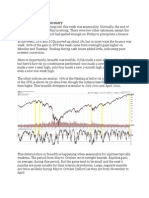
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- White Plains WombatsDocument3 pagesWhite Plains WombatsJack MolloyNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Sociology Research PaperDocument7 pagesSociology Research PaperJack MolloyNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- SP 2001 48 4 435Document22 pagesSP 2001 48 4 435Jack MolloyNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Interior and Exterior of Polygons Finished NotepageDocument8 pagesInterior and Exterior of Polygons Finished NotepageJack MolloyNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Sociology PresentationDocument16 pagesSociology PresentationJack MolloyNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- BlogDocument3 pagesBlogJack MolloyNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Weekly Market SummaryDocument12 pagesWeekly Market SummaryJack MolloyNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Population GrowthDocument3 pagesPopulation GrowthJack MolloyNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Heads of Accounting AssociationsDocument12 pagesHeads of Accounting AssociationsJack MolloyNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Chinese Direct Investment Is and Will Be A Positive EventDocument10 pagesChinese Direct Investment Is and Will Be A Positive EventJack MolloyNo ratings yet
- Population Growth Has A Huge Impact On A NationDocument1 pagePopulation Growth Has A Huge Impact On A NationJack MolloyNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Weekly Economic Calendar: Market Expectations 3/31-4/4Document7 pagesWeekly Economic Calendar: Market Expectations 3/31-4/4Jack MolloyNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Money BallDocument7 pagesMoney BallJack MolloyNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Capitalism A Love StoryDocument1 pageCapitalism A Love StoryJack MolloyNo ratings yet
- Types of Quality Management SystemsDocument10 pagesTypes of Quality Management Systemsselinasimpson0701No ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- H. P. Lovecraft: Trends in ScholarshipDocument18 pagesH. P. Lovecraft: Trends in ScholarshipfernandoNo ratings yet
- (1997) Process Capability Analysis For Non-Normal Relay Test DataDocument8 pages(1997) Process Capability Analysis For Non-Normal Relay Test DataNELSONHUGONo ratings yet
- MS - BDA Lec - Recommendation Systems IDocument31 pagesMS - BDA Lec - Recommendation Systems IJasura HimeNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- ESCL-QSP-005, Corrective Action ProcedureDocument6 pagesESCL-QSP-005, Corrective Action Procedureadiqualityconsult100% (1)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- A1603 WTDocument9 pagesA1603 WTnanichowsNo ratings yet
- (Ebook PDF) - Statistics. .Spss - TutorialDocument15 pages(Ebook PDF) - Statistics. .Spss - TutorialMASAIER4394% (17)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Exam 1Document61 pagesExam 1Sara M. DheyabNo ratings yet
- Assignment Gravity and MotionDocument23 pagesAssignment Gravity and MotionRahim HaininNo ratings yet
- Art Funding EssayDocument2 pagesArt Funding EssayDương NguyễnNo ratings yet
- Mevlana Jelaluddin RumiDocument3 pagesMevlana Jelaluddin RumiMohammed Abdul Hafeez, B.Com., Hyderabad, IndiaNo ratings yet
- Astro PhotoDocument12 pagesAstro PhotoPavelNo ratings yet
- JD of HSE LO MD Abdullah Al ZamanDocument2 pagesJD of HSE LO MD Abdullah Al ZamanRAQIB 2025No ratings yet
- Update RS232 TXNR905 E080313Document3 pagesUpdate RS232 TXNR905 E080313varimasrNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Low-Permeability Concrete Water-To-Cement Ratio Optimization For Designing Drinking Water ReservoirsDocument5 pagesLow-Permeability Concrete Water-To-Cement Ratio Optimization For Designing Drinking Water ReservoirsInternational Journal of Innovations in Engineering and ScienceNo ratings yet
- Dukungan Suami Terhadap Pemberian Asi Eksklusif PaDocument11 pagesDukungan Suami Terhadap Pemberian Asi Eksklusif PayolandaNo ratings yet
- Mini Fellowship Program OutlineDocument4 pagesMini Fellowship Program OutlineVijayraj GohilNo ratings yet
- IBPS IT Officer Model Questions Computer MIcroprocessor and Assembly Language MCQ Question BankDocument146 pagesIBPS IT Officer Model Questions Computer MIcroprocessor and Assembly Language MCQ Question BankNaveen KrishnanNo ratings yet
- A Survey On Existing Food Recommendation SystemsDocument3 pagesA Survey On Existing Food Recommendation SystemsIJSTENo ratings yet
- BhishmaDocument6 pagesBhishmaHarsh SoniNo ratings yet
- ERM Introduction UnpadDocument30 pagesERM Introduction UnpadMuhammadRivaresNo ratings yet
- CriminologyDocument2 pagesCriminologydeliriummagic100% (1)
- Ais For PROTONDocument18 pagesAis For PROTONAfaf RadziNo ratings yet
- Ward Wise Officers ListDocument8 pagesWard Wise Officers ListprabsssNo ratings yet
- Virtuoso TutorialDocument14 pagesVirtuoso TutorialSrikanth Govindarajan0% (1)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Soil MechanicsDocument38 pagesSoil MechanicsAnsh Kushwaha50% (2)
- Script PDFDocument14 pagesScript PDFSachin SaraswatiNo ratings yet
- Ims Kuk SullybusDocument84 pagesIms Kuk SullybusJoginder ChhikaraNo ratings yet
- PSD - Trilok - Kalyan Medicals - June 29, 17 - Business Proposal Ver 1Document7 pagesPSD - Trilok - Kalyan Medicals - June 29, 17 - Business Proposal Ver 1papuNo ratings yet
- Block 7Document15 pagesBlock 7api-3703652No ratings yet