
You might also like
- Python Machine Learning for Beginners: Unsupervised Learning, Clustering, and Dimensionality Reduction. Part 1From EverandPython Machine Learning for Beginners: Unsupervised Learning, Clustering, and Dimensionality Reduction. Part 1No ratings yet
- Comparative Analysis of Minutiae Based Fingerprint Matching AlgorithmsDocument13 pagesComparative Analysis of Minutiae Based Fingerprint Matching AlgorithmsAnonymous Gl4IRRjzNNo ratings yet
- Mixture Models and ApplicationsFrom EverandMixture Models and ApplicationsNizar BouguilaNo ratings yet
- Fingerprint Matching by 06Document13 pagesFingerprint Matching by 06poojamani1990No ratings yet
- Efficient Fingerprint Search Based On Database Clustering: Manhua Liu, Xudong Jiang, Alex Chichung KotDocument11 pagesEfficient Fingerprint Search Based On Database Clustering: Manhua Liu, Xudong Jiang, Alex Chichung KotLuthfiMahendraNo ratings yet
- Bifurcation Structures For Retinal Image Registration & Vessel ExtractionDocument7 pagesBifurcation Structures For Retinal Image Registration & Vessel ExtractionresearchinventyNo ratings yet
- Abstract: Instance-Aware Semantic Segmentation For Autonomous VehiclesDocument7 pagesAbstract: Instance-Aware Semantic Segmentation For Autonomous Vehiclesnishant ranaNo ratings yet
- Data Mining Based On Neural Networks: Fore Word: What Is A Neural Network?Document21 pagesData Mining Based On Neural Networks: Fore Word: What Is A Neural Network?sudheer0553No ratings yet
- International Journal of Engineering Research and Development (IJERD)Document5 pagesInternational Journal of Engineering Research and Development (IJERD)IJERDNo ratings yet
- Structure Matching Algorithm of Fingerprint Minutiae Based On Core PointDocument10 pagesStructure Matching Algorithm of Fingerprint Minutiae Based On Core PointmallusNo ratings yet
- A Study of Various Soft Computing Techniques For Iris RecognitionDocument5 pagesA Study of Various Soft Computing Techniques For Iris RecognitionInternational Organization of Scientific Research (IOSR)No ratings yet
- IEEE 2012 Titles AbstractDocument14 pagesIEEE 2012 Titles AbstractSathiya RajNo ratings yet
- ML Project Proposal Group (Num 10)Document7 pagesML Project Proposal Group (Num 10)wanyonyi kizitoNo ratings yet
- Face Recognition Using Combined Multiscale Anisotropic and Texture Features Based On Sparse CodingDocument15 pagesFace Recognition Using Combined Multiscale Anisotropic and Texture Features Based On Sparse CodingVania V. EstrelaNo ratings yet
- Research Paper On Iris RecognitionDocument5 pagesResearch Paper On Iris Recognitioncnowkfhkf100% (1)
- S A Jameel PaperDocument4 pagesS A Jameel PapersajameelNo ratings yet
- Classification System For Handwritten Devnagari Numeral With A Neural Network ApproachDocument8 pagesClassification System For Handwritten Devnagari Numeral With A Neural Network Approacheditor_ijarcsseNo ratings yet
- Evolution of Gait Biometric System and Algorithms-A Review: Assistant Professor, Vignan's University, Guntur, IndiaDocument6 pagesEvolution of Gait Biometric System and Algorithms-A Review: Assistant Professor, Vignan's University, Guntur, Indiahacked th3No ratings yet
- 2022, Antiocclusion Visual Tracking Algorithm Combining Fully Convolutional Siamese Network and Correlation FilteringDocument9 pages2022, Antiocclusion Visual Tracking Algorithm Combining Fully Convolutional Siamese Network and Correlation FilteringAfaque AlamNo ratings yet
- Human Identification Using Finger ImagesDocument4 pagesHuman Identification Using Finger ImagesesatjournalsNo ratings yet
- File TraceDocument4 pagesFile TraceJaimito MoralesNo ratings yet
- Literature Survey On Fingerprint Recognition Using Level 3 Feature Extraction MethodDocument8 pagesLiterature Survey On Fingerprint Recognition Using Level 3 Feature Extraction MethodBindhu HRNo ratings yet
- Cvpr91-Debby-Paper Segmentation and Grouping of Object Boundaries Using Energy MinimizationDocument15 pagesCvpr91-Debby-Paper Segmentation and Grouping of Object Boundaries Using Energy MinimizationcabrahaoNo ratings yet
- A Literature Review On Iris Segmentation Techniques For Iris Recognition SystemsDocument5 pagesA Literature Review On Iris Segmentation Techniques For Iris Recognition SystemsInternational Organization of Scientific Research (IOSR)No ratings yet
- Image Segmentation: FemurDocument18 pagesImage Segmentation: FemurBoobalan RNo ratings yet
- Genetic Algorithms For Object Recognition IN A: Complex SceneDocument4 pagesGenetic Algorithms For Object Recognition IN A: Complex Scenehvactrg1No ratings yet
- IJETR031551Document6 pagesIJETR031551erpublicationNo ratings yet
- Duplicate Image Detection and Comparison Using Single Core, Multiprocessing, and MultithreadingDocument8 pagesDuplicate Image Detection and Comparison Using Single Core, Multiprocessing, and MultithreadingInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Hiep SNAT R2 - FinalDocument15 pagesHiep SNAT R2 - FinalTrần Nhật TânNo ratings yet
- Anomaly Detection Via Eliminating Data Redundancy and Rectifying Data Error in Uncertain Data StreamsDocument18 pagesAnomaly Detection Via Eliminating Data Redundancy and Rectifying Data Error in Uncertain Data StreamsAnonymous OT4vepNo ratings yet
- Analysis of Time Series Rule Extraction Techniques: Hima Suresh, Dr. Kumudha RaimondDocument6 pagesAnalysis of Time Series Rule Extraction Techniques: Hima Suresh, Dr. Kumudha RaimondInternational Organization of Scientific Research (IOSR)No ratings yet
- A FFT Based Technique For Image Signature Generation: Augusto Celentano and Vincenzo Di LecceDocument10 pagesA FFT Based Technique For Image Signature Generation: Augusto Celentano and Vincenzo Di LecceKrish PrasadNo ratings yet
- Facial Image Noise Removal Via A Trained DictionaryDocument4 pagesFacial Image Noise Removal Via A Trained DictionaryseventhsensegroupNo ratings yet
- IJSCDocument11 pagesIJSCijscNo ratings yet
- Core-Based Structure Matching Algorithm of Fingerprint VerificationDocument5 pagesCore-Based Structure Matching Algorithm of Fingerprint VerificationjimakosjpNo ratings yet
- Enhancement and Segmentation of Historical RecordsDocument19 pagesEnhancement and Segmentation of Historical RecordsCS & ITNo ratings yet
- Pattern RecognitionDocument4 pagesPattern RecognitionGargi ChatNo ratings yet
- A Study On Visualizing Semantically Similar Frequent Patterns in Dynamic DatasetsDocument6 pagesA Study On Visualizing Semantically Similar Frequent Patterns in Dynamic DatasetsInternational Journal of computational Engineering research (IJCER)No ratings yet
- Optimization of Parameters of Neuro-Fuzzy ModelDocument4 pagesOptimization of Parameters of Neuro-Fuzzy ModelTuấn Anh PhanNo ratings yet
- Machine Learning Based Currency Note Recognition Using PythonDocument7 pagesMachine Learning Based Currency Note Recognition Using PythonInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Event Based Imaging Using Neural NetworksDocument6 pagesEvent Based Imaging Using Neural NetworksInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Image Classification Techniques-A SurveyDocument4 pagesImage Classification Techniques-A SurveyInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Literature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle PrintDocument24 pagesLiterature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle Printviju001No ratings yet
- I Jsa It 01132012Document5 pagesI Jsa It 01132012WARSE JournalsNo ratings yet
- Fcrar2004 IrisDocument7 pagesFcrar2004 IrisPrashant PhanseNo ratings yet
- Nust Thesis TemplateDocument4 pagesNust Thesis TemplateCheapCustomPapersPaterson100% (2)
- Effective Brain Segmentation Method Based On MR Physics Image ProcessingDocument14 pagesEffective Brain Segmentation Method Based On MR Physics Image ProcessingAnonymous lt2LFZHNo ratings yet
- Manifold EstimationDocument17 pagesManifold EstimationsarthakNo ratings yet
- On Fingerprint Template Synthesis: Wei-Yun Yau, Kar-Ann Toh, Xudong Jiang, Tai-Pang Chen and Juwei LuDocument6 pagesOn Fingerprint Template Synthesis: Wei-Yun Yau, Kar-Ann Toh, Xudong Jiang, Tai-Pang Chen and Juwei LuLucas AssisNo ratings yet
- Iris Segmentation Methodology For Non-Cooperative RecognitionDocument7 pagesIris Segmentation Methodology For Non-Cooperative Recognitionanon_447732652No ratings yet
- A Comparative Study On Mushrooms ClassificationDocument8 pagesA Comparative Study On Mushrooms ClassificationMuhammad Azhar Fairuzz HilohNo ratings yet
- Object Tracking With Self-Updating Tracking WindowDocument12 pagesObject Tracking With Self-Updating Tracking WindowSaeideh OraeiNo ratings yet
- A Comprehensive Image Segmentation Approach For Image RegistrationDocument5 pagesA Comprehensive Image Segmentation Approach For Image Registrationsurendiran123No ratings yet
- Applying AI To Biometric Identification For Recognizing Text Using One-Hot Encoding and CNNDocument10 pagesApplying AI To Biometric Identification For Recognizing Text Using One-Hot Encoding and CNNInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- A Simple Text-Based Shoulder Surfing ResistantDocument9 pagesA Simple Text-Based Shoulder Surfing Resistantpriyanka badgujarNo ratings yet
- Bruno Abrah Ao Leonardo Barbosa Dept. of Computer Science Universidade Federal de Minas Gerais Belo Horizonte, MG Brazil August 14, 2003Document7 pagesBruno Abrah Ao Leonardo Barbosa Dept. of Computer Science Universidade Federal de Minas Gerais Belo Horizonte, MG Brazil August 14, 2003Yasoda NandanNo ratings yet
- A Novel Approach For Feature Selection and Classifier Optimization Compressed Medical Retrieval Using Hybrid Cuckoo SearchDocument8 pagesA Novel Approach For Feature Selection and Classifier Optimization Compressed Medical Retrieval Using Hybrid Cuckoo SearchAditya Wiha PradanaNo ratings yet
- Article in Press: Recognition of Control Chart Patterns Using An Intelligent TechniqueDocument11 pagesArticle in Press: Recognition of Control Chart Patterns Using An Intelligent TechniquesreeshpsNo ratings yet
- Fuzzy Artmap and Neural Network Approach To Online Processing of Inputs With Missing ValuesDocument7 pagesFuzzy Artmap and Neural Network Approach To Online Processing of Inputs With Missing ValueshdquangNo ratings yet
- Ass 2 of QTDocument2 pagesAss 2 of QTSkyNo ratings yet
- Sotos Syndrome / Cerebral Gigantism /: Clinical SynopsisDocument2 pagesSotos Syndrome / Cerebral Gigantism /: Clinical SynopsisAreef MuarifNo ratings yet
- Rett Syndrome RTT /: OMIM2008 Clinical Synopsis Clinical Synopsis Clinical Synopsis Clinical SynopsisDocument2 pagesRett Syndrome RTT /: OMIM2008 Clinical Synopsis Clinical Synopsis Clinical Synopsis Clinical SynopsisAreef MuarifNo ratings yet
- Cri Du Chat SyndromeDocument2 pagesCri Du Chat SyndromeAreef MuarifNo ratings yet
- Noonan SyndromeDocument3 pagesNoonan SyndromeAreef MuarifNo ratings yet
- Silver Rassell SyndromeDocument2 pagesSilver Rassell SyndromeAreef MuarifNo ratings yet
- Alagille SyndromeDocument2 pagesAlagille SyndromeAreef MuarifNo ratings yet
- VATER AssociationDocument2 pagesVATER AssociationAreef MuarifNo ratings yet
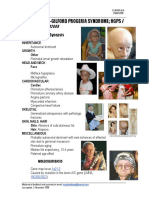
- Progeria SyndromeDocument1 pageProgeria SyndromeAreef MuarifNo ratings yet
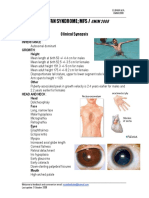
- Marfan SyndromeDocument3 pagesMarfan SyndromeAreef MuarifNo ratings yet
- Down SyndromeDocument2 pagesDown SyndromeAreef MuarifNo ratings yet
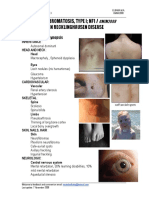
- NeurofibromatosisType IDocument2 pagesNeurofibromatosisType IAreef MuarifNo ratings yet
- Fanconi AnemiaDocument2 pagesFanconi AnemiaAreef MuarifNo ratings yet
- FragileX SyndromeDocument2 pagesFragileX SyndromeAreef MuarifNo ratings yet
- DiGeorge SyndromeDocument3 pagesDiGeorge SyndromeAreef MuarifNo ratings yet
- Pediatric CardiologyDocument6 pagesPediatric CardiologyAreef MuarifNo ratings yet
- CHARGE AssociationDocument2 pagesCHARGE AssociationAreef MuarifNo ratings yet
- Cunha Et Al., 2019 - Art 2Document9 pagesCunha Et Al., 2019 - Art 2Erika SierraNo ratings yet
- Journal 1 PDFDocument9 pagesJournal 1 PDFAntónio Ayrton WidiastaraNo ratings yet
- gjmbsv3n5 16Document6 pagesgjmbsv3n5 16Areef MuarifNo ratings yet
- Angelman Syndrome As Angelman Syndrome As Angelman Syndrome As Angelman Syndrome AsDocument2 pagesAngelman Syndrome As Angelman Syndrome As Angelman Syndrome As Angelman Syndrome AsAreef MuarifNo ratings yet
- Neurodevelopment CMV PDFDocument8 pagesNeurodevelopment CMV PDFAreef MuarifNo ratings yet
- Offline - POSBINDU Meri 10Document21 pagesOffline - POSBINDU Meri 10Areef MuarifNo ratings yet
- Manajemen Hearing Loss PDFDocument15 pagesManajemen Hearing Loss PDFAreef MuarifNo ratings yet
- Herbal Medicine: Current Status and The FutureDocument8 pagesHerbal Medicine: Current Status and The FuturexiuhtlaltzinNo ratings yet
- Dede 5Document5 pagesDede 5Areef MuarifNo ratings yet
- NICE Guidelines PDFDocument41 pagesNICE Guidelines PDFglruvalNo ratings yet
- Dede2 PretermDocument9 pagesDede2 PretermAreef MuarifNo ratings yet
- DikoDocument7 pagesDikoAreef MuarifNo ratings yet
- Hiperbilirubinemia by Ucsf HospitalDocument3 pagesHiperbilirubinemia by Ucsf HospitalGalenica HoneyNo ratings yet
- 85120030402Document3 pages85120030402Areef MuarifNo ratings yet
- Twenty Little Poetry ProjectsDocument3 pagesTwenty Little Poetry Projectsapi-260214370% (1)
- Study ObjectiveDocument2 pagesStudy ObjectiveMiftachudin Arjuna100% (1)
- 2012 - Ref.a Adapatada para ... Concussion-Treatment-Recovery-Guide Return To Learn - Return To Work ... GuidelinesDocument2 pages2012 - Ref.a Adapatada para ... Concussion-Treatment-Recovery-Guide Return To Learn - Return To Work ... GuidelinesLuis Miguel MartinsNo ratings yet
- EL 108 DLP Phrasal Verb 1Document21 pagesEL 108 DLP Phrasal Verb 1Kisha Mae FronterasNo ratings yet
- هامThe Literature ReviewDocument3 pagesهامThe Literature Reviewايهاب غزالة100% (1)
- Global English Olympiad: Class 1 Syllabus & Sample QuestionsDocument3 pagesGlobal English Olympiad: Class 1 Syllabus & Sample QuestionsGuruji Smt Janani SairamNo ratings yet
- Activity 2. Nature vs. NurtureDocument3 pagesActivity 2. Nature vs. NurtureTrisha Anne BataraNo ratings yet
- Intervention/Innovation: Research QuestionsDocument15 pagesIntervention/Innovation: Research Questionsapi-621535429No ratings yet
- Developing A Trauma-Informed Child Welfare SystemDocument9 pagesDeveloping A Trauma-Informed Child Welfare SystemKeii blackhoodNo ratings yet
- What Is Philosophy? (Act 3)Document4 pagesWhat Is Philosophy? (Act 3)Tricia lyxNo ratings yet
- Connors Stalker-Childrens Experiences of DisabilityDocument16 pagesConnors Stalker-Childrens Experiences of DisabilityValentina CroitoruNo ratings yet
- Unit 1 Logic and EpistemologyDocument14 pagesUnit 1 Logic and EpistemologyVishnu MotaNo ratings yet
- Coaching For High PerformanceDocument10 pagesCoaching For High PerformanceHaddy WirayanaNo ratings yet
- Unit: 7 - Changes: Universidad Politécnica Salesiana Del EcuadorDocument27 pagesUnit: 7 - Changes: Universidad Politécnica Salesiana Del EcuadorANDREA JUANINGANo ratings yet
- Visual Information MediaDocument21 pagesVisual Information MediaDiana CabamonganNo ratings yet
- اسئلة كفايات انجليزي لجميع السنواتDocument160 pagesاسئلة كفايات انجليزي لجميع السنواتDar DoomNo ratings yet
- Narcissistic Personality Disorder: Guid 212: Advance Abnormal Psych Presented By: Sandradee O Macaiba MagcDocument16 pagesNarcissistic Personality Disorder: Guid 212: Advance Abnormal Psych Presented By: Sandradee O Macaiba Magcsandradee macaibaNo ratings yet
- English For Specific Purposes: What Is It and Where Is It Taking Us?Document19 pagesEnglish For Specific Purposes: What Is It and Where Is It Taking Us?Tuty AnggrainiNo ratings yet
- Anime Face Generation Using DC-GANsDocument6 pagesAnime Face Generation Using DC-GANsHSSSHSNo ratings yet
- Literature Review Concept Map ExamplesDocument7 pagesLiterature Review Concept Map Examplesc5rr5sqw100% (1)
- Monthly Instructional and Supervisory PlanDocument6 pagesMonthly Instructional and Supervisory PlanTine CristineNo ratings yet
- Distillation Column Control DesignDocument22 pagesDistillation Column Control DesignAnand Dudheliya0% (1)
- HHGGFDocument25 pagesHHGGFgbrbbNo ratings yet
- Priyanka EmotionomicsDocument4 pagesPriyanka EmotionomicsPriyanka GargNo ratings yet
- Jurnal D0213018Document20 pagesJurnal D0213018warta wijayaNo ratings yet
- State Your Own View of Teaching As A CareerDocument3 pagesState Your Own View of Teaching As A CareerChristine MartinezNo ratings yet
- Towards Real Communication in English Lessons in Pacific Primary SchoolsDocument9 pagesTowards Real Communication in English Lessons in Pacific Primary SchoolsnidharshanNo ratings yet
- Shivam SinghDocument1 pageShivam Singhxonib87041No ratings yet
- Writing ObjectivesDocument22 pagesWriting ObjectiveswintermaeNo ratings yet
- Thematic RolesDocument26 pagesThematic RolesripqerNo ratings yet
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Optimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesFrom EverandOptimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesNo ratings yet
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureFrom EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNo ratings yet
- Starting Database Administration: Oracle DBAFrom EverandStarting Database Administration: Oracle DBARating: 3 out of 5 stars3/5 (2)
- THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"From EverandTHE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"Rating: 3 out of 5 stars3/5 (1)
- Joe Celko's SQL for Smarties: Advanced SQL ProgrammingFrom EverandJoe Celko's SQL for Smarties: Advanced SQL ProgrammingRating: 3 out of 5 stars3/5 (1)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]From EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Rating: 5 out of 5 stars5/5 (8)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- DB2 9 System Administration for z/OS: Certification Study Guide: Exam 737From EverandDB2 9 System Administration for z/OS: Certification Study Guide: Exam 737Rating: 3 out of 5 stars3/5 (2)
- Modelling Business Information: Entity relationship and class modelling for Business AnalystsFrom EverandModelling Business Information: Entity relationship and class modelling for Business AnalystsNo ratings yet
- Data Architecture: A Primer for the Data Scientist: A Primer for the Data ScientistFrom EverandData Architecture: A Primer for the Data Scientist: A Primer for the Data ScientistRating: 4.5 out of 5 stars4.5/5 (3)



































































































































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-2-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1714467780?v=1)









