You might also like
- PassportApplicationForm Main English V1.0Document2 pagesPassportApplicationForm Main English V1.0Triloki KumarNo ratings yet
- Design For Test by Alfred L CrouchDocument117 pagesDesign For Test by Alfred L CrouchSrikanth100% (4)
- Section 2Document142 pagesSection 2Abdul Ghani KhanNo ratings yet
- 28nm Silicon and Design Enablement The Foundry and EDA Vendor PerspectiveDocument31 pages28nm Silicon and Design Enablement The Foundry and EDA Vendor Perspectiveswathikomati7870No ratings yet
- Skew DesignDocument29 pagesSkew DesignAshok KoyyalamudiNo ratings yet
- 300english PDFDocument19 pages300english PDFFaizullahMagsi100% (1)
- AMBA BusDocument38 pagesAMBA BusAshok KoyyalamudiNo ratings yet
- 2012 Telugu CalendarDocument12 pages2012 Telugu CalendarVinay AnandNo ratings yet
- PVT CornersDocument7 pagesPVT CornersAshok KoyyalamudiNo ratings yet
- Booth Multiplication PDFDocument3 pagesBooth Multiplication PDFkbmn2No ratings yet
- Booth Multiplication PDFDocument3 pagesBooth Multiplication PDFkbmn2No ratings yet
- Latch-Based Performance Optimization For Field-Programmable Gate ArraysDocument14 pagesLatch-Based Performance Optimization For Field-Programmable Gate ArraysAshok KoyyalamudiNo ratings yet
- Vinayaka Vratha Kalpam PDFDocument24 pagesVinayaka Vratha Kalpam PDFmental12345No ratings yet
- Gate 2012 BrochureDocument16 pagesGate 2012 BrochureShantanu ChakrabortyNo ratings yet
- Mipi Dsi 4 LaneDocument12 pagesMipi Dsi 4 LaneAshok KoyyalamudiNo ratings yet
- Clock DividersDocument19 pagesClock Dividersapi-376268992% (12)
- Amazing Photos - No 1Document10 pagesAmazing Photos - No 1Ashok KoyyalamudiNo ratings yet
- RealChipDesign PrefaceDocument28 pagesRealChipDesign PrefaceAshok Koyyalamudi100% (1)
- STA IntelDocument81 pagesSTA IntelJay PadaliyaNo ratings yet
- Lecture AllDocument142 pagesLecture AllsawerrNo ratings yet
- SyntutDocument55 pagesSyntutrambooksreddyNo ratings yet
- DD Vahid ch3Document58 pagesDD Vahid ch3Ashok KoyyalamudiNo ratings yet
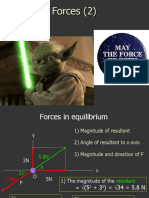
- Forces - LESSON 2 - ResolvingDocument10 pagesForces - LESSON 2 - ResolvingAshok KoyyalamudiNo ratings yet
- Capacitors 6Document68 pagesCapacitors 6Ashok KoyyalamudiNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- DIY Multifunctional Magnetic Therapy Device (PEMF, RIFE ..) : Step 1: Therapeutic IndicationsDocument6 pagesDIY Multifunctional Magnetic Therapy Device (PEMF, RIFE ..) : Step 1: Therapeutic IndicationsSiddheshwar ChopraNo ratings yet
- EVE ReportDocument8 pagesEVE ReportMARY SIRACH DELA TORRENo ratings yet
- TM 9 6230 210 13p Floodlight SetDocument264 pagesTM 9 6230 210 13p Floodlight SetAdvocateNo ratings yet
- Sylvania 6626lctDocument60 pagesSylvania 6626lctAdkinsTV100% (1)
- Bingo - Marketing EnvironmentDocument4 pagesBingo - Marketing EnvironmentFahad MushtaqNo ratings yet
- IMU-10x Motion Sensor DatasheetDocument2 pagesIMU-10x Motion Sensor DatasheetSaad FatrouniNo ratings yet
- 45-53.8 11063344 PDFDocument40 pages45-53.8 11063344 PDFeng13No ratings yet
- CSCC 35 Week 7 ActivityadssadasdsadDocument4 pagesCSCC 35 Week 7 ActivityadssadasdsadnarcamarcoNo ratings yet
- Single Side BandDocument12 pagesSingle Side BandApril RodriquezNo ratings yet
- 445 - Guide - For - Transformer - Maintenance CIGRE A2 - 34 PDFDocument123 pages445 - Guide - For - Transformer - Maintenance CIGRE A2 - 34 PDFJohnDoe100% (10)
- CVA ProDocument1 pageCVA ProTommy TangNo ratings yet
- MS Samsung Slim Duct PDFDocument2 pagesMS Samsung Slim Duct PDFMacSparesNo ratings yet
- 11072914337094Document29 pages11072914337094iskenderbeyNo ratings yet
- Bipro - TD7G78M - 10BB - 580 - 600WDocument2 pagesBipro - TD7G78M - 10BB - 580 - 600WcarloscostacarreteroNo ratings yet
- EDO-MNL-CNS-COR-INT-XXX-021-921-1880-Rev-A HSG100 EX TYPE SPARK UP MANUALDocument6 pagesEDO-MNL-CNS-COR-INT-XXX-021-921-1880-Rev-A HSG100 EX TYPE SPARK UP MANUALErol DAĞNo ratings yet
- Innolux tw230fDocument37 pagesInnolux tw230fMichael QuerubinNo ratings yet
- Data Sheet: Thin Film Chip ResistorsDocument9 pagesData Sheet: Thin Film Chip ResistorslalithkumartNo ratings yet
- Aoc 152v Tsum16akDocument49 pagesAoc 152v Tsum16akedyNo ratings yet
- UniFi Consumer Service GuideDocument142 pagesUniFi Consumer Service GuideAnisNo ratings yet
- Iec61131-2 (Ed4 0) BDocument231 pagesIec61131-2 (Ed4 0) BLesha100% (1)
- Machine Vision - The Past, The Present and The FutureDocument30 pagesMachine Vision - The Past, The Present and The FutureCassiano Kleinert CasagrandeNo ratings yet
- AddmDocument5 pagesAddmMaheedhar PasupuletiNo ratings yet
- Mobile Business Intelligence App Design & DevelopmentDocument2 pagesMobile Business Intelligence App Design & DevelopmentInfoCepts IncNo ratings yet
- Manual CRT SS7900 ENG-3Document23 pagesManual CRT SS7900 ENG-3Dante NeroNo ratings yet
- HST Pines Komatsu Wa320Document1 pageHST Pines Komatsu Wa320Victor Rodrigo Cortes YañezNo ratings yet
- Av Gad Av 2008 Dublo, Av 2016 DubloDocument60 pagesAv Gad Av 2008 Dublo, Av 2016 DubloPeraDetlicNo ratings yet
- Server L10 Training Day1 - FDocument81 pagesServer L10 Training Day1 - Fbren john monserratNo ratings yet
- Ejercicios de Electrohidráulica BásicaDocument184 pagesEjercicios de Electrohidráulica BásicaLuis RossoNo ratings yet
- Mando Universal One For One Urc-7542Document25 pagesMando Universal One For One Urc-7542karioteNo ratings yet