You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Sugandha CVDocument3 pagesSugandha CVShish ChoudharyNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Haccp Ice CreamDocument14 pagesHaccp Ice CreamJaykishan ParmarNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- An Approach To Building An Integrated Management System Based On ISO 9001:2000, ISO 27001:2005 and OPM3 International Standards in Services CompaniesDocument14 pagesAn Approach To Building An Integrated Management System Based On ISO 9001:2000, ISO 27001:2005 and OPM3 International Standards in Services CompaniesShish ChoudharyNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Pristine Plus+ Miniral WaterDocument9 pagesPristine Plus+ Miniral WaterShish ChoudharyNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Shish Ram BDE Pristine Plus Mineral Water & R.O.Document3 pagesShish Ram BDE Pristine Plus Mineral Water & R.O.Shish ChoudharyNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Amity University Summer Training Project PROBLEM IDENTIFICATION AND RECTIFICATION IN CLAIM SETTLEMENT", IN JOHNSON & JOHNSON, SHISH RAM KHARESIYA LAKHANI BDE Pristine PLUS+Document97 pagesAmity University Summer Training Project PROBLEM IDENTIFICATION AND RECTIFICATION IN CLAIM SETTLEMENT", IN JOHNSON & JOHNSON, SHISH RAM KHARESIYA LAKHANI BDE Pristine PLUS+Shish ChoudharyNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Offer Latter Sample by SHISH RAM KHARESIYA SAMS IBM IHM VARANASIDocument1 pageOffer Latter Sample by SHISH RAM KHARESIYA SAMS IBM IHM VARANASIShish ChoudharyNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Characteristics of Facility Service Industry and Effects On Buyer-Supplier RelationshipsDocument20 pagesCharacteristics of Facility Service Industry and Effects On Buyer-Supplier RelationshipsShish ChoudharyNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Hot& Natural Love Tips SHISH MBA SAMS IBM VARANASIDocument8 pagesHot& Natural Love Tips SHISH MBA SAMS IBM VARANASIShish ChoudharyNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- What Is A Traning SHISH MBA SAMS IBM VARANASIDocument11 pagesWhat Is A Traning SHISH MBA SAMS IBM VARANASIShish ChoudharyNo ratings yet
- Summer Training Project On HDC Bank Varanasi SHISH MBA SAMS IBM VaranasiDocument85 pagesSummer Training Project On HDC Bank Varanasi SHISH MBA SAMS IBM VaranasiShish ChoudharyNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Analogical Models Shish Mba Sams Ibm VaranasiDocument2 pagesAnalogical Models Shish Mba Sams Ibm VaranasiShish ChoudharyNo ratings yet
- LcveDocument15 pagesLcvejananiwimukthiNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- BCA 5 Shish Mba Sams Ibm VaranasiDocument6 pagesBCA 5 Shish Mba Sams Ibm VaranasiShish ChoudharyNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Full - Report On Direct Tax Shish Mba Sams Ibm Varanasi IndiaDocument95 pagesFull - Report On Direct Tax Shish Mba Sams Ibm Varanasi IndiaShish Choudhary100% (1)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- BCA 5 Shish Mba Sams Ibm VaranasiDocument6 pagesBCA 5 Shish Mba Sams Ibm VaranasiShish ChoudharyNo ratings yet
- Cs Shish Mba Sams Ibm Varanasi & DivyanshDocument36 pagesCs Shish Mba Sams Ibm Varanasi & DivyanshShish ChoudharyNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shish MBA SAMS IBM VARANASIDocument11 pagesShish MBA SAMS IBM VARANASIShish ChoudharyNo ratings yet
- Cmeep15 Shish Mba Sams Ibm Varanasi IndiaDocument15 pagesCmeep15 Shish Mba Sams Ibm Varanasi IndiaShish ChoudharyNo ratings yet
- Linear Programming Problems - FormulationDocument55 pagesLinear Programming Problems - FormulationJagannath Padhi100% (1)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Targeted Campaigns Shish Mba Sams Ibm Varanasi & DivyanshDocument9 pagesTargeted Campaigns Shish Mba Sams Ibm Varanasi & DivyanshShish ChoudharyNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Earning, Ratio Analysis, Frofit Staragy Shish Mba Sams Ibm Varanasi IndiaDocument11 pagesEarning, Ratio Analysis, Frofit Staragy Shish Mba Sams Ibm Varanasi IndiaShish ChoudharyNo ratings yet
- Abs12-Argumentation Shish Mba Sams Ibm VaranasiDocument5 pagesAbs12-Argumentation Shish Mba Sams Ibm VaranasiShish Choudhary100% (1)
- Full - Report On Direct Tax Shish Mba Sams Ibm Varanasi IndiaDocument95 pagesFull - Report On Direct Tax Shish Mba Sams Ibm Varanasi IndiaShish Choudhary100% (1)
- Shish MBA SAMS IBM VARANASIDocument11 pagesShish MBA SAMS IBM VARANASIShish ChoudharyNo ratings yet
- Companies in The Sensex Shish Mba Sams Ibm VaranasiDocument2 pagesCompanies in The Sensex Shish Mba Sams Ibm VaranasiShish ChoudharyNo ratings yet
- Indirect Taxes Versus Direct Taxes Shish Mba Sams Ibm Varanasi IndiaDocument1 pageIndirect Taxes Versus Direct Taxes Shish Mba Sams Ibm Varanasi IndiaShish ChoudharyNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Basics of Negotiation Shish Mba Sams Ibm Varanasi IndiaDocument28 pagesBasics of Negotiation Shish Mba Sams Ibm Varanasi IndiaShish ChoudharyNo ratings yet
- Ceo Shish Mba Sams Ibm VaranasiDocument2 pagesCeo Shish Mba Sams Ibm VaranasiShish ChoudharyNo ratings yet
- Lecture #5 - Overview Calibration Curves: BlankDocument7 pagesLecture #5 - Overview Calibration Curves: BlankKim Swee LimNo ratings yet
- Chapter-2: Finite Differences and InterpolationDocument29 pagesChapter-2: Finite Differences and InterpolationNishant GuptaNo ratings yet
- Incorporating Limited RationalityDocument17 pagesIncorporating Limited RationalityYago RamalhoNo ratings yet
- Tutorial 6 PDFDocument2 pagesTutorial 6 PDFAnimesh ChoudharyNo ratings yet
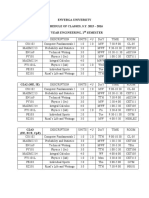
- Enverga University Schedule of Classes, S.Y. 2015 - 2016 2 Year Engineering, 1 Semester G2A1 (CE, GE)Document1 pageEnverga University Schedule of Classes, S.Y. 2015 - 2016 2 Year Engineering, 1 Semester G2A1 (CE, GE)Ian AtienzaNo ratings yet
- Mathematical and Computer Modelling: M. TurkyilmazogluDocument8 pagesMathematical and Computer Modelling: M. TurkyilmazogluNathan RedmondNo ratings yet
- Exercises On Math BioDocument4 pagesExercises On Math BioArij DaouNo ratings yet
- Numerical Methods For Engineers 7Document13 pagesNumerical Methods For Engineers 7najNo ratings yet
- Problem A RioDocument28 pagesProblem A RioGerman Cordova MontoyaNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Time Series Analysis AssignmentDocument2 pagesTime Series Analysis AssignmentMusa KhanNo ratings yet
- Christian Remling: N N N J J P 1/pDocument11 pagesChristian Remling: N N N J J P 1/pJuan David TorresNo ratings yet
- CCS350 KNOWLEDGE ENGINEERING - SyllabusDocument2 pagesCCS350 KNOWLEDGE ENGINEERING - SyllabusDHIVYA BHARATHI PNo ratings yet
- SequencesDocument7 pagesSequencesSilentSparrow98No ratings yet
- Topic 2 Model and Analysis in Decision Support Systems v2Document32 pagesTopic 2 Model and Analysis in Decision Support Systems v2tofuNo ratings yet
- An Analysis of Verbal and Visual Sign Found in Hotel Advertisements PosterDocument18 pagesAn Analysis of Verbal and Visual Sign Found in Hotel Advertisements PosterFerdi NandusNo ratings yet
- FCS Predictive ControlDocument2 pagesFCS Predictive Controlrakheep123No ratings yet
- Administration UnraveledDocument43 pagesAdministration UnraveledukigenNo ratings yet
- Knight and Fu (2000)Document23 pagesKnight and Fu (2000)imendezcNo ratings yet
- CAP August 2022 SolutionsDocument9 pagesCAP August 2022 SolutionsXuze ChenNo ratings yet
- Chapter 14 Chemical EquilibriumDocument29 pagesChapter 14 Chemical EquilibriumAhmad Irfaan HibatullahNo ratings yet
- HW4 Sol MATH0420 PDFDocument3 pagesHW4 Sol MATH0420 PDFBùi Quang MinhNo ratings yet
- DCF ValuationDocument2 pagesDCF ValuationRithik TiwariNo ratings yet
- Basic Aspects of DiscretizationDocument56 pagesBasic Aspects of DiscretizationSuta VijayaNo ratings yet
- Web Practice Exam 1Document11 pagesWeb Practice Exam 1Gnanaraj100% (1)
- 18.445 Introduction To Stochastic Processes: Lecture 5: Stationary TimesDocument13 pages18.445 Introduction To Stochastic Processes: Lecture 5: Stationary TimesAdityaPandhareNo ratings yet
- Algebra: Exercise 1ADocument10 pagesAlgebra: Exercise 1ANigel Itai ZembeNo ratings yet
- A Formula For PI (X) Applied To A Result of Koninck-IvicDocument2 pagesA Formula For PI (X) Applied To A Result of Koninck-IvicdamilovobregiaNo ratings yet
- 1.105 Solid Mechanics Laboratory: Least Squares Fit of Straight Line To DataDocument3 pages1.105 Solid Mechanics Laboratory: Least Squares Fit of Straight Line To Dataprieten20006936No ratings yet
- Discriminant Analysis: How Can You Answer These Questions?Document14 pagesDiscriminant Analysis: How Can You Answer These Questions?Priya BhatNo ratings yet
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)