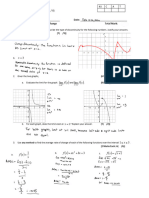
You might also like
- Linear Tech - LTSPICE Getting Started GuideDocument53 pagesLinear Tech - LTSPICE Getting Started GuideSyed Muneeb BukhariNo ratings yet
- GeekGuide Intel MachineLearningDocument27 pagesGeekGuide Intel MachineLearningpumpkinteapot0% (1)
- MATLAB FunctionsDocument6 pagesMATLAB FunctionsAli RameezNo ratings yet
- HammingDocument23 pagesHammingKaushik MandalNo ratings yet
- HW5Document1 pageHW5Kaushik MandalNo ratings yet
- DFT FormulaeDocument1 pageDFT FormulaeKaushik MandalNo ratings yet
- HammingDocument23 pagesHammingKaushik MandalNo ratings yet
- HammingDocument23 pagesHammingKaushik MandalNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Analysis and Design of AlgorithmsDocument4 pagesAnalysis and Design of AlgorithmsSAMAY N. JAINNo ratings yet
- Calculating Rates of Change and DerivativesDocument27 pagesCalculating Rates of Change and DerivativesBereket Desalegn0% (1)
- Derivative of Product and QuotientDocument18 pagesDerivative of Product and QuotientBretana joanNo ratings yet
- Hermite by Dr. Rajesh MathpalDocument29 pagesHermite by Dr. Rajesh MathpalShalini KathirkamuNo ratings yet
- EECS 203: Discrete Mathematics Winter 2019 Discussion 10 - NotesDocument4 pagesEECS 203: Discrete Mathematics Winter 2019 Discussion 10 - NotessamNo ratings yet
- Chap4 - Functions, Pigeonhole PrincipleDocument31 pagesChap4 - Functions, Pigeonhole PrincipleDorian GreyNo ratings yet
- EigenvaluesDocument61 pagesEigenvaluesJUAN CARLOS PAYI LOPEZNo ratings yet
- Greedy Algorithms for Optimization ProblemsDocument39 pagesGreedy Algorithms for Optimization ProblemsHarsh SoniNo ratings yet
- All Periodic Signals of Practical Interest Satisfy These ConditionsDocument2 pagesAll Periodic Signals of Practical Interest Satisfy These ConditionsIstiaque AhmedNo ratings yet
- 2.01) Add Math Module 01 (Functions)Document15 pages2.01) Add Math Module 01 (Functions)cikguruzanaNo ratings yet
- General Mathematics Week 1-Quarter 1Document57 pagesGeneral Mathematics Week 1-Quarter 1Kay Si100% (1)
- Hypergeometric EquationsDocument31 pagesHypergeometric EquationsPriyanshu KumarNo ratings yet
- MCV4U Chapter 1 Assignment - A9d0c550a10552355394502 - 240213 - 153054Document2 pagesMCV4U Chapter 1 Assignment - A9d0c550a10552355394502 - 240213 - 153054Jaideep GillNo ratings yet
- PC Exam ReviewDocument4 pagesPC Exam Reviewklb925No ratings yet
- Finite Cell Method: H-And P-Extension For Embedded Domain Problems in Solid MechanicsDocument13 pagesFinite Cell Method: H-And P-Extension For Embedded Domain Problems in Solid MechanicsAnkur NaraniwalNo ratings yet
- Eigenvalues and EigenvectorsDocument31 pagesEigenvalues and Eigenvectorsanon_351812634No ratings yet
- Generalized Gronwall Inequalities and Their Applications To Fractional Differential EquationsDocument9 pagesGeneralized Gronwall Inequalities and Their Applications To Fractional Differential EquationsSabri Thabet AlamriNo ratings yet
- Chap 2 Laplace TransformDocument15 pagesChap 2 Laplace TransformVĩnh PhongNo ratings yet
- Indefinite and Definite Integration PDFDocument64 pagesIndefinite and Definite Integration PDFGirish KulkarniNo ratings yet
- Quiz 1 Evaluation To Composite FunctionsDocument2 pagesQuiz 1 Evaluation To Composite FunctionsMarvin AzneroNo ratings yet
- MathSlov 50-2000-2 5Document10 pagesMathSlov 50-2000-2 5mirceamercaNo ratings yet
- List of Functions Involving The Error FunctionDocument20 pagesList of Functions Involving The Error FunctionBobNo ratings yet
- Inverse Power Method, Shifted Power Method and DeflationDocument4 pagesInverse Power Method, Shifted Power Method and DeflationM.Y M.ANo ratings yet
- Inequalities RevisedVersion-converted SourangshuDocument21 pagesInequalities RevisedVersion-converted Sourangshufernando_1997No ratings yet
- PCC-CS494 Rakesh MannaDocument1 pagePCC-CS494 Rakesh MannaAbdus SadikNo ratings yet
- Chess and Mathematics: Kim Yong WooDocument141 pagesChess and Mathematics: Kim Yong WooAmar AmôurNo ratings yet
- Quadratic Inequalities: y X y XDocument4 pagesQuadratic Inequalities: y X y XAnthony Mercado LeonardoNo ratings yet
- Republic of the Philippines Department of Education Math ExamDocument4 pagesRepublic of the Philippines Department of Education Math ExamChristine Joy E. Sanchez-CasteloNo ratings yet
- Complex Analysis SolutionsDocument14 pagesComplex Analysis SolutionsKrish Pavan100% (1)
- Final Test Mae101 Fall 2019 HiepttDocument18 pagesFinal Test Mae101 Fall 2019 HiepttNguyễn Duy ĐạtNo ratings yet