You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- DC 7 BrochureDocument4 pagesDC 7 Brochures_a_r_r_yNo ratings yet
- DNA ReplicationDocument19 pagesDNA ReplicationLouis HilarioNo ratings yet
- Chapter 8 Data Collection InstrumentsDocument19 pagesChapter 8 Data Collection InstrumentssharmabastolaNo ratings yet
- Lesson 6 ComprogDocument25 pagesLesson 6 ComprogmarkvillaplazaNo ratings yet
- PyhookDocument23 pagesPyhooktuan tuanNo ratings yet
- 1.technical Specifications (Piling)Document15 pages1.technical Specifications (Piling)Kunal Panchal100% (2)
- LM74680 Fasson® Fastrans NG Synthetic PE (ST) / S-2050/ CK40Document2 pagesLM74680 Fasson® Fastrans NG Synthetic PE (ST) / S-2050/ CK40Nishant JhaNo ratings yet
- Unit 16 - Monitoring, Review and Audit by Allan WatsonDocument29 pagesUnit 16 - Monitoring, Review and Audit by Allan WatsonLuqman OsmanNo ratings yet
- Roleplayer: The Accused Enchanted ItemsDocument68 pagesRoleplayer: The Accused Enchanted ItemsBarbie Turic100% (1)
- 3 ALCE Insulators 12R03.1Document12 pages3 ALCE Insulators 12R03.1Amílcar Duarte100% (1)
- Corrosion Fatigue Phenomena Learned From Failure AnalysisDocument10 pagesCorrosion Fatigue Phenomena Learned From Failure AnalysisDavid Jose Velandia MunozNo ratings yet
- Monkey Says, Monkey Does Security andDocument11 pagesMonkey Says, Monkey Does Security andNudeNo ratings yet
- Review1 ScheduleDocument3 pagesReview1 Schedulejayasuryam.ae18No ratings yet
- AnticyclonesDocument5 pagesAnticyclonescicileanaNo ratings yet
- Report Card Grade 1 2Document3 pagesReport Card Grade 1 2Mely DelacruzNo ratings yet
- Thermally Curable Polystyrene Via Click ChemistryDocument4 pagesThermally Curable Polystyrene Via Click ChemistryDanesh AzNo ratings yet
- Carriage RequirementsDocument63 pagesCarriage RequirementsFred GrosfilerNo ratings yet
- Marketing FinalDocument15 pagesMarketing FinalveronicaNo ratings yet
- SSGC-RSGLEG Draft Study On The Applicability of IAL To Cyber Threats Against Civil AviationDocument41 pagesSSGC-RSGLEG Draft Study On The Applicability of IAL To Cyber Threats Against Civil AviationPrachita AgrawalNo ratings yet
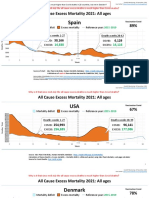
- Countries EXCESS DEATHS All Ages - 15nov2021Document21 pagesCountries EXCESS DEATHS All Ages - 15nov2021robaksNo ratings yet
- DN Cross Cutting IssuesDocument22 pagesDN Cross Cutting Issuesfatmama7031No ratings yet
- Huawei R4815N1 DatasheetDocument2 pagesHuawei R4815N1 DatasheetBysNo ratings yet
- PED003Document1 pagePED003ely mae dag-umanNo ratings yet
- Financial Accounting 2 SummaryDocument10 pagesFinancial Accounting 2 SummaryChoong Xin WeiNo ratings yet
- Hima OPC Server ManualDocument36 pagesHima OPC Server ManualAshkan Khajouie100% (3)
- Application of Graph Theory in Operations ResearchDocument3 pagesApplication of Graph Theory in Operations ResearchInternational Journal of Innovative Science and Research Technology100% (2)
- Project ManagementDocument11 pagesProject ManagementBonaventure NzeyimanaNo ratings yet
- Sba 2Document29 pagesSba 2api-377332228No ratings yet
- Post Appraisal InterviewDocument3 pagesPost Appraisal InterviewNidhi D100% (1)
- Traveling Salesman ProblemDocument11 pagesTraveling Salesman ProblemdeardestinyNo ratings yet