You might also like
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Jens Zemke - Abstract Perturbed Krylov MethodsDocument29 pagesJens Zemke - Abstract Perturbed Krylov MethodsJulio Cesar Barraza BernaolaNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Tutoriu MupadDocument487 pagesTutoriu MupadJulio Cesar Barraza BernaolaNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Algorithms For The Matrix Exponential and Frechet DerivativeDocument116 pagesAlgorithms For The Matrix Exponential and Frechet DerivativeJulio Cesar Barraza BernaolaNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Matrix Analysis For Scientists and Engineers by Alan J LaubDocument172 pagesMatrix Analysis For Scientists and Engineers by Alan J LaubJulio Cesar Barraza Bernaola91% (11)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Firewall and Proxy ServersDocument26 pagesFirewall and Proxy ServersrajeevadeeviNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Scrum PosterDocument2 pagesScrum PosterEdu Oliver100% (2)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Integration Guide (Wordpress)Document6 pagesIntegration Guide (Wordpress)Hasan Elahi0% (3)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Technical Aptitude QuestionsDocument151 pagesTechnical Aptitude QuestionsGodwin SvceNo ratings yet
- Tutorial - Arduino and The TI ADS1110 16-Bit ADCDocument5 pagesTutorial - Arduino and The TI ADS1110 16-Bit ADCantoninoxxxNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Clustering and Search Techniques in Information Retrieval SystemsDocument39 pagesClustering and Search Techniques in Information Retrieval SystemsKarumuri Sri Rama Murthy67% (3)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- fV-RPLS-Operator ManualDocument28 pagesfV-RPLS-Operator ManualВадим НайденовNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- IRS Publication 1075 - Effective January 1, 2014Document173 pagesIRS Publication 1075 - Effective January 1, 2014Michael BarbereNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Sa Lesson Plan Feb2018Document3 pagesSa Lesson Plan Feb2018Vijayaraghavan AravamuthanNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Kali Linux For Beginners HackersDocument26 pagesKali Linux For Beginners Hackersnihal100% (1)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Freeduino Serial ManualDocument3 pagesFreeduino Serial ManualSyed HasanNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- PT2 Sample Paper-Iii Periodic Test - 2 Class - Xi Informatics PracticesDocument2 pagesPT2 Sample Paper-Iii Periodic Test - 2 Class - Xi Informatics Practicesutkarsh0% (1)
- Comsats University Islamabad: Department of Computer ScienceDocument18 pagesComsats University Islamabad: Department of Computer ScienceJind Wadda JDNo ratings yet
- Welcome To The Model Data Centre The 6sigmadc Software SuiteDocument18 pagesWelcome To The Model Data Centre The 6sigmadc Software SuitedexiNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Try To Avoid Writing Custom Code in SAP: Technology Risk ReviewDocument2 pagesTry To Avoid Writing Custom Code in SAP: Technology Risk ReviewBhattahcarjee RupakNo ratings yet
- LAS File Processing Using LASTOOLSDocument12 pagesLAS File Processing Using LASTOOLSNNMSANo ratings yet
- Evidian Identity & Access Manager 9: ICT Security Days October 2014Document26 pagesEvidian Identity & Access Manager 9: ICT Security Days October 2014Grouwels DanielNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Report On Mini ProjectDocument51 pagesReport On Mini ProjectAjay JachakNo ratings yet
- NVML SDK: Python BindingsDocument28 pagesNVML SDK: Python BindingsMarius BuNo ratings yet
- MatLab Guide WikibooksDocument86 pagesMatLab Guide Wikibooksmanymty64No ratings yet
- 1-Foundations (EID REHMAN)Document73 pages1-Foundations (EID REHMAN)Farhana Aijaz100% (1)
- Lab Manual 2Document4 pagesLab Manual 2Falaq NazNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Deduplication SchoolDocument61 pagesDeduplication SchoolharshvyasNo ratings yet
- FPGA Based Modified Karatsuba MultiplierDocument6 pagesFPGA Based Modified Karatsuba MultiplierMrudula SingamNo ratings yet
- Category BDocument31 pagesCategory BsdasdNo ratings yet
- Anthropomorphic Robotic Arms - Practice and SimulationDocument5 pagesAnthropomorphic Robotic Arms - Practice and SimulationbugraerginNo ratings yet
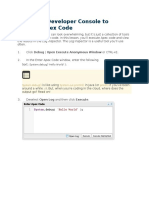
- Using The Developer Console To Execute Apex CodeDocument5 pagesUsing The Developer Console To Execute Apex Codeksr131No ratings yet
- Infrastructure DocumentationDocument16 pagesInfrastructure DocumentationRamone ScratchleyNo ratings yet
- SQL InjectionDocument9 pagesSQL InjectionSanket SahuNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)