You might also like
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Fakespotter: A Simple Yet Robust Baseline For Spotting Ai-Synthesized Fake FacesDocument8 pagesFakespotter: A Simple Yet Robust Baseline For Spotting Ai-Synthesized Fake FacesAmol SinhaNo ratings yet
- Network Models: Multiple ChoiceDocument12 pagesNetwork Models: Multiple ChoiceSarah Shehata100% (1)
- Re PaperDocument1 pageRe PaperLearn SamadeshNo ratings yet
- Proportional Control For Set Point Change (Servo Problem) Proportional Control For Load Change (Regulatory Problem)Document19 pagesProportional Control For Set Point Change (Servo Problem) Proportional Control For Load Change (Regulatory Problem)Imran UnarNo ratings yet
- Syl MSC Physics 2212Document53 pagesSyl MSC Physics 2212Aaron DmcNo ratings yet
- Sri Bestari International School: Christie Kong Pui Ching Year 7 Einstein 4 1:25pm - 2:05pmDocument3 pagesSri Bestari International School: Christie Kong Pui Ching Year 7 Einstein 4 1:25pm - 2:05pmChristie Kong Pui ChingNo ratings yet
- Content-Based Image Retrieval Using Feature Extraction and K-Means ClusteringDocument12 pagesContent-Based Image Retrieval Using Feature Extraction and K-Means ClusteringIJIRSTNo ratings yet
- Struktur Data: By: Sri Rezeki Candra NursariDocument34 pagesStruktur Data: By: Sri Rezeki Candra NursaridukuhwaruNo ratings yet
- Example 11 Chapter 1 Indices Problem SolvingDocument2 pagesExample 11 Chapter 1 Indices Problem SolvingSagir Musa SaniNo ratings yet
- Orientation EstimationDocument4 pagesOrientation Estimationmollah111No ratings yet
- Hashing: An Ideal Hash TableDocument11 pagesHashing: An Ideal Hash TableMehwish MehmoodNo ratings yet
- S 4 - Cryptography and Encryption AlgorithmsDocument28 pagesS 4 - Cryptography and Encryption AlgorithmsPPNo ratings yet
- TokkeeDocument78 pagesTokkeehundasa chalaNo ratings yet
- A Combination of Mathematics, Statistics and Machine Learning To Detect FraudDocument4 pagesA Combination of Mathematics, Statistics and Machine Learning To Detect FraudMd. KowsherNo ratings yet
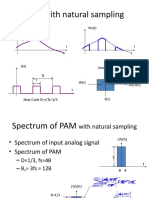
- PAM With Natural SamplingDocument66 pagesPAM With Natural SamplingnctgayarangaNo ratings yet
- Toc ExperimentDocument14 pagesToc ExperimentmohitNo ratings yet
- Fuzzytech Crane SimulationDocument27 pagesFuzzytech Crane SimulationMomi Tza100% (1)
- Weatherwax - Conte - Solution - Manual Capitulo 2 y 3Document59 pagesWeatherwax - Conte - Solution - Manual Capitulo 2 y 3Jorge EstebanNo ratings yet
- BCS 054 PDFDocument7 pagesBCS 054 PDFyatharthNo ratings yet
- Cryptography and Network SecurityDocument15 pagesCryptography and Network SecurityrajeevrajkumarNo ratings yet
- Principles - of .Quantum - Artificial.Intelligence PDFDocument277 pagesPrinciples - of .Quantum - Artificial.Intelligence PDFPrashant Gupta100% (4)
- TR Bangkitan Perjalanan - Muhammad Fajar AdibaDocument3 pagesTR Bangkitan Perjalanan - Muhammad Fajar AdibaYoel PaskahitaNo ratings yet
- Topic Modeling With BERT. - Towards Data ScienceDocument9 pagesTopic Modeling With BERT. - Towards Data ScienceRubi ZimmermanNo ratings yet
- Finals Assessment 3Document3 pagesFinals Assessment 3ShieNo ratings yet
- Quantum ComputingDocument25 pagesQuantum ComputingDheeRaj BhatNo ratings yet
- BluSTL Controller Synthesis From Signal Temporal Logic SpecificationsDocument9 pagesBluSTL Controller Synthesis From Signal Temporal Logic SpecificationsRaghavendra M BhatNo ratings yet
- ECON 357: Lecture 7: The Distribution of RM SizesDocument23 pagesECON 357: Lecture 7: The Distribution of RM SizesHector Perez SaizNo ratings yet
- Article 1Document4 pagesArticle 1Tashu SardaNo ratings yet
- Chapter 2 Project Management Section 2.1 Critical Path Method (CPM) Using Activity On Arrow Example 2.1 Black Eyed Peas (I)Document5 pagesChapter 2 Project Management Section 2.1 Critical Path Method (CPM) Using Activity On Arrow Example 2.1 Black Eyed Peas (I)Michael BunyiNo ratings yet
- MCD4710 Week3 Sample Test SolDocument8 pagesMCD4710 Week3 Sample Test SolVionnie TanNo ratings yet