You might also like
- 2019 2020 Practical Research 2Document87 pages2019 2020 Practical Research 2Jeffrey Azuela Jr.90% (10)
- Posing GuideDocument16 pagesPosing GuideK FinkNo ratings yet
- Nikon D7000 User's Manual (English) PrintableDocument348 pagesNikon D7000 User's Manual (English) PrintablegoldfiresNo ratings yet
- Eurocode Conference 2023 Seters Van Eurocode 7Document33 pagesEurocode Conference 2023 Seters Van Eurocode 7Rodolfo BlanchiettiNo ratings yet
- Air Force Handbook 2007Document326 pagesAir Force Handbook 2007joe_hielscher100% (1)
- Navistar Integrated Supplier Quality RequirementsDocument29 pagesNavistar Integrated Supplier Quality RequirementsK FinkNo ratings yet
- Quantitative ResearchDocument98 pagesQuantitative ResearchPaula BechaydaNo ratings yet
- IPHPDocument4 pagesIPHPAliah CasilangNo ratings yet
- Descriptive and Inferential StatisticsDocument31 pagesDescriptive and Inferential Statisticsabusroor2008100% (1)
- Constructs and Variables in ResearchDocument7 pagesConstructs and Variables in ResearchSora dullahanNo ratings yet
- Pursuit of Performance Findings From The 2014 Miller Heiman Sales Best Practices StudyDocument37 pagesPursuit of Performance Findings From The 2014 Miller Heiman Sales Best Practices StudyLoredanaNo ratings yet
- Variables Scales of MeasurementDocument25 pagesVariables Scales of MeasurementPrateek Sharma100% (1)
- Three Revolutionary Architects - Boullee, Ledoux, and Lequeu PDFDocument135 pagesThree Revolutionary Architects - Boullee, Ledoux, and Lequeu PDFTran LeNo ratings yet
- Practical Research 2.9Document22 pagesPractical Research 2.9Michael GabertanNo ratings yet
- Dynamic Shear Modulus SoilDocument14 pagesDynamic Shear Modulus SoilMohamed A. El-BadawiNo ratings yet
- Types of VariablesDocument31 pagesTypes of Variablesimmunedarksempai0No ratings yet
- FRP Design Guide 06Document28 pagesFRP Design Guide 06K Fink100% (5)
- Statistics For Research With A Guide To SpssDocument50 pagesStatistics For Research With A Guide To SpssEr. Rajendra AcharayaNo ratings yet
- 2006 PPAP Manual 4th Edition ManualDocument51 pages2006 PPAP Manual 4th Edition ManualK FinkNo ratings yet
- C Yyyyyy Y Y Yy YyDocument7 pagesC Yyyyyy Y Y Yy YyPRINTDESK by DanNo ratings yet
- Lecture 2: Types of Variables: 2typesofvariables PDFDocument7 pagesLecture 2: Types of Variables: 2typesofvariables PDFMateo BallestaNo ratings yet
- In Order To Use StatisticsDocument8 pagesIn Order To Use StatisticsGIL BARRY ORDONEZNo ratings yet
- Variables and Research DesignDocument30 pagesVariables and Research DesignfarahisNo ratings yet
- Is Workshop Note - 1Document7 pagesIs Workshop Note - 1Hizbe EthiopiaNo ratings yet
- IntroductionDocument27 pagesIntroductionGerard SantosNo ratings yet
- Variables We Wish To Study. A Variable Is Something That Can Change or Vary. For Example, A Variable ofDocument6 pagesVariables We Wish To Study. A Variable Is Something That Can Change or Vary. For Example, A Variable ofLisa FerraroNo ratings yet
- What Are Examples of Variables in ResearchDocument13 pagesWhat Are Examples of Variables in ResearchJacques Andre Collantes BeaNo ratings yet
- Research AssignmentDocument14 pagesResearch AssignmentRed Christian PalustreNo ratings yet
- Variable TypesDocument2 pagesVariable Typesmarmar418No ratings yet
- Hi in This Video I Will Help You ChooseDocument7 pagesHi in This Video I Will Help You ChooseMixx MineNo ratings yet
- Presentation 4Document31 pagesPresentation 4Cristine Galanga FajanilanNo ratings yet
- Acfrogc9niimqchav N077pxprcedg1gy6a 0wu2obp D 3jomqfmffapkvcupjw8tpafw8v4qcn2s3tlpqs3acndbhxjz5hv8aowz2smhryjgu6z8alty2vfbobnb0ztvvxsljvdzkz0e2fw9trDocument75 pagesAcfrogc9niimqchav N077pxprcedg1gy6a 0wu2obp D 3jomqfmffapkvcupjw8tpafw8v4qcn2s3tlpqs3acndbhxjz5hv8aowz2smhryjgu6z8alty2vfbobnb0ztvvxsljvdzkz0e2fw9trNoorNo ratings yet
- 8614 Assignment No 1Document16 pages8614 Assignment No 1Noor Ul AinNo ratings yet
- Statistics-: Data Is A Collection of FactsDocument3 pagesStatistics-: Data Is A Collection of FactsLonnieAllenVirtudesNo ratings yet
- BA 302: Chapter-1 Instructions: Introduction & Definitions by Dr. Kishor Guru-GharanaDocument5 pagesBA 302: Chapter-1 Instructions: Introduction & Definitions by Dr. Kishor Guru-GharanaLou RawlsNo ratings yet
- Variables and Their Measurement: Region Over Which The Population SpreadsDocument14 pagesVariables and Their Measurement: Region Over Which The Population SpreadsMuhammad Furqan Aslam AwanNo ratings yet
- BRM Unit 1 Short 1 AnsDocument10 pagesBRM Unit 1 Short 1 Ansvikaswadikar1No ratings yet
- Different Types of Data - BioStatisticsDocument9 pagesDifferent Types of Data - BioStatisticsSophia MabansagNo ratings yet
- Quantitative Research Design and MethodsDocument35 pagesQuantitative Research Design and MethodsDonn MoralesNo ratings yet
- Unit Ii Lesson 4 Concepts and Constructs Introduction To Concepts and Constructs Variables Nature and Levels of MeasurementDocument10 pagesUnit Ii Lesson 4 Concepts and Constructs Introduction To Concepts and Constructs Variables Nature and Levels of MeasurementsamNo ratings yet
- Q.1 Describe 'Levels of Measurement' by Giving Real Life ExamplesDocument11 pagesQ.1 Describe 'Levels of Measurement' by Giving Real Life ExamplesGHULAM RABANINo ratings yet
- Econ 309 Lect 1 BasicsDocument8 pagesEcon 309 Lect 1 BasicsAhmed Kadem ArabNo ratings yet
- Lab - Unit 1 Lesson 1Document12 pagesLab - Unit 1 Lesson 1jmaestradoNo ratings yet
- محاضرة اولى احصاءDocument16 pagesمحاضرة اولى احصاءniiishaan97No ratings yet
- Introduction To Biostatistics: DR Asim WarisDocument37 pagesIntroduction To Biostatistics: DR Asim WarisNaveed Malik0% (1)
- StatisticsDocument142 pagesStatisticsDr.B.THAYUMANAVARNo ratings yet
- Types of VariableDocument9 pagesTypes of VariableGiezel GeurreroNo ratings yet
- Descriptive StatsDocument16 pagesDescriptive StatsChris DaimlerNo ratings yet
- Statistics 1Document3 pagesStatistics 1kuashask2No ratings yet
- Conceptualization and Operationalization PDFDocument7 pagesConceptualization and Operationalization PDFTherese Sofia EnriquezNo ratings yet
- "For I Know The Plans I Have For You, Declares The LORD, Plans For Welfare and Not For Evil, To Give You A Future and A Hope." - Jeremiah 29:11Document6 pages"For I Know The Plans I Have For You, Declares The LORD, Plans For Welfare and Not For Evil, To Give You A Future and A Hope." - Jeremiah 29:11Carmina CarganillaNo ratings yet
- 8614 Solved Assignment 1Document10 pages8614 Solved Assignment 1Haroon Karim BalochNo ratings yet
- Ho Coms 120 Research MethodologyDocument6 pagesHo Coms 120 Research MethodologyBryan RonoNo ratings yet
- 1st and 2nd WorkshopDocument72 pages1st and 2nd WorkshopBoban KacanskiNo ratings yet
- Elements of ResearchDocument9 pagesElements of ResearchmishockNo ratings yet
- Lesson 1: Introduction To Statistics ObjectivesDocument12 pagesLesson 1: Introduction To Statistics ObjectivesTracy Blair Napa-egNo ratings yet
- Intro To Measurement and StatisticsDocument6 pagesIntro To Measurement and Statisticsjeff omangaNo ratings yet
- Stat 1Document6 pagesStat 1Katrina Marie CatacutanNo ratings yet
- Quantitative Research Design and MethodsDocument35 pagesQuantitative Research Design and MethodskundagolNo ratings yet
- Lecture Notes Quanti 1Document105 pagesLecture Notes Quanti 1Godfred AbleduNo ratings yet
- Type of VariableDocument5 pagesType of Variablebayan salahNo ratings yet
- 1-1a: Types of Studies: FoundationsDocument40 pages1-1a: Types of Studies: FoundationsSarah YoussefNo ratings yet
- SPSS Session 1 Descriptive Statistics and UnivariateDocument8 pagesSPSS Session 1 Descriptive Statistics and UnivariateMuhammad GulfamNo ratings yet
- SASADocument22 pagesSASAJelly Mea VillenaNo ratings yet
- Statistics and Probability Handouts - Basic Terms in StatisticsDocument4 pagesStatistics and Probability Handouts - Basic Terms in StatisticsReygie FabrigaNo ratings yet
- Learning Unit 2Document11 pagesLearning Unit 2BelindaNiemandNo ratings yet
- WodakDocument18 pagesWodakDanusia JNo ratings yet
- 6.5 Complexities in Measurement Learning ObjectivesDocument10 pages6.5 Complexities in Measurement Learning ObjectivesRijurahul Agarwal SinghNo ratings yet
- Lecture 2Document27 pagesLecture 2Josfique ArefinNo ratings yet
- Lecture 6Document20 pagesLecture 6Areeba AfridiNo ratings yet
- Data-Analysis-in-the-Psychological-Sciences-A-Practical-Applied-Multimedia-Approach-1673911880 - Leyre CastroDocument138 pagesData-Analysis-in-the-Psychological-Sciences-A-Practical-Applied-Multimedia-Approach-1673911880 - Leyre Castroras82362No ratings yet
- 2022 Catalog 72Document58 pages2022 Catalog 72K FinkNo ratings yet
- D800 enDocument472 pagesD800 enHP_NerdNo ratings yet
- Pur 2050 Po Edi862 Training GuideDocument39 pagesPur 2050 Po Edi862 Training GuideK FinkNo ratings yet
- Planking PrimerDocument8 pagesPlanking PrimermouradNo ratings yet
- User's Manual: Digital CameraDocument0 pagesUser's Manual: Digital CameraMaicol Nicolas Peña FariasNo ratings yet
- Us Navy Color SchemesDocument3 pagesUs Navy Color SchemesK FinkNo ratings yet
- Nikon D80 Cameral ManualDocument162 pagesNikon D80 Cameral ManualReza HidayatNo ratings yet
- How To Air BrushDocument0 pagesHow To Air BrushHarold ClementsNo ratings yet
- D800 enDocument472 pagesD800 enHP_NerdNo ratings yet
- Bob R Corvette TalkDocument86 pagesBob R Corvette TalkK FinkNo ratings yet
- MFG CSC IA Ver3Document1 pageMFG CSC IA Ver3K FinkNo ratings yet
- Asset Forfeiture and Police PrioritiesDocument18 pagesAsset Forfeiture and Police PrioritiesK FinkNo ratings yet
- BreakfastBriefingPresentation ThePostRecessionMarketLandscapeDocument9 pagesBreakfastBriefingPresentation ThePostRecessionMarketLandscapeK FinkNo ratings yet
- 9 Compelling Reasons To Specify CompositesDocument1 page9 Compelling Reasons To Specify CompositesK FinkNo ratings yet
- MFG CompAge Fall FinalDocument4 pagesMFG CompAge Fall FinalK FinkNo ratings yet
- Wind Energy Services Operations ManagerDocument1 pageWind Energy Services Operations ManagerK FinkNo ratings yet
- Industrial Facilties Question A Ire 2010Document5 pagesIndustrial Facilties Question A Ire 2010K FinkNo ratings yet
- Composite Age Summer 2009 FinalDocument4 pagesComposite Age Summer 2009 FinalK FinkNo ratings yet
- MFG Tray Presentation Mar 2010Document16 pagesMFG Tray Presentation Mar 2010K FinkNo ratings yet
- Molded Fiber Glass Construction Products (MFG-CP) Enlisted To Provide FRP Pile JacketsDocument3 pagesMolded Fiber Glass Construction Products (MFG-CP) Enlisted To Provide FRP Pile JacketsK FinkNo ratings yet
- Project Choice BrochureDocument12 pagesProject Choice BrochureK FinkNo ratings yet
- 5S For TeammatesDocument70 pages5S For TeammatesK FinkNo ratings yet
- Mass Reduction With Value-Engineered Composites: ProcessDocument4 pagesMass Reduction With Value-Engineered Composites: ProcessK FinkNo ratings yet
- Stevenson Chapter 13Document52 pagesStevenson Chapter 13TanimNo ratings yet
- IFN 554 Week 3 Tutorial v.1Document19 pagesIFN 554 Week 3 Tutorial v.1kitkataus0711No ratings yet
- Lecture 11 - Performance AppraisalsDocument23 pagesLecture 11 - Performance AppraisalsCard CardNo ratings yet
- Effect of Heater Geometry On The High Temperature Distribution On A MEMS Micro-HotplateDocument6 pagesEffect of Heater Geometry On The High Temperature Distribution On A MEMS Micro-HotplateJorge GuerreroNo ratings yet
- DLPFBSDocument1 pageDLPFBSEdnaMarquezMoralesNo ratings yet
- FS-C8025MFP Release NotesDocument22 pagesFS-C8025MFP Release NotesFirmware SM-SHNo ratings yet
- Demonstration of Preprocessing On Dataset Student - Arff Aim: This Experiment Illustrates Some of The Basic Data Preprocessing Operations That Can BeDocument4 pagesDemonstration of Preprocessing On Dataset Student - Arff Aim: This Experiment Illustrates Some of The Basic Data Preprocessing Operations That Can BePavan Sankar KNo ratings yet
- Jarir IT Flyer Qatar1Document4 pagesJarir IT Flyer Qatar1sebincherianNo ratings yet
- Barack ObamaDocument3 pagesBarack ObamaVijay KumarNo ratings yet
- Catálogo StaubliDocument8 pagesCatálogo StaubliJackson BravosNo ratings yet
- Tensile Strength of Ferro Cement With Respect To Specific SurfaceDocument3 pagesTensile Strength of Ferro Cement With Respect To Specific SurfaceheminNo ratings yet
- 37270a QUERCUS GBDocument6 pages37270a QUERCUS GBMocanu Romeo-CristianNo ratings yet
- Astn/Ason and Gmpls Overview and Comparison: By, Kishore Kasi Udayashankar Kaveriappa Muddiyada KDocument44 pagesAstn/Ason and Gmpls Overview and Comparison: By, Kishore Kasi Udayashankar Kaveriappa Muddiyada Ksrotenstein3114No ratings yet
- Jazz PrepaidDocument4 pagesJazz PrepaidHoney BunnyNo ratings yet
- AE HM6L-72 Series 430W-450W: Half Large CellDocument2 pagesAE HM6L-72 Series 430W-450W: Half Large CellTaso GegiaNo ratings yet
- Backward Forward PropogationDocument19 pagesBackward Forward PropogationConrad WaluddeNo ratings yet
- Contoh Label Sensus 2022Document313 pagesContoh Label Sensus 2022Ajenk SablackNo ratings yet
- IDL6543 ModuleRubricDocument2 pagesIDL6543 ModuleRubricSteiner MarisNo ratings yet
- Bohler Dcms T-MCDocument1 pageBohler Dcms T-MCFlaviu-Andrei AstalisNo ratings yet
- Apps Android StudioDocument12 pagesApps Android StudioDaniel AlcocerNo ratings yet
- 3-Waves of RoboticsDocument2 pages3-Waves of RoboticsEbrahim Abd El HadyNo ratings yet
- DICKSON KT800/802/803/804/856: Getting StartedDocument6 pagesDICKSON KT800/802/803/804/856: Getting StartedkmpoulosNo ratings yet
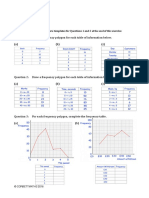
- Frequency Polygons pdf3Document7 pagesFrequency Polygons pdf3Nevine El shendidyNo ratings yet
- Operations and Service ManualDocument311 pagesOperations and Service ManualELARD GUILLENNo ratings yet