Method
Smallest F ratio (or Wilks lambda, or Unexplained variance, or
Mahalanobis distance, or Raos V)
Criteria
Use F value (or Use probability of F)
Display
Summary of steps
Continue
OK
Many of the tables created by the stepwise procedure are the same as those we saw in the
previous analysis. Only the tables that show new or different information are included here.
SPSS for Institutional Researchers 61
Variables in the Analysis
1.000 5.511
1.000 5.064 4.994
Did not
return/Not
retained
and
Retain
1.000 4.561 5.511
Did not
return/Not
retained
and
Retain
Grade Point
Average - First Year
Grade Point
Average - First Year
SAT Math Score
Step
1
2
Tolerance F to Remove Min. F
Between
Groups
Canonical Discriminant Function Coefficients
1.753
-.006
-2.052
Grade Point
Average - First Year
SAT Math Score
(Constant)
1
Function
Unstandardized coefficients
Standardized Canonical Discriminant Function Coefficients
.731
-.697
Grade Point
Average - First Year
SAT Math Score
1
Function
Classification Function Coefficients
20.116 18.445
4.482E-02 5.085E-02
-49.085 -46.531
Grade Point
Average - First Year
SAT Math Score
(Constant)
Did not
return/Not
retained Retain
Retention Status
Fisher's linear discriminant functions
SPSS for Institutional Researchers 62
Casewise Statistics
1 1 .104 1 .924 2.648 0 .076 6.660 -1.990
1 1 .708 1 .786 .140 0 .214 1.764 -.737
1 1 .322 1 .500 .979 0 .500 .001 .627
1 1 .690 1 .637 .159 0 .363 .307 .037
1 0** .566 1 .625 .330 1 .375 2.333 1.165
1 1 .319 1 .869 .993 0 .131 3.801 -1.359
1 1 .512 1 .579 .431 0 .421 .088 .294
1 1 .008 1 .970 7.096 0 .030 13.083 -3.026
1 1 .473 1 .836 .516 0 .164 2.793 -1.080
1 1 .826 1 .676 .049 0 .324 .537 -.142
Case Number
1
2
3
4
5
6
7
8
9
10
Original
Actual Group
Predicted
Group p df
P(D>d | G=g)
P(G=g | D=d)
Squared
Mahalanobis
Distance to
Centroid
Highest Group
Group P(G=g | D=d)
Squared
Mahalanobis
Distance to
Centroid
Second Highest Group
Function 1
Discrimin
ant
Scores
Misclassified case
**.
Classification Results
a
7 12 19
5 26 31
36.8 63.2 100.0
16.1 83.9 100.0
Retention Status
Did not return/Not
retained
Retain
Did not return/Not
retained
Retain
Count
%
Original
Did not
return/Not
retained Retain
Predicted Group
Membership
Total
66.0% of original grouped cases correctly classified.
a.
Variables Entered/Removed. Shows that first year GPA was entered into the model in the
first step since the F statistic equals 5.511 and exceeds the entry criterion of 3.84. The SAT
Math score was entered at the second step.
Variables in the Analysis. This table displays statistics for the variables that are in the
analysis at each step.
Canonical Discriminant Function Coefficients. The discriminant function is
D = -2.052 +1.753 FYGPA - .006 SATM. Fishers linear discrimination functions appear in the
Classification Function Coefficients table.
Standardized Canonical Discriminant Function Coefficients. Since the magnitudes of the
standardized coefficients are similar .731 and -.697 (the negative sign is irrelevant) both
independent variables have about the same importance in discriminating between the two
groups defined by retention status.
Classification Results. Compared with the model containing finaid, social, fygpa, SATV and
SATM this model does a slightly better classification job. The reduced model has the same
misclassification rate for the group of returning students, and a lower misclassification rate
for the group of non-returning students.
SPSS for Institutional Researchers 63
First year GPA, SAT-Math Score
by Retention Status
SAT Math Score
900 800 700 600 500 400 300 200
G
r
a
d
e
P
o
i
n
t
A
v
e
r
a
g
e
-
F
i
r
s
t
Y
e
a
r
4.5
4.0
3.5
3.0
2.5
2.0
Retention Status
Retain
Did not return/Not r
etained
This graph shows that most of the
distinction between returning and
non-returning students occurs along
the first year GPA dimension. It is
easier to classify students with low
first year GPA; they are the ones
that tend to return. Among
students with high first year GPA
more difficult to distinguish
between the
is
two groups.
SPSS for Institutional Researchers 64
ANALYZING & PRESENTING SURVEY RESULTS
Survey research is a staple of our work as institutional researchers. The opinions and
experiences of students and faculty provide valuable data to facilitate the decision making
processes at our colleges and universities. Further, as the demand for educational outcomes
assessment increases, survey research will become even more critical to determine that the
education, psychosocial, and developmental needs of our students are being met. As part of a
comprehensive institutional research effort, survey research is essential. The likelihood is
great, however, that demands for surveys will increase and institutional researchers are
encouraged to coordinate the timing of surveys to avoid the oversurveying of campus groups.
For the data to be useful, survey results must be analyzed and communicated to campus
constituencies. Too often, the examination of survey results is hasty and hurried because of
other looming priorities. To be useful, the analysis need not be time consuming or extensive.
Typically, descriptive statistics (mean, percentage) are the minimum analytical criteria for
interpreting results and for comparison with national norms or comparison groups and are
largely acceptable for college/university leaders. In fact, for nationally sponsored survey
programs such as those provided by the Higher Education Research Institute (HERI), these
basic analyses are provided and all that is required is the transformation of the data to be of
use at your college or university. More in-depth analysis may be of interest to determine
differences in responses based on categorical variables (gender, rank, tenure status, year in
school, discipline, athletic status, etc.) or to determine the relationship between continuous
variables (salary, age, family income, scaled responses, rankings, etc.). For basic descriptive
statistics, a spreadsheet program such as Microsoft Excel is adequate; however, the options in
SPSS provide for a more comprehensive, rigorous statistical analysis that combines descriptive
and inferential statistical techniques. Similarly, as most survey reports from HERI, HEDS, and
other consortia include an SPSS data file, your institutions enrollment in such series becomes
more useful. The sophistication of analysis may be largely determined by the group to which
you are presenting results; however, any analysis can be effectively communicated to groups
with varying levels of comfort with statistics.
The volume of data that is gathered with survey research can be overwhelming. For this
reason, planning in advance the analyses that are of interest will help you make the most use
of the data. This decision may be driven by a strategic planning initiative, a direct point of
inquiry from a colleague, or a longitudinal trend analysis strategy. This effort becomes
complicated when multiple surveys are administered at your college/university. Because the
content of the instruments often overlap, it may be of use to create a matrix of the content
and scope of each assessment for internal use to allow for quick access to the meaningful
data to answer a myriad of research questions.
One of the most important components of analyzing survey results is good file management.
Survey research is often plagued by incomplete data which can reduce sample size and limit
interpretations. Spreadsheet programs are unable to manage this problem. In SPSS, missing
data analysis allows all responses to be retained, thereby preserving a robust sample size.
The reasons for missing data are numerous. The respondent may have found a question (or
group of questions) objectionable and choose not to respond. A question may have
inadvertently been skipped, or the responses provided did not adequately represent the
respondents opinion or attitude. Even a few, scattered missing data points may adversely
effect an analysis. Results can be misleading because the sample used in the analysis will not
be representative of all respondents. This creates a variation of non-response bias. The
opinions of those who left the question blank are then underrepresented in your analysis. For
example, in the table below, the grad point averages for seniors is displayed. The table on
SPSS for Institutional Researchers 65
the left has several missing data points and the table on the right represents complete data
for the sample.
Case GPA Case GPA
1 3.53 1 3.53
2 2 2.25
3 3.82 3 3.82
4 2.98 4 2.98
5 3.10 5 3.10
6 6 2.73
7 7 3.00
8 8 2.98
Mean 3.36 Mean 3.17
With the missing data removed from the analysis, the mean grade point average is
overestimated. This can seriously impact any number of institutional decisions.
Historically, missing data is managed by removing the respondent from the analysis. As the
number of respondents removed for incomplete data increases, the likelihood of being able to
perform a given analysis decreases. Replacing missing data is a statistical procedure that
begins with an exploration of the missing data using Frequencies. The percentage of
respondents who did not provide data will be provided. You can make the decision about
what percentage is considered problematic; however, keep in mind that all missing data have
the possibility of adversely affecting the analysis.
Missing data can be statistically replaced using estimates of what the respondent would have
answered. A common measure used is the mean. For each missing data point, the mean of the
sample will be inserted. This is potentially problematic as measures of variance will then be
impacted and future analysis less reliable.
Transform
Replace Missing Values
Move to the New Variable box the variables(s) you wish to transform. SPSS will create a new
variable at the end of your data set. A default name is assigned (var_1). Select the method
you prefer and click Change.
SPSS for Institutional Researchers 66
The output screen will open to summarize the number of data points changed.
Missing
Result Values First Last Valid Creating
Variable Replaced Non-Miss Non-Miss Cases Function
AGE_1 1 1 11 11 SMEAN(AGE)
_
Return to the data editor window and examine the new variable. Retaining both the old and
new variable is recommended. You may also wish to run descriptives for both variables to
compare results.
SPSS Missing Value Analysis (available in version 11) uses maximum likelihood to replace
missing data based on the assumption that the data are missing at random (also assumes
multivariate normality). In this analysis, the value of the missing data point is determined
using either an iterative algorithm or regression approach.
With a clean data file, you are now ready to proceed with statistical analysis. The appropriate
analysis depends on your research question. Step by step procedures for conducting numerous
analyses are presented in this document; however, this is not an exhaustive manual.
Additional tutorials are available in SPSS 10.
HOT TIP: STATISTICS COACH!!!
Need some help with statistical procedures? Right click on your mouse and select
Statistics Coach. The tutorial will help you determine which analysis is right for
your research question.
The communication of results is one way of closing the loop in the survey research process.
Not only does it reinforce that the time spent by the respondents provided valuable
information, it also provides the opportunity to publicly identify areas of strength and
challenge. Results are best communicated briefly using everyday language supported by
tables and graphs.
The extent to which your college/university communicates results will be determined by the
philosophy if disclosure agreed upon by your leaders. Communication is enhanced by the
breadth of technology available at our institutions. A broad strategy is recommended
including email, paper, and web announcements of results. A caveat, however, is that as the
communication of results increases, so too may requests for additional analyses.
Your office should be prepared to manage such requests.
SPSS for Institutional Researchers 67
USING SPSS OUTPUT IN OTHER PROGRAMS
The versatility of SPSS includes the ability to export output and data files to other programs
including the Microsoft Office package. As mentioned previously, data sets can be saves as an
Excel file using File Save As and selecting .xls from the Save as Type pulldown menu.
In addition, output can be copied to a Word document (as in this manual). This helpful
technique saves time and saves transcription errors that may result from repeating data entry
in another program. To copy output from the Output Viewer to a Word document, right click
on the object you wish to copy. Select Copy Objects. Open the Word document and place the
cursor in the location the object will appear. Use the Paste function (Edit Paste or Ctrl-V)
and the object will appear as an image.
As websites become more useful in the work of institutional researchers, SPSS has improved
its capabilities to grow with our offices. Output, graphs, and charts can be exported to
Fireworks as a .jpeg (PC) or .pict (MAC) for use in a website. Select the object, right click on
the mouse and choose Export. Select the format and save destination and click OK.
SPSS for Institutional Researchers 68
APPENDIX A
Parametric and Nonparametric Statistics
Selection Criteria for Various Research Methods
Parametric Statistics Non-Parametric Statistics
Basic Assumptions
N 30
Interval/Ratio Data
Normal Curve
Violation of 1 or more of the
three basic assumptions
Descriptive Statistics
Central Tendency Mean Median skewed data
Mode bimodal data
Variability Standard deviation Quartile Deviation
Standard Scores (Norms) z, T, Stanines Percentile Ranks
Inferential Statistics
Survey Research Method Chi Square for nominal data
comparisons
Correlational Research
Method
Pearson product-moment
correlation coefficient
Spearman rank order rho
Regression analysis (one
predictor variable and one
criterion variable)
Multiple regression
analysis (more than one
predictor variable,
continuous criterion
variable)
Curvilinear Regression
Analysis or Trend Analysis
Discriminant Function
Analysis (more than one
predictor variable to see if
you can form a function to
predict a categorical
criterion variable
Canonical Correlation
(correlation of a set of
predictor variables and a
set of criterion variables)
Factor Analysis Cluster Analysis
Experimental Research
Method
Posttest only
1 IV at 2 levels
Independent groups
Independent groups t ratio Mann Whitney U
Posttest only
1 IV at 2 levels
Repeated Measures design
Repeated measures t ratio Wilcoxon Signed Ranks test
Posttest only
1 IV at 3 or more levels
Independent groups
Independent groups
analysis of variance
(ANOVA)
Kruskal-Wallis H test
SPSS for Institutional Researchers 69
Posttest only
1 IV at 3 or more levels
Repeated Measures design
Repeated measures
ANOVA
Friedman ANOVA by ranks
Factorial
More than 1 IV
Posttest only
1 Dependent variable
2 X 3 factorial ANOVA
2 X 4 factorial ANOVA
2 X 2 factorial ANOVA
Pretest / Posttest Design
Differences in Posttest with
the effect of the pretest
(covariate) partialed out
Analysis of Covariance
(ANCOVA)
More than 1 DV
Posttest only design
Analyzing differences in mean
vector of scores (profile of
scores) from a set of DVs
Multivariate Analysis of
Variance (MANOVA)
More than 1 DV
Pretest / Posttest Design
Analyzing differences in mean
vector of posttest scores
(profile of scores) with
covariate(s) partialed out
Multivariate Analysis of
Covariance (MANCOVA)
Model Building
Path Analysis all measured
(observed) variables and paths
in the model are analyzed and
the fit of the model tested
Confirmatory Factor Analysis Measurement model whereby one or more latent variables
are measured by various number of indicators and the fit of the model tested.
Structural Equation Modeling Full model including X and Y measurement models tested as
well as a path model for latent variables with a Linear Structural Equation Analysis (LISREL)
program.
You might also like
- Research Methods & Statistics For Public & Nonprofit Administrators-Practical Guide - Nishishiba 2014 PDFDocument393 pagesResearch Methods & Statistics For Public & Nonprofit Administrators-Practical Guide - Nishishiba 2014 PDFNancy Fernandez90% (10)
- Possible Evidence For CSTP 2 - Creating and Maintaining Effective Environments For Student LearningDocument5 pagesPossible Evidence For CSTP 2 - Creating and Maintaining Effective Environments For Student LearningHuế NguyễnNo ratings yet
- IBM SPSS Statistics A Complete Guide - 2019 EditionFrom EverandIBM SPSS Statistics A Complete Guide - 2019 EditionRating: 5 out of 5 stars5/5 (1)
- IBM SpssDocument1,103 pagesIBM SpssWu Han YuNo ratings yet
- Introduction To IBM SPSS StatisticsDocument85 pagesIntroduction To IBM SPSS StatisticswssirugNo ratings yet
- Basic SPSS TutorialDocument218 pagesBasic SPSS Tutorialsuaterguvan100% (4)
- Basic SPSS Tutorial (2015) PDFDocument218 pagesBasic SPSS Tutorial (2015) PDFlacisag100% (1)
- What Statistical Analysis Should I UseDocument3 pagesWhat Statistical Analysis Should I UseeswarlalbkNo ratings yet
- TL1 Command Reference ManualDocument1,462 pagesTL1 Command Reference Manualas100% (1)
- InformaticaDocument11 pagesInformaticaSaket SharanNo ratings yet
- Harvard SPSS Tutorial PDFDocument84 pagesHarvard SPSS Tutorial PDFsunilgenius@gmail.comNo ratings yet
- Parametric Statistical Analysis in SPSSDocument56 pagesParametric Statistical Analysis in SPSSKarl John A. GalvezNo ratings yet
- SpssDocument50 pagesSpssTech_MXNo ratings yet
- Data Analysis With IBM SPSS StatisticsDocument435 pagesData Analysis With IBM SPSS StatisticsJuloura Pastor100% (1)
- SPSS ManualDocument200 pagesSPSS Manualkararra100% (2)
- SPSS Data AnalysisDocument47 pagesSPSS Data AnalysisDdy Lee100% (4)
- SPSS For BeginnersDocument445 pagesSPSS For BeginnersHasan100% (4)
- Data Analysis With SASDocument353 pagesData Analysis With SASVictoria Liendo100% (1)
- Spss Workshop NotesDocument20 pagesSpss Workshop Notesfrancisco_araujo_22100% (1)
- Testing For Normality Using SPSS PDFDocument12 pagesTesting For Normality Using SPSS PDFΧρήστος Ντάνης100% (1)
- Spss SyllabusDocument2 pagesSpss SyllabusBhagwati ShuklaNo ratings yet
- Bibliometrix PresentationDocument41 pagesBibliometrix Presentationdaksh gupta100% (1)
- Descriptive Research: Characteristics Value, Importance, and Advantages TechniquesDocument9 pagesDescriptive Research: Characteristics Value, Importance, and Advantages TechniquesApril MataloteNo ratings yet
- Data Analysis Using SpssDocument2 pagesData Analysis Using SpssAnonymous EE5LPEV7100% (1)
- MEPI Presentation (Evaluation) PPT - PPSXDocument19 pagesMEPI Presentation (Evaluation) PPT - PPSXjoncan100% (1)
- SPSS Tutorial: A Detailed ExplanationDocument193 pagesSPSS Tutorial: A Detailed ExplanationFaizan Ahmad100% (10)
- Part14 Survival AnalysisDocument22 pagesPart14 Survival AnalysisSri MulyatiNo ratings yet
- Fundamental of Stat by S C GUPTADocument13 pagesFundamental of Stat by S C GUPTAPushpa Banerjee14% (7)
- Research Methodology and BiostatisticsDocument163 pagesResearch Methodology and BiostatisticsLourdesNo ratings yet
- Correlation and RegressionDocument31 pagesCorrelation and RegressionDela Cruz GenesisNo ratings yet
- Summary Table of Statistical TestsDocument5 pagesSummary Table of Statistical TestsLeonila Miranda0% (1)
- SPSS UpdatedDocument25 pagesSPSS UpdatedshafiqpeerNo ratings yet
- Multivariate AnalysisDocument57 pagesMultivariate Analysissuduku007100% (1)
- Chapter 1 - Data CollectionDocument7 pagesChapter 1 - Data CollectionRay AdamNo ratings yet
- B.SC Statistics PDFDocument16 pagesB.SC Statistics PDFsrinivasprashantNo ratings yet
- Statistical MethodsDocument109 pagesStatistical MethodsGuruKPO90% (10)
- Chap4 Normality (Data Analysis) FVDocument72 pagesChap4 Normality (Data Analysis) FVryad fki100% (1)
- StatisticsDocument33 pagesStatisticsAnonymous J5sNuoIy100% (2)
- Structural Equation Modeling Using AmosDocument238 pagesStructural Equation Modeling Using AmosMAMOONA MUSHTAQ100% (3)
- Stac101 PDFDocument91 pagesStac101 PDFShanmukh SagarNo ratings yet
- SPSS For Starters and 2nd LevelersDocument361 pagesSPSS For Starters and 2nd Levelersإدريس طاهيريNo ratings yet
- Getting To Know SPSSDocument204 pagesGetting To Know SPSSTarig GibreelNo ratings yet
- Regression Modeling PDFDocument598 pagesRegression Modeling PDFJuanCarlosAguilarCastroNo ratings yet
- Sampling PDFDocument120 pagesSampling PDFHamid HusainNo ratings yet
- Meta Analysis With RDocument256 pagesMeta Analysis With RKay Han67% (3)
- Introduction To SPSS 1Document38 pagesIntroduction To SPSS 1nahanunaNo ratings yet
- Factor Analysis Using Spss PDFDocument2 pagesFactor Analysis Using Spss PDFSpencerNo ratings yet
- Non Parametric GuideDocument5 pagesNon Parametric GuideEnrico_LariosNo ratings yet
- Applied Categorical and Count Data Analysis (PDFDrive)Document380 pagesApplied Categorical and Count Data Analysis (PDFDrive)Wasiu Babs50% (2)
- Descriptive and Inferential Statistics Part 1 2013 2014Document134 pagesDescriptive and Inferential Statistics Part 1 2013 2014keehooiNo ratings yet
- R Studio ManualDocument265 pagesR Studio ManualChris HillNo ratings yet
- How To Write A Bibliometric PaperDocument43 pagesHow To Write A Bibliometric PaperNader Ale EbrahimNo ratings yet
- Stats Xi All Chapters PptsDocument2,046 pagesStats Xi All Chapters PptsAnadi AgarwalNo ratings yet
- Study Design Contingency TablesDocument41 pagesStudy Design Contingency TablesDaniel Bondoroi100% (1)
- Manova and MancovaDocument10 pagesManova and Mancovakinhai_seeNo ratings yet
- SPSS Complex Samples 15.0Document211 pagesSPSS Complex Samples 15.0webmailroNo ratings yet
- SAS WorkbookDocument254 pagesSAS WorkbookBrindusa SburleaNo ratings yet
- Spssmissingvalueanalysis 160Document49 pagesSpssmissingvalueanalysis 160Rina BakhtianiNo ratings yet
- IBM SPSS Text Analytics User Guide PDFDocument275 pagesIBM SPSS Text Analytics User Guide PDFrsforscribdNo ratings yet
- Spss ExampleDocument458 pagesSpss Examplegautamabhishek4No ratings yet
- Statistical Computing IDocument187 pagesStatistical Computing IAbebaw AklogNo ratings yet
- SPSS Programming and Data Management, 2nd EditionDocument390 pagesSPSS Programming and Data Management, 2nd EditionHasan100% (2)
- SCJP 5 QuestionsDocument8 pagesSCJP 5 QuestionsashishallthewayNo ratings yet
- Final Report Online SchoolingDocument27 pagesFinal Report Online SchoolingSHAFEEQ UR REHMAN100% (2)
- An KitDocument5 pagesAn KitKirti KumarNo ratings yet
- FE Modeler Users GuideDocument184 pagesFE Modeler Users GuidejemanuelvNo ratings yet
- Future of DistributionDocument6 pagesFuture of DistributionPavan SinghNo ratings yet
- Check To Make Sure You Have The Most Recent Set of AWS Simple Icons Creating DiagramsDocument48 pagesCheck To Make Sure You Have The Most Recent Set of AWS Simple Icons Creating DiagramsarunchockanNo ratings yet
- Veritas Netbackup™ For Hbase Administrator'S Guide: Unix, Windows, and LinuxDocument50 pagesVeritas Netbackup™ For Hbase Administrator'S Guide: Unix, Windows, and Linux黃國峯No ratings yet
- Technical Specification For Portable Handheld XRF (3) ..Document3 pagesTechnical Specification For Portable Handheld XRF (3) ..Razibul IslamNo ratings yet
- Capitulo 3.2Document13 pagesCapitulo 3.2DASNo ratings yet
- SevOne Installation Guide - Virtual Appliance PDFDocument46 pagesSevOne Installation Guide - Virtual Appliance PDFRaphael GalvaoNo ratings yet
- WEG IHM Brochure 50125293 enDocument24 pagesWEG IHM Brochure 50125293 enCarlos SalvatierraNo ratings yet
- Flashing - Guides Real Me 3 ProDocument12 pagesFlashing - Guides Real Me 3 Proswebee23No ratings yet
- Software Design (Lecture 4)Document118 pagesSoftware Design (Lecture 4)louis benNo ratings yet
- SAP GST Questionnaire-MesprosoftDocument3 pagesSAP GST Questionnaire-Mesprosoftnagesh99No ratings yet
- Performancetools PDFDocument340 pagesPerformancetools PDFmrcipamochaqNo ratings yet
- Ba Scalance w788 Xpro RR w74x 1pro RR enDocument276 pagesBa Scalance w788 Xpro RR w74x 1pro RR enshlakiNo ratings yet
- 2015 08 11 - Clinical LOINC and RELMA WorkshopDocument232 pages2015 08 11 - Clinical LOINC and RELMA WorkshopDaniel VreemanNo ratings yet
- Getronics A Balanced Cloud Position WhitepaperDocument4 pagesGetronics A Balanced Cloud Position WhitepaperMauriceRemmeNo ratings yet
- UX Design 101: Swati RaiDocument32 pagesUX Design 101: Swati RaiEliezer Mas y rubiNo ratings yet
- Design & Development of A GSM Based Vehicle Theft Control SystemDocument3 pagesDesign & Development of A GSM Based Vehicle Theft Control SystempatilcmNo ratings yet
- Intro ClementineDocument232 pagesIntro ClementineNirghum RatriNo ratings yet
- Rules For Web Content WritingDocument4 pagesRules For Web Content WritingAbhishek RawatNo ratings yet
- Term Project Advance Computer Architecture Spring 2017: SubmissionDocument3 pagesTerm Project Advance Computer Architecture Spring 2017: SubmissionTofeeq Ur Rehman FASTNUNo ratings yet
- RBG - CRM BRD - Addendum - v1.1 PDFDocument6 pagesRBG - CRM BRD - Addendum - v1.1 PDFManvi PareekNo ratings yet
- Permintaan PCDocument4 pagesPermintaan PCdeny arya wiranataNo ratings yet
- L26M9/L32M9/L42M9/L46M9/ L55M9/LB26R3/LB32R3 LB37R3/LB42R3/LB46R3/ LP55R3/L26K3/L32K3/L42K3Document36 pagesL26M9/L32M9/L42M9/L46M9/ L55M9/LB26R3/LB32R3 LB37R3/LB42R3/LB46R3/ LP55R3/L26K3/L32K3/L42K3Pablo MarmolNo ratings yet
- ariesoGEO Data Collection Setup - Huawei UMTS PDFDocument10 pagesariesoGEO Data Collection Setup - Huawei UMTS PDFWidagdho WidyoNo ratings yet
- Toshiba Satellite S855-S5380 Specs - CNET PDFDocument3 pagesToshiba Satellite S855-S5380 Specs - CNET PDFEloy MacarlupuNo ratings yet