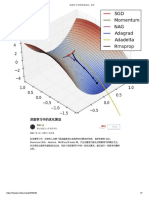
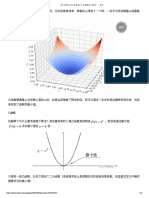
You might also like
- 深度学习中的优化算法 - 知乎Document7 pages深度学习中的优化算法 - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 2 - 知乎Document9 pages什么是梯度下降法 - 2 - 知乎Yang CaoNo ratings yet
- 单变量微积分 - 马同学 - - Anna's ArchiveDocument777 pages单变量微积分 - 马同学 - - Anna's Archive0919aprilNo ratings yet
- 2011694 吴辉 强化学习第六次课程作业Document12 pages2011694 吴辉 强化学习第六次课程作业2739557203No ratings yet
- Course 06Document58 pagesCourse 06LLNo ratings yet
- (5) 规则化和模型选择Document5 pages(5) 规则化和模型选择骨木No ratings yet
- 程式流程控制Document20 pages程式流程控制李昱陞No ratings yet
- 基于序列二次规划算法的发动机性能寻优控制 孙丰诚Document6 pages基于序列二次规划算法的发动机性能寻优控制 孙丰诚leeNo ratings yet
- Chap02 机器学习基本问题Document56 pagesChap02 机器学习基本问题Me MeNo ratings yet
- EM算法与GMM模型Document13 pagesEM算法与GMM模型wulinjun1360943519No ratings yet
- Book3 Ch19 优化入门 数学要素 从加减乘除到机器学习Document24 pagesBook3 Ch19 优化入门 数学要素 从加减乘除到机器学习James JiangNo ratings yet
- Generative Models 大纲Document11 pagesGenerative Models 大纲Jun WangNo ratings yet
- AMC10公式 犀牛国际教育Document25 pagesAMC10公式 犀牛国际教育wliNo ratings yet
- 来煜坤 把握本质,灵活运用 动态规划的深入探讨Document37 pages来煜坤 把握本质,灵活运用 动态规划的深入探讨visitworldNo ratings yet
- 第6章 Logistic回归Document75 pages第6章 Logistic回归Yancy YinNo ratings yet
- 有限元杂谈1 基础Document10 pages有限元杂谈1 基础Zhiqiang GuNo ratings yet
- ML别人笔记Document14 pagesML别人笔记yerly XNo ratings yet
- 面试题答案 40万年薪岗位面试到底问些什么?Document41 pages面试题答案 40万年薪岗位面试到底问些什么?Lewis HsiaNo ratings yet
- 机器学习公式详解Document243 pages机器学习公式详解zongfei huNo ratings yet
- 機器學習書面報告Document26 pages機器學習書面報告Andy ChenNo ratings yet
- 统计学习方法Document303 pages统计学习方法lianghongruiNo ratings yet
- 第7章Document58 pages第7章Sean UsosNo ratings yet
- 大型稀疏法方程组的代数多重网格解法Document4 pages大型稀疏法方程组的代数多重网格解法Jian LinNo ratings yet
- 选修 oracle分析函数Document22 pages选修 oracle分析函数wu zhaiNo ratings yet
- UntitledDocument459 pagesUntitled张玉洁No ratings yet
- patran常见问题与技巧锦集Document21 pagespatran常见问题与技巧锦集scoymNo ratings yet
- 结合分层和ADMM的高光谱图像解混方法 房森Document7 pages结合分层和ADMM的高光谱图像解混方法 房森zhoujianjunNo ratings yet
- 5-1 機器學習Document59 pages5-1 機器學習宮伊恩No ratings yet
- 30 Meta LearningDocument20 pages30 Meta Learningyeqing3766808No ratings yet
- 什么是梯度下降法 - 1 - 知乎Document11 pages什么是梯度下降法 - 1 - 知乎Yang CaoNo ratings yet
- SVM算法Document40 pagesSVM算法wulinjun1360943519No ratings yet
- 什么是梯度下降法 - 1 - 知乎Document11 pages什么是梯度下降法 - 1 - 知乎Yang CaoNo ratings yet
- 并行求解多维递归方程组的三... Krylov子空间迭代方法 李芳Document4 pages并行求解多维递归方程组的三... Krylov子空间迭代方法 李芳shang zhangNo ratings yet
- 如何记住所有的三角函数公式? - 知乎Document8 pages如何记住所有的三角函数公式? - 知乎Yang CaoNo ratings yet
- VASP计算的理论及实践总结Document18 pagesVASP计算的理论及实践总结Qi LIUNo ratings yet
- 曹钦翔 线性规划与网络流Document51 pages曹钦翔 线性规划与网络流CothraxNo ratings yet
- Ch12345Homework 20210219xgDocument5 pagesCh12345Homework 20210219xgAmyNo ratings yet
- 吴恩达倾情推荐!这28张图全解深度学习知识真棒! - 知乎Document32 pages吴恩达倾情推荐!这28张图全解深度学习知识真棒! - 知乎Yang CaoNo ratings yet
- 改进的NSGA II算法及其在星座优化设计中的应用Document7 pages改进的NSGA II算法及其在星座优化设计中的应用chenbeiliuhuoNo ratings yet
- 统计学习方法李航 (非扫描版)Document209 pages统计学习方法李航 (非扫描版)Titus toiNo ratings yet
- ArcGIS地统计分析实习指导书Document41 pagesArcGIS地统计分析实习指导书tiantiger61No ratings yet
- Graph-based slam_ A surveyDocument14 pagesGraph-based slam_ A surveybob wuNo ratings yet
- (1) 线性回归、logistic回归和一般回归Document9 pages(1) 线性回归、logistic回归和一般回归骨木No ratings yet
- 计量经济学:多元线性回归的最小二乘估计 - 知乎Document6 pages计量经济学:多元线性回归的最小二乘估计 - 知乎gotohbsusNo ratings yet
- 杂波环境下被动多传感器机动目标跟踪新算法Document4 pages杂波环境下被动多传感器机动目标跟踪新算法gaolin19901014No ratings yet
- 概率论总结Document4 pages概率论总结CalonNo ratings yet
- 第6章 参数估计(2020)Document146 pages第6章 参数估计(2020)落玥No ratings yet
- 基于改进混沌搜索算法的机器人轨迹规划Document5 pages基于改进混沌搜索算法的机器人轨迹规划lin imeaNo ratings yet
- UntitledDocument28 pagesUntitledchinreiNo ratings yet
- 机器学习试题Document10 pages机器学习试题Tong ChengNo ratings yet
- 物冶Document17 pages物冶傅豐樺No ratings yet
- 第8讲位姿与点的估计问题Document31 pages第8讲位姿与点的估计问题yiyitusoNo ratings yet
- 1 入门Document47 pages1 入门Johanna YeNo ratings yet
- 2022机器学习考题Document7 pages2022机器学习考题enzezhuucasNo ratings yet
- 改进多目标进化算法NSGA II运行效率的方法Document2 pages改进多目标进化算法NSGA II运行效率的方法Jiangfeng GuoNo ratings yet
- 统计学习方法 李航Document393 pages统计学习方法 李航Yurem AnnabelleNo ratings yet
- 数值分析2011Document662 pages数值分析2011曹倬玮No ratings yet
- CUMCM2013B 讲评Document23 pagesCUMCM2013B 讲评朱元章No ratings yet
- 第5章 边缘检测与图像分割Document184 pages第5章 边缘检测与图像分割陈志宣No ratings yet
- 作者: 陳鍾誠 單位: 金門技術學院資管系 Email:Document12 pages作者: 陳鍾誠 單位: 金門技術學院資管系 Email:陳鍾誠No ratings yet
- 排程 - 行程的執行順序安排問題Document36 pages排程 - 行程的執行順序安排問題陳鍾誠No ratings yet
- Email: Ccc@Kmit - Edu.tw URL: HTTP://CCC - Kmit.edu - TWDocument17 pagesEmail: Ccc@Kmit - Edu.tw URL: HTTP://CCC - Kmit.edu - TW陳鍾誠No ratings yet
- 98 上 金門技術學院 資工三 學號: 姓名Document2 pages98 上 金門技術學院 資工三 學號: 姓名陳鍾誠No ratings yet
- 98 上 金門技術學院 資訊工程系 人工智慧 期末考 學號Document2 pages98 上 金門技術學院 資訊工程系 人工智慧 期末考 學號陳鍾誠No ratings yet
- 作者: 陳鍾誠 單位: 金門技術學院資管系 Email:Document12 pages作者: 陳鍾誠 單位: 金門技術學院資管系 Email:陳鍾誠No ratings yet
- 98 上 金門技術學院 資訊工程系 視窗程式設計 期中考 學號Document2 pages98 上 金門技術學院 資訊工程系 視窗程式設計 期中考 學號陳鍾誠No ratings yet
- 97 上 金門技術學院 資工系 日四技二 視窗 程式設計Document3 pages97 上 金門技術學院 資工系 日四技二 視窗 程式設計陳鍾誠No ratings yet
- 輸出入控制Document79 pages輸出入控制陳鍾誠No ratings yet
- 記憶體映射 i/o 輸出入Document4 pages記憶體映射 i/o 輸出入陳鍾誠No ratings yet
- 98 上 金門技術學院 資工三 學號: 姓名Document3 pages98 上 金門技術學院 資工三 學號: 姓名陳鍾誠No ratings yet
- 97 上 金門技術學院 資工系 日四技二 視窗 程式設計Document4 pages97 上 金門技術學院 資工系 日四技二 視窗 程式設計陳鍾誠No ratings yet
- 註:本章學術性較重,但考試常考。Document35 pages註:本章學術性較重,但考試常考。陳鍾誠No ratings yet
- 作業系統的結構Document16 pages作業系統的結構陳鍾誠No ratings yet
- 金門技術學院 97 上 四技四 嵌入式軟體開發工具 系統程式 期中考Document4 pages金門技術學院 97 上 四技四 嵌入式軟體開發工具 系統程式 期中考陳鍾誠No ratings yet
- 95 學年 上學期 金門技術學院 資管系 夜二技 一年級Document2 pages95 學年 上學期 金門技術學院 資管系 夜二技 一年級陳鍾誠No ratings yet
- 97 學年 上學期 金門技術學院 資管系 日四技二年級 視窗Document4 pages97 學年 上學期 金門技術學院 資管系 日四技二年級 視窗陳鍾誠No ratings yet
- 行程的概念Document36 pages行程的概念陳鍾誠No ratings yet
- 97 學年 下學期 金門技術學院 資訊工程系 日四技三年級 網路Document3 pages97 學年 下學期 金門技術學院 資訊工程系 日四技三年級 網路陳鍾誠No ratings yet
- 97 學年 下學期 金門技術學院 資訊工程系 日四技四年級 計算機組織Document3 pages97 學年 下學期 金門技術學院 資訊工程系 日四技四年級 計算機組織陳鍾誠No ratings yet
- 96 學年 上學期 金門技術學院 資管系 夜二技 二年級Document2 pages96 學年 上學期 金門技術學院 資管系 夜二技 二年級陳鍾誠No ratings yet
- 96 學年 上學期 金門技術學院 資管系 日四技三年級 作業系統Document2 pages96 學年 上學期 金門技術學院 資管系 日四技三年級 作業系統陳鍾誠No ratings yet
- 96 學年下學期 金門技術學院 資管系日四技三年級 編譯器 期末考 出題者Document4 pages96 學年下學期 金門技術學院 資管系日四技三年級 編譯器 期末考 出題者陳鍾誠No ratings yet
- 多工與中斷機制Document18 pages多工與中斷機制陳鍾誠No ratings yet
- 死結的處理Document29 pages死結的處理陳鍾誠No ratings yet
- 同步的經典問題Document11 pages同步的經典問題陳鍾誠No ratings yet
- 96 學年下學期 金門技術學院 資管系日四技三年級 系統程式 期中考 (補考)Document3 pages96 學年下學期 金門技術學院 資管系日四技三年級 系統程式 期中考 (補考)陳鍾誠No ratings yet
- 96 學年下學期 金門技術學院 資管系日四技三年級 編譯器 期末考 出題者Document3 pages96 學年下學期 金門技術學院 資管系日四技三年級 編譯器 期末考 出題者陳鍾誠No ratings yet
- 大量儲存系統Document2 pages大量儲存系統陳鍾誠No ratings yet
- 95 學年 上學期 金門技術學院 資管系 日四技 一年級Document3 pages95 學年 上學期 金門技術學院 資管系 日四技 一年級陳鍾誠No ratings yet