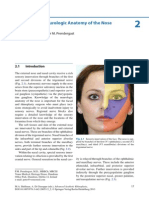
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Retail Analytics (Anna-Lena Sachs)Document126 pagesRetail Analytics (Anna-Lena Sachs)udayraj_v100% (5)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- SWOT Tool Analysis TemplateDocument3 pagesSWOT Tool Analysis TemplateInto HyasintusNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Find Your PowerDocument312 pagesFind Your PowerG Ovalle GarciaNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Resort World SentosaDocument22 pagesResort World Sentosaudayraj_vNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Enron AnalysisDocument6 pagesEnron Analysisudayraj_vNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Enron MaterialDocument4 pagesEnron Materialudayraj_vNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- An Introduction To SQL in SASDocument22 pagesAn Introduction To SQL in SASAnanda BabuNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Con JointDocument39 pagesCon JointRizwan HussainNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Base SAS Guide To Information MapsDocument84 pagesBase SAS Guide To Information Mapsudayraj_vNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- SAS - GIS 9.1 Spatial Data and Procedure GuideDocument220 pagesSAS - GIS 9.1 Spatial Data and Procedure Guideudayraj_vNo ratings yet
- Enron ScandalDocument5 pagesEnron ScandalIshani Bhattacharya0% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Enron MaterialDocument4 pagesEnron Materialudayraj_vNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- 455 Gita RomanDocument224 pages455 Gita RomanjatindbNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Getting Started With SAS 9.1 Text MinerDocument60 pagesGetting Started With SAS 9.1 Text Minerudayraj_vNo ratings yet
- Kaizen BookletDocument71 pagesKaizen Bookletudayraj_vNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Pune TripsDocument28 pagesPune Tripsudayraj_vNo ratings yet
- Infratrochlear Nerve BlockDocument8 pagesInfratrochlear Nerve Blockudayraj_vNo ratings yet
- SAS TXT ImportDocument13 pagesSAS TXT Importudayraj_vNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Chi SquareDocument3 pagesChi SquareankisluckNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- 072-2007 - Calculating Statistics Using PROC MEANS Versus PROC SQDocument8 pages072-2007 - Calculating Statistics Using PROC MEANS Versus PROC SQudayraj_vNo ratings yet
- Picnic SpotsDocument57 pagesPicnic SpotsHarsha ScienceUtsavNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Picnic ListDocument4 pagesPicnic ListtrulyswapNo ratings yet
- Picnic ListDocument4 pagesPicnic ListtrulyswapNo ratings yet
- One Day Trips Across PuneDocument28 pagesOne Day Trips Across Puneudayraj_vNo ratings yet
- BA IntroDocument23 pagesBA Introudayraj_vNo ratings yet
- Picnic SpotsDocument57 pagesPicnic SpotsHarsha ScienceUtsavNo ratings yet
- Major Project Report: Post Graduate Diploma inDocument108 pagesMajor Project Report: Post Graduate Diploma inudayraj_vNo ratings yet
- Kerala - A Paradise On EarthDocument32 pagesKerala - A Paradise On Earthudayraj_vNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Lexmark AssignmentDocument1 pageLexmark Assignmentudayraj_vNo ratings yet
- Cover Letter FormatDocument1 pageCover Letter FormatSid MichaelNo ratings yet
- Himanshu CompaniesDocument9 pagesHimanshu CompaniesSan JayNo ratings yet
- SWOT Analysis of GoogleDocument27 pagesSWOT Analysis of GoogleShafaq KhanNo ratings yet
- DtSearch - EngineDocument4 pagesDtSearch - EngineiyalcNo ratings yet
- Disney PDFDocument6 pagesDisney PDFanimalpoliticoNo ratings yet
- Online Reputation Management Lessons Trump Taught UsDocument3 pagesOnline Reputation Management Lessons Trump Taught UssmentorNo ratings yet
- C.De Voy - ResumeDocument1 pageC.De Voy - ResumeChristy De VoyNo ratings yet
- Inside McKinsey - FTDocument14 pagesInside McKinsey - FTduckbillflyerNo ratings yet
- Comparative Ratio Analysis of Britannia and Cadbury - 58790024Document21 pagesComparative Ratio Analysis of Britannia and Cadbury - 58790024Rahul BasakNo ratings yet
- Forensic Audit ReportDocument16 pagesForensic Audit Reportharshita patni100% (7)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Daniel Malone 2016 Resume JanDocument1 pageDaniel Malone 2016 Resume Janapi-238283045No ratings yet
- Inter Company SalesDocument6 pagesInter Company SalesParvati B100% (1)
- Audit ReportsDocument27 pagesAudit ReportsMa Lourdes T CahatianNo ratings yet
- SAP FI - General LedgerDocument154 pagesSAP FI - General LedgersekhardattaNo ratings yet
- Introduction To Microsoft Word 2007Document25 pagesIntroduction To Microsoft Word 2007dava67No ratings yet
- Debit Note and Credit NoteDocument2 pagesDebit Note and Credit Noteabdul haseebNo ratings yet
- Company ObligationsDocument56 pagesCompany Obligationsacubcn14No ratings yet
- Faraz ShaikhDocument3 pagesFaraz ShaikhchetanNo ratings yet
- EmeraldCityKnights Prologue TheSilverStormDocument9 pagesEmeraldCityKnights Prologue TheSilverStormChristopher Shaplin100% (2)
- Advertising Demand Econ. Day #1-2Document14 pagesAdvertising Demand Econ. Day #1-2Tara MorganNo ratings yet
- Unit 10 Marketing Research and Planning P1Document7 pagesUnit 10 Marketing Research and Planning P1Ovidiu Vintilă0% (1)
- 939x Node B Alarms Reference GuideDocument724 pages939x Node B Alarms Reference GuideAmrit AulakhNo ratings yet
- Ops Amw FRM D en SalesTaxAdjustmentForm AllStatesExceptWA2013Document6 pagesOps Amw FRM D en SalesTaxAdjustmentForm AllStatesExceptWA2013Ma'at MutamuntatNo ratings yet
- Personal Selling - Personal Presentation by The Firm's Sales ForceDocument5 pagesPersonal Selling - Personal Presentation by The Firm's Sales ForceShweta KumariNo ratings yet
- Formato de Auditorias InternasDocument5 pagesFormato de Auditorias InternasFrancisco HernandezNo ratings yet
- Descargar Libros Gratis PDF Carlos Cuauhtemoc SanchezDocument17 pagesDescargar Libros Gratis PDF Carlos Cuauhtemoc SanchezRoberto Carlos Ramos0% (2)
- SSZQ 066 ADocument4 pagesSSZQ 066 AJacob HoltomNo ratings yet
- List of Multinational Corporations - WikipediaDocument9 pagesList of Multinational Corporations - WikipediaNaresh PattanaikNo ratings yet
- Project Report On Vender Management SystemDocument50 pagesProject Report On Vender Management SystemJebin GeorgeNo ratings yet
- Mork ResumeDocument2 pagesMork ResumeAdam ReedNo ratings yet
- Ad Victoriam Named Salesforce Platinum PartnerDocument2 pagesAd Victoriam Named Salesforce Platinum PartnerPR.comNo ratings yet