You might also like
- Oracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandOracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesRating: 5 out of 5 stars5/5 (1)
- AWR INTERPRETATIONDocument17 pagesAWR INTERPRETATIONPraveen KumarNo ratings yet
- Awr Report AnalysisDocument13 pagesAwr Report Analysissrinivas1224No ratings yet
- Oracle ASMDocument47 pagesOracle ASMVarun KrishnaNo ratings yet
- Performance Troubleshooting Using Active Session History PDFDocument59 pagesPerformance Troubleshooting Using Active Session History PDFnoman78No ratings yet
- Performance Scenario Sudden Slowdown On RacDocument45 pagesPerformance Scenario Sudden Slowdown On RacbehanchodNo ratings yet
- Diagnosis For DB HungDocument5 pagesDiagnosis For DB Hungnu04330No ratings yet
- AWR ReportDocument20 pagesAWR Reportsanjayid1980No ratings yet
- AWR Reports - 10 Steps To Analyze AWR Report in OracleDocument5 pagesAWR Reports - 10 Steps To Analyze AWR Report in OracleKhansex ShaikNo ratings yet
- Clone Oracle DB with Hot BackupDocument6 pagesClone Oracle DB with Hot BackupPrintesh PatelNo ratings yet
- Psu Patch On DGDocument14 pagesPsu Patch On DGThota Mahesh DbaNo ratings yet
- Tuning With AWRDocument29 pagesTuning With AWRsanthoshjsh409No ratings yet
- Apply Rolling PSU Patch in Oracle Database 12c RAC EnvironmentDocument6 pagesApply Rolling PSU Patch in Oracle Database 12c RAC EnvironmentNarayan AdhikariNo ratings yet
- 10 Steps To Analyze AWR Report in OracleDocument7 pages10 Steps To Analyze AWR Report in OracleModesto Lopez Ramos0% (1)
- Advanced Internal Oracle Tuning Techniques For SAP SystemsDocument79 pagesAdvanced Internal Oracle Tuning Techniques For SAP SystemsMarri MahipalNo ratings yet
- Core DBA ScriptsDocument115 pagesCore DBA ScriptsManoj Reddy75% (4)
- 11g Audit VaultDocument47 pages11g Audit VaultAkin AkinmosinNo ratings yet
- Oracle Cache Buffer InternalsDocument67 pagesOracle Cache Buffer InternalsSaeed MeethalNo ratings yet
- Rac Q&aDocument51 pagesRac Q&aVeeranji VelpulaNo ratings yet
- Daily WorkDocument68 pagesDaily Workapi-3819698No ratings yet
- Applying PSU Patch in A DataguardDocument36 pagesApplying PSU Patch in A Dataguardcharan817100% (1)
- Performance Tunning StepsDocument11 pagesPerformance Tunning StepsVinu3012No ratings yet
- How To Make Resume As Fresher Oracle DBA Myths-Mysteries-MemorableDocument7 pagesHow To Make Resume As Fresher Oracle DBA Myths-Mysteries-Memorablesriraam6No ratings yet
- 12c-Best Practices and Patching Oracle Database in GIDocument70 pages12c-Best Practices and Patching Oracle Database in GILayne Morán100% (1)
- Oracle ArchitectureDocument102 pagesOracle ArchitecturemanavalanmichaleNo ratings yet
- Dataguard Fsfo ImplementationDocument99 pagesDataguard Fsfo ImplementationfreshpNo ratings yet
- Rmougashmastershort 140207171440 Phpapp02Document111 pagesRmougashmastershort 140207171440 Phpapp02Thota Mahesh DbaNo ratings yet
- Optimize AWR ReportsDocument64 pagesOptimize AWR ReportssmslcaNo ratings yet
- How To Determine If PGA Size Is Set ProperlyDocument5 pagesHow To Determine If PGA Size Is Set Properlypatrick_wangrui100% (1)
- Reading An Oracle AWR ReportDocument61 pagesReading An Oracle AWR Reportnt29No ratings yet
- Oracle DBA Interview Q&ADocument58 pagesOracle DBA Interview Q&Aaorya100% (1)
- Scripts DBADocument7 pagesScripts DBAmdinesh81No ratings yet
- ORACLE DBA Activity ChecklistDocument12 pagesORACLE DBA Activity ChecklistRafaelNo ratings yet
- Oracle Database Backup-and-Recovery Best PracticesDocument52 pagesOracle Database Backup-and-Recovery Best PracticesOracleconslt OracleconsltNo ratings yet
- Rman Interview Questions 2019Document18 pagesRman Interview Questions 2019nagendrakumarymNo ratings yet
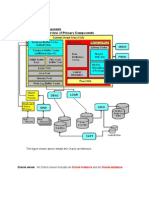
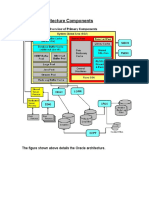
- Oracle Database Architecture ComponentsDocument58 pagesOracle Database Architecture Componentspiciul2010No ratings yet
- 11gR2 RAC-Install Workshop Day1Document33 pages11gR2 RAC-Install Workshop Day1Tomas E Carpio MilanoNo ratings yet
- Database Optimization Interview: AnswerDocument13 pagesDatabase Optimization Interview: AnswerRajesh BhardwajNo ratings yet
- Always On HighavailabilityDocument20 pagesAlways On HighavailabilitySyed NoumanNo ratings yet
- D AshDocument6 pagesD Ashsaibabu_dNo ratings yet
- Implementing Oracle Database SecurityDocument21 pagesImplementing Oracle Database SecurityNett2kNo ratings yet
- Database Architecture Oracle DbaDocument41 pagesDatabase Architecture Oracle DbaImran ShaikhNo ratings yet
- Oracle ArchitectureDocument17 pagesOracle ArchitectureAzeem100% (1)
- SQL Tuning Made Easier With SQLTXPLAIN PDFDocument28 pagesSQL Tuning Made Easier With SQLTXPLAIN PDFMabu DbaNo ratings yet
- Oracle GoldenGate NotesDocument9 pagesOracle GoldenGate NotesabishekvsNo ratings yet
- DB Tuning ScriptsDocument4 pagesDB Tuning Scriptssundarsms2001No ratings yet
- Internals of Active DataGuardDocument28 pagesInternals of Active DataGuardsaibabu_d100% (1)
- Oracle GoldenGate 101 - IntroductionDocument73 pagesOracle GoldenGate 101 - Introductionalina_anchidinNo ratings yet
- Tanel Poder Oracle Execution PlansDocument32 pagesTanel Poder Oracle Execution PlansIvan SiparenkoNo ratings yet
- Golden Gate Oracle ReplicationDocument3 pagesGolden Gate Oracle ReplicationCynthiaNo ratings yet
- Oracle TuningDocument80 pagesOracle Tuningmaris chandranNo ratings yet
- Advanced RAC TroubleshootingDocument121 pagesAdvanced RAC TroubleshootingdrummerrNo ratings yet
- Advanced Oracle Troubleshooting - Live SessionDocument49 pagesAdvanced Oracle Troubleshooting - Live Sessionbloody007No ratings yet
- D78846GC20 13Document21 pagesD78846GC20 13Thanh PhongNo ratings yet
- Pro Oracle SQL Development: Best Practices for Writing Advanced QueriesFrom EverandPro Oracle SQL Development: Best Practices for Writing Advanced QueriesNo ratings yet
- Tantrasara of Abhinavagupta - H.N. Chakravarty Trans SCAN (283p) (Anomolous)Document283 pagesTantrasara of Abhinavagupta - H.N. Chakravarty Trans SCAN (283p) (Anomolous)soma3nath100% (1)
- Enterprise Holdings Enterprise Holdings: Oracle Data Guard - Strategic OverviewDocument8 pagesEnterprise Holdings Enterprise Holdings: Oracle Data Guard - Strategic Overviewsoma3nathNo ratings yet
- Determining Iops Needs For Oracle Database On AwsDocument10 pagesDetermining Iops Needs For Oracle Database On AwsnaserNo ratings yet
- TEN MAHAVIDYASDocument100 pagesTEN MAHAVIDYASsoma3nath100% (3)
- Industries and Its Connected LoadDocument812 pagesIndustries and Its Connected Loadsoma3nathNo ratings yet
- Helpful HintsDocument10 pagesHelpful Hintssoma3nathNo ratings yet
- Lamp Apache Mysql PHP Quick Install On Linux 1172 m0w770Document3 pagesLamp Apache Mysql PHP Quick Install On Linux 1172 m0w770soma3nathNo ratings yet
- Pedda Bala Siksha - 1Document25 pagesPedda Bala Siksha - 1vemsudheer89% (9)
- How To Solve A 4 by 4 by 4 Rubiks CubeDocument23 pagesHow To Solve A 4 by 4 by 4 Rubiks Cubesoma3nathNo ratings yet
- RTC PDFDocument1 pageRTC PDFsoma3nathNo ratings yet
- Diagnostic Pack 11g Ds 068465Document4 pagesDiagnostic Pack 11g Ds 068465soma3nathNo ratings yet
- Tuning TipsDocument41 pagesTuning Tipssoma3nathNo ratings yet
- PeopleTools 8.53 XML PublisherDocument96 pagesPeopleTools 8.53 XML PublisherNEKRO100% (1)
- An Introduction to Enrollment Processing in PeopleSoftDocument34 pagesAn Introduction to Enrollment Processing in PeopleSoftsoma3nathNo ratings yet
- Enterprise Holdings Enterprise Holdings: Oracle Data Guard - Strategic OverviewDocument8 pagesEnterprise Holdings Enterprise Holdings: Oracle Data Guard - Strategic Overviewsoma3nathNo ratings yet
- Type TestfdfDocument1 pageType Testfdfsoma3nathNo ratings yet
- Run CommandsDocument6 pagesRun Commandssoma3nathNo ratings yet
- Run CommandsDocument3 pagesRun Commandssoma3nathNo ratings yet
- 108 Upanishads With PDF IndexDocument1,438 pages108 Upanishads With PDF Index1001nuits50% (2)
- Durga's Iconography and Mantra Sadhana PracticesDocument9 pagesDurga's Iconography and Mantra Sadhana Practicessoma3nathNo ratings yet
- Thrinath Soma – SAP Basis Consultant ProceduresDocument179 pagesThrinath Soma – SAP Basis Consultant Proceduressoma3nathNo ratings yet
- Creation of Replication InstanceDocument16 pagesCreation of Replication Instancesoma3nathNo ratings yet
- Creating A RFC DestinationDocument2 pagesCreating A RFC Destinationsoma3nathNo ratings yet
- Brspace ManagementDocument3 pagesBrspace Managementsoma3nathNo ratings yet
- Dos AttackedDocument4 pagesDos Attackedpaul_17oct@yahoo.co.in100% (2)
- SD Electrolux LT 4 Partisi 21082023Document3 pagesSD Electrolux LT 4 Partisi 21082023hanifahNo ratings yet
- Distribution of Laptop (Ha-Meem Textiles Zone)Document3 pagesDistribution of Laptop (Ha-Meem Textiles Zone)Begum Nazmun Nahar Juthi MozumderNo ratings yet
- UW Computational-Finance & Risk Management Brochure Final 080613Document2 pagesUW Computational-Finance & Risk Management Brochure Final 080613Rajel MokNo ratings yet
- 2JA5K2 FullDocument22 pages2JA5K2 FullLina LacorazzaNo ratings yet
- Abb Drives: User'S Manual Flashdrop Mfdt-01Document62 pagesAbb Drives: User'S Manual Flashdrop Mfdt-01Сергей СалтыковNo ratings yet
- Planning For Network Deployment in Oracle Solaris 11.4: Part No: E60987Document30 pagesPlanning For Network Deployment in Oracle Solaris 11.4: Part No: E60987errr33No ratings yet
- 3 Intro To Ozone LaundryDocument5 pages3 Intro To Ozone LaundrynavnaNo ratings yet
- Bob Wright's Declaration of BeingDocument1 pageBob Wright's Declaration of BeingBZ Riger100% (2)
- Computers As Components 2nd Edi - Wayne WolfDocument815 pagesComputers As Components 2nd Edi - Wayne WolfShubham RajNo ratings yet
- 6vortex 20166523361966663Document4 pages6vortex 20166523361966663Mieczysław MichalczewskiNo ratings yet
- Analytical DataDocument176 pagesAnalytical DataAsep KusnaliNo ratings yet
- Department Order No 05-92Document3 pagesDepartment Order No 05-92NinaNo ratings yet
- Complaint Handling Policy and ProceduresDocument2 pagesComplaint Handling Policy and Proceduresjyoti singhNo ratings yet
- DrugDocument2 pagesDrugSaleha YounusNo ratings yet
- COVID-19's Impact on Business PresentationsDocument2 pagesCOVID-19's Impact on Business PresentationsRetmo NandoNo ratings yet
- Multiple Choice Question (MCQ) of Alternator and Synchronous Motors PageDocument29 pagesMultiple Choice Question (MCQ) of Alternator and Synchronous Motors Pagekibrom atsbha0% (1)
- Marketing ManagementDocument14 pagesMarketing ManagementShaurya RathourNo ratings yet
- Chaman Lal Setia Exports Ltd fundamentals remain intactDocument18 pagesChaman Lal Setia Exports Ltd fundamentals remain intactbharat005No ratings yet
- Bunkering Check List: Yacht InformationDocument3 pagesBunkering Check List: Yacht InformationMarian VisanNo ratings yet
- Aci 207.1Document38 pagesAci 207.1safak kahraman100% (7)
- Milton Hershey's Sweet StoryDocument10 pagesMilton Hershey's Sweet Storysharlene sandovalNo ratings yet
- Product Manual 36693 (Revision D, 5/2015) : PG Base AssembliesDocument10 pagesProduct Manual 36693 (Revision D, 5/2015) : PG Base AssemblieslmarcheboutNo ratings yet
- Gates em Ingles 2010Document76 pagesGates em Ingles 2010felipeintegraNo ratings yet
- Craft's Folder StructureDocument2 pagesCraft's Folder StructureWowNo ratings yet
- L-1 Linear Algebra Howard Anton Lectures Slides For StudentDocument19 pagesL-1 Linear Algebra Howard Anton Lectures Slides For StudentHasnain AbbasiNo ratings yet
- POS CAL SF No4 B2 BCF H300x300 7mmweld R0 PDFDocument23 pagesPOS CAL SF No4 B2 BCF H300x300 7mmweld R0 PDFNguyễn Duy QuangNo ratings yet
- Programme Report Light The SparkDocument17 pagesProgramme Report Light The SparkAbhishek Mishra100% (1)
- Case Study 2 F3005Document12 pagesCase Study 2 F3005Iqmal DaniealNo ratings yet
- 158 Oesmer Vs Paraisa DevDocument1 page158 Oesmer Vs Paraisa DevRobelle Rizon100% (1)
- Fujitsu Spoljni Multi Inverter Aoyg45lbt8 Za 8 Unutrasnjih Jedinica KatalogDocument4 pagesFujitsu Spoljni Multi Inverter Aoyg45lbt8 Za 8 Unutrasnjih Jedinica KatalogSasa021gNo ratings yet