You might also like
- My HintsDocument4 pagesMy Hintsapi-3715433No ratings yet
- Oracle InterviewDocument13 pagesOracle Interviewsubash pradhanNo ratings yet
- Dynamics Trucante Delete Cleanup para Export ImportDocument5 pagesDynamics Trucante Delete Cleanup para Export ImportEduardo MachadoNo ratings yet
- Incrementalstatistics For Partitioned Tables In11gDocument16 pagesIncrementalstatistics For Partitioned Tables In11gSangeeth TalluriNo ratings yet
- Oracle Interview Questions and AnswersDocument23 pagesOracle Interview Questions and Answersjagadish_val100% (2)
- DBMS FileDocument61 pagesDBMS FileRakhi SoniNo ratings yet
- Lab Exercise #3 Tutorial: .Set Record UnformattedDocument3 pagesLab Exercise #3 Tutorial: .Set Record Unformattedshanu_123No ratings yet
- Tuning ScriptsDocument12 pagesTuning Scriptssanjayid1980No ratings yet
- SqlsDocument5 pagesSqlsMohammedabdul muqeetNo ratings yet
- QueryTuning V2Document8 pagesQueryTuning V2Lakshminarayana SamaNo ratings yet
- StructuresDocument98 pagesStructuresVamshi KrishnaNo ratings yet
- Peoplesoft PeoplecodeDocument11 pagesPeoplesoft PeoplecodeKarthik SrmNo ratings yet
- Sqlite C - C++ Tutorial PDFDocument8 pagesSqlite C - C++ Tutorial PDFJonathan Javier Velásquez QuesquénNo ratings yet
- TDEDocument5 pagesTDEAsuncion ValadezNo ratings yet
- Dbms Complete Lab ManualDocument86 pagesDbms Complete Lab ManualAsif AmeerNo ratings yet
- LAB Manual - PART A - PLSQLDocument8 pagesLAB Manual - PART A - PLSQLNafsNo ratings yet
- Oracle Data Pump in Oracle Database 10g: Getting StartedDocument10 pagesOracle Data Pump in Oracle Database 10g: Getting StartedVinoth KumarNo ratings yet
- Oracle Database Administration: How Does One Create A New Database?Document45 pagesOracle Database Administration: How Does One Create A New Database?Elango GopalNo ratings yet
- TSQL and Index Cheat SheetDocument16 pagesTSQL and Index Cheat SheetMehmood SulimanNo ratings yet
- Oracle Important NotesDocument129 pagesOracle Important Notesapi-3819698No ratings yet
- Wait Event - Latch: Row Cache Objects - DC - ObjectsDocument11 pagesWait Event - Latch: Row Cache Objects - DC - Objectswilliam_tang_45No ratings yet
- COMP230 Wk7 Lab InstructionsDocument8 pagesCOMP230 Wk7 Lab InstructionsAlex J Church0% (2)
- 2d-String Arrays & FunctionsDocument21 pages2d-String Arrays & FunctionsFarhanNo ratings yet
- Db2 Cheat SheetDocument6 pagesDb2 Cheat Sheetsaurav_itNo ratings yet
- Interface PDFDocument31 pagesInterface PDFJoshua MeyerNo ratings yet
- Workload Characterization Using DBA - HIST Tables and Ksar Karl Arao's Blog PDFDocument15 pagesWorkload Characterization Using DBA - HIST Tables and Ksar Karl Arao's Blog PDFModesto Lopez RamosNo ratings yet
- Interview QuestionsDocument36 pagesInterview QuestionsTraian TurmacNo ratings yet
- Dbms Complete Lab ManualDocument184 pagesDbms Complete Lab Manualrajat7169451734No ratings yet
- Storing Data Directly From Oracle SGADocument9 pagesStoring Data Directly From Oracle SGAKaramela MelakaraNo ratings yet
- Oracle StreamsDocument17 pagesOracle StreamsdaidkumarNo ratings yet
- Simulated Annealing For The Optimisation of A Constrained Simulation Model in ExcellDocument19 pagesSimulated Annealing For The Optimisation of A Constrained Simulation Model in Excelllcm3766lNo ratings yet
- AssignmentDocument7 pagesAssignmentpradeep100% (1)
- WATS Database Export Import RecommendationDocument6 pagesWATS Database Export Import RecommendationSreekanth ReddyNo ratings yet
- Rdbms FinalDocument22 pagesRdbms FinalSriji VijayNo ratings yet
- Oracle Scripts1Document37 pagesOracle Scripts1marepallyNo ratings yet
- Cs 502 Lab Manual FinalDocument27 pagesCs 502 Lab Manual FinalAmit Kumar SahuNo ratings yet
- Beginners Guide To PLX DAQ v2 by Net Devil: Serial - PrintlnDocument9 pagesBeginners Guide To PLX DAQ v2 by Net Devil: Serial - PrintlnoscarNo ratings yet
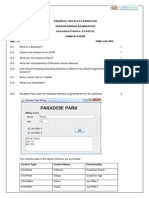
- CBSE Class 11 Informatics Practices Sample Paper-01 (Solved)Document10 pagesCBSE Class 11 Informatics Practices Sample Paper-01 (Solved)cbsesamplepaper83% (24)
- Database - Interview Questions For YouDocument7 pagesDatabase - Interview Questions For YouSA1234567No ratings yet
- ChangemanDocument57 pagesChangemanmeeramf69No ratings yet
- (CSE3083) Lab Practical Assignment #6Document11 pages(CSE3083) Lab Practical Assignment #6ShreyshNo ratings yet
- Sap Sybase Replication Server Internals and Performance TuningDocument36 pagesSap Sybase Replication Server Internals and Performance Tuningprasadn66No ratings yet
- Database Performance Tuning by ExamplesDocument16 pagesDatabase Performance Tuning by ExamplesTejaswi SedimbiNo ratings yet
- VSAM Sample Interview QuestionsDocument4 pagesVSAM Sample Interview QuestionsVarun ViswanathanNo ratings yet
- VSAM Interview Questions and Answers.Document5 pagesVSAM Interview Questions and Answers.Sweta SinghNo ratings yet
- Spatial Database Lab1 PostgreSQL Tutorial I GUIDocument11 pagesSpatial Database Lab1 PostgreSQL Tutorial I GUIpaulo30ricardo50% (2)
- VSAM Interview Questions: 1. What Are The Different Types of VSAM Files Available?Document5 pagesVSAM Interview Questions: 1. What Are The Different Types of VSAM Files Available?flyfortNo ratings yet
- Lab-Exercise-3 CSE324 (PL/SQL) Batch-B1: 2. Apply The Alter Command (Add Primary Key, Drop Column, Drop Constraint)Document16 pagesLab-Exercise-3 CSE324 (PL/SQL) Batch-B1: 2. Apply The Alter Command (Add Primary Key, Drop Column, Drop Constraint)Devashish SharmaNo ratings yet
- Dbms Complete Lab ManualDocument177 pagesDbms Complete Lab ManualMouniga Ve75% (4)
- Sintax English FinalDocument40 pagesSintax English FinalQuinnNo ratings yet
- Qs 21-25Document5 pagesQs 21-25api-248569118No ratings yet
- SQL NotesDocument13 pagesSQL NotesHarryNo ratings yet
- K L University Department of Computer Science & Engineering II/IV B.Tech Semester II Database Management Systems (13CS204) TEST-2 KeyDocument8 pagesK L University Department of Computer Science & Engineering II/IV B.Tech Semester II Database Management Systems (13CS204) TEST-2 KeyRami ReddyNo ratings yet
- K L University Department of Computer Science & Engineering II/IV B.Tech Semester II Database Management Systems (13CS204) TEST-2 KeyDocument8 pagesK L University Department of Computer Science & Engineering II/IV B.Tech Semester II Database Management Systems (13CS204) TEST-2 KeyRami ReddyNo ratings yet
- Curse Feb 28.02-01.03Document12 pagesCurse Feb 28.02-01.03cretuiulia1984No ratings yet
- Interview Questions for IBM Mainframe DevelopersFrom EverandInterview Questions for IBM Mainframe DevelopersRating: 1 out of 5 stars1/5 (1)
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationFrom EverandPractical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationNo ratings yet
- MVS JCL Utilities Quick Reference, Third EditionFrom EverandMVS JCL Utilities Quick Reference, Third EditionRating: 5 out of 5 stars5/5 (1)
- All About Tracing Oracle SQL SessionsDocument12 pagesAll About Tracing Oracle SQL SessionsSHAHID FAROOQNo ratings yet
- Fazli Anwar e ElahiDocument95 pagesFazli Anwar e ElahiSHAHID FAROOQNo ratings yet
- Understand Sultan Bahu Poetry by Sharief Sabir WorkDocument216 pagesUnderstand Sultan Bahu Poetry by Sharief Sabir WorkSHAHID FAROOQNo ratings yet
- Tears of Rasool PBUH UrduDocument72 pagesTears of Rasool PBUH Urduapi-3704968100% (3)
- Baba Bulehshah Punjabi Read PDF FormatDocument440 pagesBaba Bulehshah Punjabi Read PDF FormatSHAHID FAROOQNo ratings yet
- Dil Daryia SamundarDocument303 pagesDil Daryia SamundarSHAHID FAROOQNo ratings yet
- Remedies From The Holy Qur'AnDocument79 pagesRemedies From The Holy Qur'Anislamiq98% (220)
- Ibtidai Suluk (Urdu)Document28 pagesIbtidai Suluk (Urdu)Jalalludin Ahmad Ar-Rowi100% (1)
- Syeda Fatima (A.s)Document71 pagesSyeda Fatima (A.s)Syed Imran Shah100% (1)
- Waseela Mufti M Faiz Awasi Qadri UrduDocument28 pagesWaseela Mufti M Faiz Awasi Qadri UrduSHAHID FAROOQNo ratings yet
- Was Eel ADocument158 pagesWas Eel ASHAHID FAROOQNo ratings yet
- Wazu Ka TareekaDocument20 pagesWazu Ka TareekaSHAHID FAROOQNo ratings yet
- Tabarrakut (Relics) Are Blessings (Urdu)Document64 pagesTabarrakut (Relics) Are Blessings (Urdu)faisal.noori5932No ratings yet
- Anguthay ChoomnaDocument90 pagesAnguthay ChoomnaISLAMIC LIBRARYNo ratings yet
- Complete 136Document25 pagesComplete 136ISLAMIC LIBRARYNo ratings yet
- Nuh Ha Mim Keller - Kalam and IslamDocument14 pagesNuh Ha Mim Keller - Kalam and IslamMTYKK100% (8)
- Hujjat Allah Al-Baligha (Arabic / Urdu) by Shah Waliullah / Shah Wali UllahDocument1 pageHujjat Allah Al-Baligha (Arabic / Urdu) by Shah Waliullah / Shah Wali UllahRana Mazhar75% (4)
- Sultan Bahu PoetryDocument216 pagesSultan Bahu PoetrySHAHID FAROOQNo ratings yet
- Sirr Al Israr Urdu by Sh. Gilani R.ADocument204 pagesSirr Al Israr Urdu by Sh. Gilani R.ASHAHID FAROOQNo ratings yet
- Nijasaton Kee Pehchaan (Urdu)Document23 pagesNijasaton Kee Pehchaan (Urdu)faisal.noori5932No ratings yet
- Remedies From The Holy Qur'AnDocument79 pagesRemedies From The Holy Qur'Anislamiq98% (220)
- Imam-e-Aazam Awr Imam Bukhari (Nisbat o Taaluq Awr Wajuhaat e Adam-e-Riwayat) Part-2Document66 pagesImam-e-Aazam Awr Imam Bukhari (Nisbat o Taaluq Awr Wajuhaat e Adam-e-Riwayat) Part-2MinhajBooksNo ratings yet
- Fatuh Al Ghaib Urdu by Sh. Gilani R.A Urdu TranslationDocument167 pagesFatuh Al Ghaib Urdu by Sh. Gilani R.A Urdu TranslationSHAHID FAROOQ100% (4)
- Dreams in Islam - The Window To The Heart! by Shaikh. Imran Nazar HoseinDocument105 pagesDreams in Islam - The Window To The Heart! by Shaikh. Imran Nazar Hoseinm.suh100% (10)
- Aqeedah WastiyahDocument97 pagesAqeedah Wastiyahapi-3700670No ratings yet
- Hazrat Fatima Sayeda e Qainaat (R.A)Document122 pagesHazrat Fatima Sayeda e Qainaat (R.A)Faisal MalikNo ratings yet
- Biography of Naqhsbandi Shuyukh (Urdu)Document108 pagesBiography of Naqhsbandi Shuyukh (Urdu)Talib Ghaffari100% (1)
- Dil Daryia SamundarDocument303 pagesDil Daryia SamundarSHAHID FAROOQNo ratings yet
- Naat - Subze Gumbad Kay Sayee MainDocument200 pagesNaat - Subze Gumbad Kay Sayee MainKaleem Ahmed100% (10)
- 99 Perfect Names and Attributes of AllahDocument5 pages99 Perfect Names and Attributes of AllahSHAHID FAROOQNo ratings yet
- Stulz C7000R 01 PDFDocument198 pagesStulz C7000R 01 PDFNarciso Torres0% (1)
- Pakistan Wapda - Power Wing: Standard Operating ProceduresDocument8 pagesPakistan Wapda - Power Wing: Standard Operating Procedureszahra batoolNo ratings yet
- Precast Concrete ConstructionDocument37 pagesPrecast Concrete ConstructionRuta Parekh100% (1)
- Thing in Itself Kantian: AnstoßDocument1 pageThing in Itself Kantian: Anstoßwhynotbequiet23No ratings yet
- Sample Question Paper Computer GraphicsDocument4 pagesSample Question Paper Computer Graphicsrohit sanjay shindeNo ratings yet
- Virtual Screening of Natural Products DatabaseDocument71 pagesVirtual Screening of Natural Products DatabaseBarbara Arevalo Ramos100% (1)
- Data Analaysis and InterpretationDocument56 pagesData Analaysis and Interpretationporkodisvl100% (2)
- Student Teacher InterviewDocument3 pagesStudent Teacher InterviewLauren ColeNo ratings yet
- 13 y 14. Schletter-SingleFix-V-Data-SheetDocument3 pages13 y 14. Schletter-SingleFix-V-Data-SheetDiego Arana PuelloNo ratings yet
- SQAAU SM Assignment BriefDocument10 pagesSQAAU SM Assignment BriefJamil NassarNo ratings yet
- Procedure Issuing EtaDocument5 pagesProcedure Issuing EtaCarlos FrançaNo ratings yet
- Software Testing and Quality AssuranceDocument26 pagesSoftware Testing and Quality Assurancemanoj hNo ratings yet
- PMP Itto GuideDocument11 pagesPMP Itto GuideSocrates XavierNo ratings yet
- Acceptance To An Offer Is What A Lighted Matchstick Is To A Train of GunpowderDocument2 pagesAcceptance To An Offer Is What A Lighted Matchstick Is To A Train of GunpowderAnushka SharmaNo ratings yet
- List of BooksDocument13 pagesList of Booksbharan16No ratings yet
- Intro To RMAN-10g-okDocument41 pagesIntro To RMAN-10g-okAnbao ChengNo ratings yet
- IB Biology Lab Report TemplateDocument6 pagesIB Biology Lab Report TemplatebigbuddhazNo ratings yet
- SOS Children's Village: by Bekim RamkuDocument21 pagesSOS Children's Village: by Bekim RamkuAbdulKerim AyubNo ratings yet
- JSREP Volume 38 Issue 181ج3 Page 361 512Document52 pagesJSREP Volume 38 Issue 181ج3 Page 361 512ahmed oudaNo ratings yet
- Journal Publishing ProcessDocument1 pageJournal Publishing Processmohamedr55104No ratings yet
- Acm 003Document5 pagesAcm 003Roan BNo ratings yet
- Slab Culvert Irc 21 Irc 112Document5 pagesSlab Culvert Irc 21 Irc 112Rupendra palNo ratings yet
- Recent Advances in Second Generation Bioethanol Production An Insight To Pretreatment, Saccharification and Fermentation ProcessesDocument11 pagesRecent Advances in Second Generation Bioethanol Production An Insight To Pretreatment, Saccharification and Fermentation ProcessesBryant CoolNo ratings yet
- Lesson PlanDocument11 pagesLesson PlanKim Gabrielle Del PuertoNo ratings yet
- 2020 Sec 4 E Math SA2 Anderson Secondary-pages-DeletedDocument41 pages2020 Sec 4 E Math SA2 Anderson Secondary-pages-Deletedregi naNo ratings yet
- CELCHA2 Practical Manual 2022Document51 pagesCELCHA2 Practical Manual 2022Gee DevilleNo ratings yet
- Tssiig GC e Module 1 PDFDocument6 pagesTssiig GC e Module 1 PDFLoiweza AbagaNo ratings yet
- Upload Infotype 2006 (Absence Quotas) - Code Gallery - SCN WikiDocument3 pagesUpload Infotype 2006 (Absence Quotas) - Code Gallery - SCN WikiArun Varshney (MULAYAM)No ratings yet
- Metaphor-Spatiality-Discourse - 10-11 July 2020 - Programme - FINALDocument6 pagesMetaphor-Spatiality-Discourse - 10-11 July 2020 - Programme - FINALkostyelNo ratings yet
- OffGrid enDocument36 pagesOffGrid enYordan StoyanovNo ratings yet