You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Circuit Protective Devices: Learner Work BookDocument41 pagesCircuit Protective Devices: Learner Work BookChanel Maglinao80% (5)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Ugc Model Curriculum Statistics: Submitted To The University Grants Commission in April 2001Document101 pagesUgc Model Curriculum Statistics: Submitted To The University Grants Commission in April 2001Alok ThakkarNo ratings yet
- IncarnationDocument3 pagesIncarnationViviana PueblaNo ratings yet
- Bodybuilder Guidelines: Update: 2011-22Document438 pagesBodybuilder Guidelines: Update: 2011-22thkimzone73100% (12)
- Hot and Cold ApplicDocument33 pagesHot and Cold Appliccamille_12_15100% (1)
- 00.concrete Mix Design-RailwayDocument38 pages00.concrete Mix Design-RailwaySoundar PachiappanNo ratings yet
- 3 Perform Industry CalculationsDocument90 pages3 Perform Industry CalculationsRobinson ConcordiaNo ratings yet
- Chem Cheat Sheet MasterDocument6 pagesChem Cheat Sheet MasteradamhamelehNo ratings yet
- A Report On Traffic Volume StudyDocument33 pagesA Report On Traffic Volume StudyManoj Durairaj100% (1)
- Always Branding. Always On.: Latest News in Depth Papers Events Brandcameo Directory Careers Branding GlossaryDocument8 pagesAlways Branding. Always On.: Latest News in Depth Papers Events Brandcameo Directory Careers Branding GlossarysudipitmNo ratings yet
- Astm A394 2008 PDFDocument6 pagesAstm A394 2008 PDFJavier Ricardo Romero BohorquezNo ratings yet
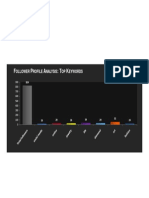
- F P A: T K: Ollower Rofile Nalysis OP EywordsDocument8 pagesF P A: T K: Ollower Rofile Nalysis OP EywordssudipitmNo ratings yet
- IMC Group3 AirtelDocument13 pagesIMC Group3 AirtelsudipitmNo ratings yet
- GEOMATORYDocument16 pagesGEOMATORYParasharAmanNo ratings yet
- The Green Mom Eco CosmDocument16 pagesThe Green Mom Eco CosmsudipitmNo ratings yet
- Keyword Position Previous Position Status UrlDocument1 pageKeyword Position Previous Position Status UrlsudipitmNo ratings yet
- Language Attitudes and Code-Switching BehaviourDocument408 pagesLanguage Attitudes and Code-Switching Behavioursudipitm100% (1)
- Siloed Organization With Many Outliers Structured Organization Cohesive and Integrated Organization Happy Organization With Top Notch PerformanceDocument1 pageSiloed Organization With Many Outliers Structured Organization Cohesive and Integrated Organization Happy Organization With Top Notch PerformancesudipitmNo ratings yet
- Odp-090r16bv 17KV PDFDocument1 pageOdp-090r16bv 17KV PDFAlberto LinaresNo ratings yet
- Measures of Central Tendency: Mean Median ModeDocument20 pagesMeasures of Central Tendency: Mean Median ModeRia BarisoNo ratings yet
- ELEMAGDocument1 pageELEMAGJasper BantulaNo ratings yet
- Case StudyDocument4 pagesCase Studyadil rangoonNo ratings yet
- Ee-502 Unit - IDocument2 pagesEe-502 Unit - IVARAPRASADNo ratings yet
- Experimental Techniques For Low Temperature Measurements PDFDocument2 pagesExperimental Techniques For Low Temperature Measurements PDFVanessaNo ratings yet
- Assignment 1Document2 pagesAssignment 1Alif Bukhari Imran NaimNo ratings yet
- Introduction To PIC and Embedded SystemsDocument12 pagesIntroduction To PIC and Embedded Systemsheno ahNo ratings yet
- Calculus 1: CONTINUITYDocument56 pagesCalculus 1: CONTINUITYMa Lorraine PerezNo ratings yet
- Magnetophoresis and Electromagnetophoresis of Microparticles in LiquidsDocument7 pagesMagnetophoresis and Electromagnetophoresis of Microparticles in Liquids3issazakaNo ratings yet
- Ims PrecalDocument10 pagesIms PrecalRhea GlipoNo ratings yet
- HydrometerDocument13 pagesHydrometerShubhrajit MaitraNo ratings yet
- AWK - WikipediaDocument1 pageAWK - WikipediachassisdNo ratings yet
- High Pressure Jet Grouting in TunnelsDocument8 pagesHigh Pressure Jet Grouting in TunnelsSandeep AggarwalNo ratings yet
- 5.3.2 To Sketch Graphs of Trigonometric Functions (Part 2) - SPM Additional MathematicsDocument3 pages5.3.2 To Sketch Graphs of Trigonometric Functions (Part 2) - SPM Additional MathematicsLuke SuouNo ratings yet
- Sci - Short Circuit IsolatorDocument2 pagesSci - Short Circuit IsolatorVictor MoraesNo ratings yet
- 6100 SQ Lcms Data SheetDocument4 pages6100 SQ Lcms Data Sheet王皓No ratings yet
- Solution of Linear System Theory and Design 3ed For Chi Tsong ChenDocument106 pagesSolution of Linear System Theory and Design 3ed For Chi Tsong ChensepehrNo ratings yet
- Backup Olt CodigoDocument5 pagesBackup Olt CodigoCarlos GomezNo ratings yet
- 1 s2.0 0304386X9190055Q MainDocument32 pages1 s2.0 0304386X9190055Q MainJordan Ulloa Bello100% (1)