You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- QM Ch12 Network Models - ZaferDocument8 pagesQM Ch12 Network Models - ZaferHusukic Alen100% (1)
- Drinking Water Standards BIS 10500 2004 by BISDocument15 pagesDrinking Water Standards BIS 10500 2004 by BISkuntamNo ratings yet
- 1172Document18 pages1172Ameya SohoniNo ratings yet
- Natural TracersDocument17 pagesNatural TracersAbhishek MajiNo ratings yet
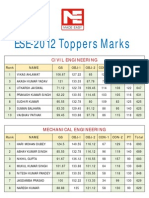
- Ese-12 Toppers Marks PDFDocument2 pagesEse-12 Toppers Marks PDFBanu SravanthNo ratings yet
- General Studies UPSC Exam PaperDocument48 pagesGeneral Studies UPSC Exam PaperSonakshi BehlNo ratings yet
- WWW - Upsc.gov - in Exams Notifications 2014 Ese Notice ESE-2014 EngDocument7 pagesWWW - Upsc.gov - in Exams Notifications 2014 Ese Notice ESE-2014 EngSubhankar UncertainityNo ratings yet
- HP Bitumen HandbookDocument53 pagesHP Bitumen HandbookAnuj Mathur100% (1)
- Study of Substitute Frame Method of Analysis For Lateral Loading ConditionsDocument39 pagesStudy of Substitute Frame Method of Analysis For Lateral Loading ConditionschauhannishargNo ratings yet
- MITRES 18 001 Strang TableseqDocument4 pagesMITRES 18 001 Strang TableseqSarandos KlikizosNo ratings yet
- Tunnel Blasting TechniquesDocument24 pagesTunnel Blasting TechniquesAbhishek MajiNo ratings yet
- Design of Steel StructuresDocument3 pagesDesign of Steel StructuresAbhishek Maji100% (1)
- SP16-Design Aid For RC To IS456-1978Document252 pagesSP16-Design Aid For RC To IS456-1978sateeshsingh90% (20)
- Graph TheoryDocument29 pagesGraph TheoryAbhishek MajiNo ratings yet
- Tata 4923 3Document2 pagesTata 4923 3Abhishek MajiNo ratings yet
- Structural-Systems For Strands, Ropes and CablesDocument8 pagesStructural-Systems For Strands, Ropes and CablesAbhishek MajiNo ratings yet
- Graph TheoryDocument29 pagesGraph TheoryAbhishek MajiNo ratings yet
- Orlin NF Chapter1Document2 pagesOrlin NF Chapter1Abdulganiyu IsmaeelNo ratings yet
- Cannibals MissionariesDocument8 pagesCannibals MissionariesElison José Gracite LusvardiNo ratings yet
- Art. PHAST Hardware Accelerated Shortest Path TreesDocument13 pagesArt. PHAST Hardware Accelerated Shortest Path TreesEdgar Cano FrancoNo ratings yet
- CS 520: Exploring SearchDocument3 pagesCS 520: Exploring SearchChaitanya BNo ratings yet
- Cp5151 Advanced Data Structures and AlgorithmsDocument4 pagesCp5151 Advanced Data Structures and AlgorithmsRame KNo ratings yet
- 18CS42 Model Question Paper - 1 With Effect From 2019-20 (CBCS Scheme)Document3 pages18CS42 Model Question Paper - 1 With Effect From 2019-20 (CBCS Scheme)M.A rajaNo ratings yet
- Intro To Dynamic ProgrammingDocument7 pagesIntro To Dynamic ProgrammingUtkarsh PatelNo ratings yet
- Gate QuestionsDocument35 pagesGate QuestionsSarkunavathi AribalNo ratings yet
- OR 7310 Logistics, Warehousing, and Scheduling: Fall 2020Document3 pagesOR 7310 Logistics, Warehousing, and Scheduling: Fall 2020Sravan KumarNo ratings yet
- CS347 - Design and Analysis of Algorithm - 19-23 V1Document5 pagesCS347 - Design and Analysis of Algorithm - 19-23 V1mayuri moreNo ratings yet
- Lab FileDocument29 pagesLab FileHarshita MeenaNo ratings yet
- Ada LabDocument2 pagesAda LabsanjeevkunteNo ratings yet
- M.Tech. ITDocument119 pagesM.Tech. ITShobana SNo ratings yet
- Network Modelling For Road-Based Faecal Sludge ManagementDocument9 pagesNetwork Modelling For Road-Based Faecal Sludge ManagementEddiemtongaNo ratings yet
- DR Nazir A. Zafar Advanced Algorithms Analysis and DesignDocument30 pagesDR Nazir A. Zafar Advanced Algorithms Analysis and DesignAE ShahNo ratings yet
- 3 - Design and Analysis of AlgorithmsDocument188 pages3 - Design and Analysis of AlgorithmsUdupiSri groupNo ratings yet
- Programming Assignment 4: Paths in GraphsDocument17 pagesProgramming Assignment 4: Paths in GraphsShahid AnsariNo ratings yet
- Minimal Spanning Tree PDFDocument4 pagesMinimal Spanning Tree PDFAravindNo ratings yet
- Clrs ContentDocument5 pagesClrs ContentThomas RamosNo ratings yet
- Daa Lab SectionDocument11 pagesDaa Lab Sectionp bbNo ratings yet
- Dijkstra's Algorithm PPGDocument12 pagesDijkstra's Algorithm PPGEida Wahida ZLNo ratings yet
- Linear Programming: Brewer's Problem Simplex Algorithm Implementation Linear ProgrammingDocument49 pagesLinear Programming: Brewer's Problem Simplex Algorithm Implementation Linear ProgrammingFadugbaNo ratings yet
- A Variable Neighbourhood Search Algorithm To Generate Piano Fingerings For Polyphonic Sheet MusicDocument25 pagesA Variable Neighbourhood Search Algorithm To Generate Piano Fingerings For Polyphonic Sheet MusicDorien HerremansNo ratings yet
- Data Structure and Algorithms (CS-443) : University Institute of Information TechnologyDocument6 pagesData Structure and Algorithms (CS-443) : University Institute of Information TechnologyHahsadasdNo ratings yet
- Introduction To Algorithms: A Creative ApproachDocument7 pagesIntroduction To Algorithms: A Creative Approachanimesh_ccna0% (6)
- A Genetic Algorithm Approach To Solve The Shortest Path Problem For Road MapsDocument4 pagesA Genetic Algorithm Approach To Solve The Shortest Path Problem For Road MapswendersoncsdepNo ratings yet
- Cs502 Collection of Old PapersDocument49 pagesCs502 Collection of Old Paperscs619finalproject.comNo ratings yet
- 547f39f7a0142 Network AnalysisDocument38 pages547f39f7a0142 Network Analysisyiğit tirkeşNo ratings yet