You might also like
- IE 527 Intelligent Engineering Systems: Basic Concepts Model/performance Evaluation OverfittingDocument18 pagesIE 527 Intelligent Engineering Systems: Basic Concepts Model/performance Evaluation OverfittinghgfhgfhfNo ratings yet
- ch3 2Document30 pagesch3 2楊喻妃No ratings yet
- Data Mining: Model Overfitting Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument15 pagesData Mining: Model Overfitting Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarYosua SiregarNo ratings yet
- Classification ProblemsDocument53 pagesClassification ProblemsNaveen JaishankarNo ratings yet
- Abhisheksur 121Document8 pagesAbhisheksur 121Abhishek surNo ratings yet
- Classification: Basic Concepts, Decision Trees, and Model EvaluationDocument46 pagesClassification: Basic Concepts, Decision Trees, and Model EvaluationAbdul AowalNo ratings yet
- CS771 IITK EndSem SolutionsDocument8 pagesCS771 IITK EndSem SolutionsAnujNagpal100% (1)
- All Types of Cross ValidationDocument9 pagesAll Types of Cross ValidationPriya dharshini.GNo ratings yet
- Exam Advanced Data Mining Date: 5-11-2009 Time: 14.00-17.00: General RemarksDocument5 pagesExam Advanced Data Mining Date: 5-11-2009 Time: 14.00-17.00: General Remarkskishh28No ratings yet
- A Practical Guide To Support Vector Classi Cation - Chih-Wei Hsu, Chih-Chung Chang and Chih-Jen LinDocument12 pagesA Practical Guide To Support Vector Classi Cation - Chih-Wei Hsu, Chih-Chung Chang and Chih-Jen LinVítor MangaraviteNo ratings yet
- J48Document3 pagesJ48TaironneMatosNo ratings yet
- Exercise 7 Submission Group 12Document22 pagesExercise 7 Submission Group 12Mehmet YalçınNo ratings yet
- 3 1 OverfittingDocument25 pages3 1 OverfittingPriti YadavNo ratings yet
- Assign 3Document5 pagesAssign 3RanaNo ratings yet
- Q. (A) What Are Different Types of Machine Learning? Discuss The DifferencesDocument12 pagesQ. (A) What Are Different Types of Machine Learning? Discuss The DifferencesHassan SaddiquiNo ratings yet
- Pa ZG512 Ec-3r First Sem 2022-2023Document5 pagesPa ZG512 Ec-3r First Sem 2022-20232022mb21301No ratings yet
- Unit 2Document28 pagesUnit 2LOGESH WARAN PNo ratings yet
- ML Interview Questions and AnswersDocument25 pagesML Interview Questions and Answerssantoshguddu100% (1)
- DIT865 2018 Mar SolutionDocument9 pagesDIT865 2018 Mar SolutionEducation VietCoNo ratings yet
- 4 SolvedDocument14 pages4 SolvedKinza ALvi100% (1)
- Review Questions DSDocument14 pagesReview Questions DSSaleh AlizadeNo ratings yet
- Ensemble LearningDocument7 pagesEnsemble LearningGabriel Gheorghe100% (1)
- Bagging and Boosting Regression AlgorithmsDocument84 pagesBagging and Boosting Regression AlgorithmsRaja100% (1)
- Lecture+Notes+Model+ Selection PDFDocument12 pagesLecture+Notes+Model+ Selection PDFSantosh KadamNo ratings yet
- Data Mining Algorithms Predication L6Document7 pagesData Mining Algorithms Predication L6u- m-No ratings yet
- Australasian Data Science and Machine Learning ConferenceDocument15 pagesAustralasian Data Science and Machine Learning ConferenceAnand PaulNo ratings yet
- ML MCQ 1Document5 pagesML MCQ 1Mks KhanNo ratings yet
- Lez 12Document12 pagesLez 12Dino Dwi JayantoNo ratings yet
- Answers For End-Sem Exam Part - 2 (Deep Learning)Document20 pagesAnswers For End-Sem Exam Part - 2 (Deep Learning)Ankur BorkarNo ratings yet
- An Guita 2010Document8 pagesAn Guita 2010NayelyNo ratings yet
- A Comprehensive Guide To Ensemble Learning (With Python Codes)Document21 pagesA Comprehensive Guide To Ensemble Learning (With Python Codes)omegapoint077609No ratings yet
- A Comprehensive Guide To Ensemble Learning (With Python Codes)Document21 pagesA Comprehensive Guide To Ensemble Learning (With Python Codes)omegapoint077609100% (1)
- NEC ML UNIT-III Complete FinalDocument22 pagesNEC ML UNIT-III Complete FinalSamuelNo ratings yet
- Outros Métodos de InferenciasDocument13 pagesOutros Métodos de Inferenciasjoao lucio de souza júniorNo ratings yet
- Data Compression IntroDocument107 pagesData Compression Intromadanram100% (1)
- ML QuestionsDocument31 pagesML QuestionsShubham BakshiNo ratings yet
- Interview QuestionsDocument67 pagesInterview Questionsvaishnav Jyothi100% (1)
- Data Mining Assignment HelpDocument5 pagesData Mining Assignment HelpStatistics Homework SolverNo ratings yet
- SIMSCAPE Optimal Control DesignDocument20 pagesSIMSCAPE Optimal Control DesignwararuNo ratings yet
- Operation Management (MB0048)Document7 pagesOperation Management (MB0048)Sagar TankNo ratings yet
- Gradient Descent AlgorithmDocument5 pagesGradient Descent AlgorithmravinyseNo ratings yet
- Title: Implementation of Decision Tree Classification: Department of Computer Science and EngineeringDocument8 pagesTitle: Implementation of Decision Tree Classification: Department of Computer Science and EngineeringreilyshawnNo ratings yet
- COMP4702 Notes 2019: Week 2 - Supervised LearningDocument23 pagesCOMP4702 Notes 2019: Week 2 - Supervised LearningKelbie DavidsonNo ratings yet
- Compare PSO and GADocument13 pagesCompare PSO and GAKệ ThôiNo ratings yet
- ML Module IiiDocument12 pagesML Module IiiCrazy ChethanNo ratings yet
- A Practical Guide To Support Vector ClassificationDocument16 pagesA Practical Guide To Support Vector ClassificationJônatas Oliveira SilvaNo ratings yet
- Topic: Machine LearningDocument35 pagesTopic: Machine LearningPhuc SJNo ratings yet
- Decision TreesDocument14 pagesDecision TreesJustin Russo Harry50% (2)
- Group9 ABA Ensemble ModelDocument5 pagesGroup9 ABA Ensemble ModelReshma MajumderNo ratings yet
- YadobDocument47 pagesYadobsadeq behbehanianNo ratings yet
- A Gentle Introduction To K-Fold Cross-ValidationDocument69 pagesA Gentle Introduction To K-Fold Cross-ValidationAzeddine RamziNo ratings yet
- Statistics Interview 02Document30 pagesStatistics Interview 02Sudharshan Venkatesh100% (1)
- 201041Document15 pages201041Kimeu EstherNo ratings yet
- SCI2002 DiscreteOptimization deDocument7 pagesSCI2002 DiscreteOptimization deNguyễn Sơn LâmNo ratings yet
- MB0032 Operations ResearchDocument38 pagesMB0032 Operations ResearchSaurabh MIshra12100% (1)
- Efficient Net B0Document4 pagesEfficient Net B0NavyaNo ratings yet
- Integer Optimization and its Computation in Emergency ManagementFrom EverandInteger Optimization and its Computation in Emergency ManagementNo ratings yet
- DATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSFrom EverandDATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSNo ratings yet
- SW MetrologyDocument43 pagesSW Metrologysamirssa2003No ratings yet
- ACID PropertiesDocument6 pagesACID Propertiessamirssa2003No ratings yet
- Resume (Sample)Document11 pagesResume (Sample)Steven ChoNo ratings yet
- How To Build Successful BI StrategyDocument19 pagesHow To Build Successful BI Strategysamirssa2003100% (1)
- Safer ComputingDocument7 pagesSafer Computingsamirssa2003No ratings yet
- Data Mining HealthcareDocument9 pagesData Mining HealthcareKhaled Omar El KafafyNo ratings yet
- ITEss2Mod Answers Moklet Angkatan 15Document59 pagesITEss2Mod Answers Moklet Angkatan 15Atta Cahya P100% (8)
- Interfacing A Hantronix 320 X 240 Graphics Module To An 8-Bit MicrocontrollerDocument8 pagesInterfacing A Hantronix 320 X 240 Graphics Module To An 8-Bit MicrocontrollerAnonymous roFhLslwIFNo ratings yet
- Open Loop Vs Closed LoopDocument3 pagesOpen Loop Vs Closed LoopDonny Priyo Wicaksono100% (1)
- Siemens Mindsphere BrochureDocument3 pagesSiemens Mindsphere BrochureHarshit BhallaNo ratings yet
- Proiect Web Semantic: Colac Mădălin-Carol Tamaș FlorianDocument10 pagesProiect Web Semantic: Colac Mădălin-Carol Tamaș FlorianCristina crissiNo ratings yet
- Sunde: User's Manual For H4 and Earlier ModelsDocument78 pagesSunde: User's Manual For H4 and Earlier ModelsMhegie GaylanNo ratings yet
- Answer: Application Letter Answer: An Application Letter Is A Formal Letter Written To Apply For A Job. An ApplicationDocument4 pagesAnswer: Application Letter Answer: An Application Letter Is A Formal Letter Written To Apply For A Job. An ApplicationRizka AmaliaNo ratings yet
- All About FTP Must ReadDocument7 pagesAll About FTP Must ReadPINOY EUTSECNo ratings yet
- I Love You VirusDocument3 pagesI Love You VirusMr MooNo ratings yet
- The Visual LISP EditorDocument192 pagesThe Visual LISP Editorloopback127xyzNo ratings yet
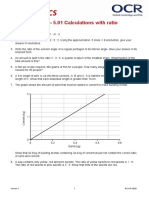
- Higher Check in - 5.01 Calculations With RatioDocument5 pagesHigher Check in - 5.01 Calculations With RatioKyleNo ratings yet
- RICAMBI HX10M - 2008 - l540Document6 pagesRICAMBI HX10M - 2008 - l540Luca FroliNo ratings yet
- AtaquesDocument6 pagesAtaquesJuan JoseNo ratings yet
- Algebra I Eoc Released ItemDocument43 pagesAlgebra I Eoc Released Itemapi-282887866No ratings yet
- 9628 Itspm-RacitemplateDocument8 pages9628 Itspm-RacitemplateRickesh NunkooNo ratings yet
- Frequently Asked Questions For LTE Post-Paid Data Plans March 2022Document6 pagesFrequently Asked Questions For LTE Post-Paid Data Plans March 2022dlaminiz912No ratings yet
- Cristinajungdesign Blogspot PT 2016 03 Exercicios LogotiposDocument11 pagesCristinajungdesign Blogspot PT 2016 03 Exercicios LogotiposHugo AmaralNo ratings yet
- Nesis User ManualDocument132 pagesNesis User ManualFaras AlsaidNo ratings yet
- Econ3150 v12 Note01 PDFDocument6 pagesEcon3150 v12 Note01 PDFRitaSilabanNo ratings yet
- Shift Handover Policy: 1. ScopeDocument3 pagesShift Handover Policy: 1. ScopeBoiler ScrubberNo ratings yet
- PRES - What Is Ed TechDocument19 pagesPRES - What Is Ed TechCris Alvin De GuzmanNo ratings yet
- Options Recommendation Briefing NoteDocument2 pagesOptions Recommendation Briefing NoteAnonymous Esp4JONo ratings yet
- D.lambert ExecutiveSummary SCM-bookDocument24 pagesD.lambert ExecutiveSummary SCM-bookMauricio Portillo G.No ratings yet
- Internet of Things (IoT) Module 1Document37 pagesInternet of Things (IoT) Module 1Richa TengsheNo ratings yet
- Qredo Research PaperDocument21 pagesQredo Research PaperĐào TuấnNo ratings yet
- DN Technoverse East I Academia BrochureDocument6 pagesDN Technoverse East I Academia BrochurethemercilessgoddNo ratings yet
- Arrays and Method-1Document33 pagesArrays and Method-1Collin TilleyNo ratings yet
- Online Voting System SRSDocument7 pagesOnline Voting System SRSSanthosh KumarNo ratings yet
- Lab 2Document29 pagesLab 2Alina PariNo ratings yet
- Xamarin Cross-Platform Development Cookbook - Sample ChapterDocument43 pagesXamarin Cross-Platform Development Cookbook - Sample ChapterPackt Publishing100% (1)
- Doosan DMS3.pdf CodesDocument2 pagesDoosan DMS3.pdf CodesHelder BarrosNo ratings yet