You might also like
- Comprehensive Guide to Implementing Data Science and Analytics: Tips, Recommendations, and Strategies for SuccessFrom EverandComprehensive Guide to Implementing Data Science and Analytics: Tips, Recommendations, and Strategies for SuccessNo ratings yet
- Does The Use of Technical & Fundamental Analysis Improve Stock Choice?Document6 pagesDoes The Use of Technical & Fundamental Analysis Improve Stock Choice?mazin903No ratings yet
- Predictable Variation and Pro"table Trading of US Equities: A Trading Simulation Using Neural NetworksDocument19 pagesPredictable Variation and Pro"table Trading of US Equities: A Trading Simulation Using Neural NetworksJulio OliveiraNo ratings yet
- Navigating Big Data Analytics: Strategies for the Quality Systems AnalystFrom EverandNavigating Big Data Analytics: Strategies for the Quality Systems AnalystNo ratings yet
- Deep Learning Based Model To Forecast The Direction of Stock Exchange Market Using Social Media A ReviewDocument5 pagesDeep Learning Based Model To Forecast The Direction of Stock Exchange Market Using Social Media A ReviewIJRASETPublications100% (1)
- Analysis of Trends in Stock MarketDocument10 pagesAnalysis of Trends in Stock MarketIJRASETPublications100% (1)
- Algo TradingDocument10 pagesAlgo Tradinglijanamano6No ratings yet
- Chapter 1Document7 pagesChapter 1ashi ashiNo ratings yet
- Systems 10 00243 v3 PDFDocument31 pagesSystems 10 00243 v3 PDFzik1987No ratings yet
- Forecasting of Stock Prices Using Multi Layer PerceptronDocument6 pagesForecasting of Stock Prices Using Multi Layer Perceptronijbui iir100% (1)
- Fin Irjmets1681823617 PDFDocument6 pagesFin Irjmets1681823617 PDFappuNo ratings yet
- Biclustering Learning of Trading RulesDocument12 pagesBiclustering Learning of Trading Rulesşafak erdoğduNo ratings yet
- Multi-Agent Q Learning Daily Trading 2007Document14 pagesMulti-Agent Q Learning Daily Trading 2007biddon14No ratings yet
- Using Neural Networks To Forecast Stock Market Prices: January 1998Document22 pagesUsing Neural Networks To Forecast Stock Market Prices: January 1998nicolas españaNo ratings yet
- A Technique To Stock Market Prediction Using Fuzzy Clustering and Artificial Neural Networks Rajendran SugumarDocument33 pagesA Technique To Stock Market Prediction Using Fuzzy Clustering and Artificial Neural Networks Rajendran SugumarMaryam OmolaraNo ratings yet
- Trading in Indian Stock Market Using ANN: A Decision ReviewDocument11 pagesTrading in Indian Stock Market Using ANN: A Decision Reviewmonik shahNo ratings yet
- S M P N L P - A S: Tock Arket Rediction Using Atural Anguage Rocessing UrveyDocument16 pagesS M P N L P - A S: Tock Arket Rediction Using Atural Anguage Rocessing Urveyjobawoc774No ratings yet
- Prediction of Stock Market Using Machine Learning AlgorithmsDocument12 pagesPrediction of Stock Market Using Machine Learning AlgorithmsterranceNo ratings yet
- Stock Market Forecasting Techniques: A Survey: G. Preethi, B. SanthiDocument7 pagesStock Market Forecasting Techniques: A Survey: G. Preethi, B. SanthiJames CharoensukNo ratings yet
- Expert Systems With Applications: Chui-Yu Chiu, Yi-Feng Chen, I-Ting Kuo, He Chun KuDocument8 pagesExpert Systems With Applications: Chui-Yu Chiu, Yi-Feng Chen, I-Ting Kuo, He Chun Kusabbir HossainNo ratings yet
- $+/Eulg6/Vwhpe/,Qwhjudwlqj&Dvh%Dvhg5Hdvrqlqjdqg) X) ) / 'Hflvlrq7Uhhiru) Lqdqfldo7Lph6Hulhv'DwdDocument7 pages$+/Eulg6/Vwhpe/,Qwhjudwlqj&Dvh%Dvhg5Hdvrqlqjdqg) X) ) / 'Hflvlrq7Uhhiru) Lqdqfldo7Lph6Hulhv'DwdYaşanur KayikciNo ratings yet
- Sentire 2018 WangDocument6 pagesSentire 2018 Wangnurdi afriantoNo ratings yet
- Applied Sciences: Prediction of Stock Performance Using Deep Neural NetworksDocument20 pagesApplied Sciences: Prediction of Stock Performance Using Deep Neural NetworksLuiz RamosNo ratings yet
- DeepikaDocument15 pagesDeepikaDeepikaNo ratings yet
- Estimation of Return On Investment in Share Market Through AnnDocument11 pagesEstimation of Return On Investment in Share Market Through AnnShashi KumarNo ratings yet
- A Securities Exchange Prospect Utilizing AIDocument4 pagesA Securities Exchange Prospect Utilizing AIInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Empirical Research NiftyDocument13 pagesEmpirical Research NiftyappuNo ratings yet
- Predicting Stock Prices Using Data Mining TechniquesDocument9 pagesPredicting Stock Prices Using Data Mining TechniquesMadhumitha AkkarajuNo ratings yet
- A Comparative Study On Financial Stock Market Prediction ModelsDocument4 pagesA Comparative Study On Financial Stock Market Prediction ModelstheijesNo ratings yet
- Neural Networks For Market PredictionDocument21 pagesNeural Networks For Market PredictionBernard GagnonNo ratings yet
- Research PaperDocument11 pagesResearch PaperAditya JaiswalNo ratings yet
- Stock Market Prediction Using Deep LearningDocument9 pagesStock Market Prediction Using Deep LearningIJRASETPublications100% (1)
- Machine Learning Algorithms For Stock Market PredictionDocument3 pagesMachine Learning Algorithms For Stock Market PredictionMahima MurthyNo ratings yet
- 2019 - Machine Learning (6) (Teori)Document10 pages2019 - Machine Learning (6) (Teori)Rosnani Ginting TBANo ratings yet
- Stock Market Prediction Analysis by Incorporating Social and News Opinion and SentimentDocument7 pagesStock Market Prediction Analysis by Incorporating Social and News Opinion and SentimentRahul TiwariNo ratings yet
- Latex Secure Home AutomationDocument21 pagesLatex Secure Home Automationkrishna1228No ratings yet
- Visualizing and Forecasting Stocks Using Machine LearningDocument7 pagesVisualizing and Forecasting Stocks Using Machine LearningIJRASETPublications100% (1)
- Sustainability 10 03765Document18 pagesSustainability 10 03765teytjbberys2s6jt teytjbberys2s6jtNo ratings yet
- Data Mining Techniques in Stock Market: Amit Vashisth Roll No. 03216603913 MBA (Gen) 2 YrDocument8 pagesData Mining Techniques in Stock Market: Amit Vashisth Roll No. 03216603913 MBA (Gen) 2 YrAmit VashisthNo ratings yet
- Stock Market Prediction Research PaperDocument7 pagesStock Market Prediction Research Papervstxevplg100% (1)
- A Fuzzy Logic Based Trading System - Wee Mien Cheung and Uzay KaymakDocument12 pagesA Fuzzy Logic Based Trading System - Wee Mien Cheung and Uzay Kaymakjimthegreatone100% (1)
- Neural Network Modeling For Stock Movement Prediction A State of The ArtDocument5 pagesNeural Network Modeling For Stock Movement Prediction A State of The ArtjohnstreetmailinatorNo ratings yet
- Stock Market Prediction Using LSTMDocument7 pagesStock Market Prediction Using LSTMIJRASETPublications100% (1)
- What-If Analysis TemplateDocument5 pagesWhat-If Analysis Templatenathaniel.chrNo ratings yet
- Clustering-Classification Based Prediction of Stock Market Future PredictionDocument4 pagesClustering-Classification Based Prediction of Stock Market Future PredictionAnkitNo ratings yet
- Entropy 18 00435 PDFDocument16 pagesEntropy 18 00435 PDFKarim LaidiNo ratings yet
- Stock Market AnalysisDocument4 pagesStock Market AnalysisIJRASETPublications100% (1)
- Stock Market Time Series AnalysisDocument12 pagesStock Market Time Series AnalysisTanay JainNo ratings yet
- Tugas Paper Riset Metodologi A.Raharto Condrobimo R3 PDFDocument4 pagesTugas Paper Riset Metodologi A.Raharto Condrobimo R3 PDFAndreas Raharto CondrobimoNo ratings yet
- Relative TendencyDocument5 pagesRelative Tendencyc_mc2No ratings yet
- CC Unit - 4 Imp QuestionsDocument4 pagesCC Unit - 4 Imp QuestionsSahana UrsNo ratings yet
- A Neural Network Based Approach To SuppoDocument8 pagesA Neural Network Based Approach To SuppoYazan BarjawiNo ratings yet
- Machine Learning Algorithms For Stock Market PredictionDocument3 pagesMachine Learning Algorithms For Stock Market PredictionMahima MurthyNo ratings yet
- (IJCST-V10I5P49) :mrs R Jhansi Rani, C NithinDocument8 pages(IJCST-V10I5P49) :mrs R Jhansi Rani, C NithinEighthSenseGroupNo ratings yet
- AMFA - Volume 6 - Issue 3 - Pages 653-669Document17 pagesAMFA - Volume 6 - Issue 3 - Pages 653-669algrionNo ratings yet
- Big Data Internal 2 Answers-1-9Document9 pagesBig Data Internal 2 Answers-1-9TKKNo ratings yet
- Machine Learning Algorithms For Stock Market PredictionDocument3 pagesMachine Learning Algorithms For Stock Market PredictionMahima MurthyNo ratings yet
- Big Data Internal 2 AnswersDocument9 pagesBig Data Internal 2 AnswersTKKNo ratings yet
- Neural Networks For The Analysis and For PDFDocument16 pagesNeural Networks For The Analysis and For PDFShrinivas. HNo ratings yet
- Week 12 - Chapter 25Document77 pagesWeek 12 - Chapter 25Arijit DasNo ratings yet
- SAS Macro Tutorial ImpDocument27 pagesSAS Macro Tutorial ImpArijit DasNo ratings yet
- Kindergarden School ListDocument2 pagesKindergarden School ListArijit DasNo ratings yet
- MergeDocument16 pagesMergeArijit Das0% (1)
- Quantitative Models in Marketing ResearchDocument222 pagesQuantitative Models in Marketing ResearchArijit DasNo ratings yet
- MPRA Paper 52967Document55 pagesMPRA Paper 52967Arijit DasNo ratings yet
- Modelling Credit Risk For Personal Loans Using Product-Limit EstimatorDocument11 pagesModelling Credit Risk For Personal Loans Using Product-Limit EstimatorArijit DasNo ratings yet
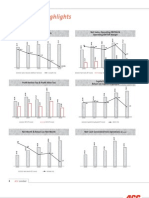
- Performance Highlights: Sales Volume & Growth % Net Sales, Operating EBITDA & Operating EBITDA MarginDocument4 pagesPerformance Highlights: Sales Volume & Growth % Net Sales, Operating EBITDA & Operating EBITDA MarginArijit DasNo ratings yet
- StatPac TutorialDocument73 pagesStatPac TutorialArijit DasNo ratings yet
- Globalisation, Cosmopolitanism and EcologicalDocument16 pagesGlobalisation, Cosmopolitanism and EcologicalRidhimaSoniNo ratings yet
- Younified LevelupDocument9 pagesYounified LevelupMitesh NagpalNo ratings yet
- Aman-Gupta CVDocument2 pagesAman-Gupta CVShrish GaurNo ratings yet
- Primate City & Rank Size Rule: O P A DDocument7 pagesPrimate City & Rank Size Rule: O P A DOmkar G. ParishwadNo ratings yet
- Evermotion Archmodels Vol 40 PDFDocument2 pagesEvermotion Archmodels Vol 40 PDFJustinNo ratings yet
- Surface Tension Theory - EDocument11 pagesSurface Tension Theory - EthinkiitNo ratings yet
- 18 SSBDocument162 pages18 SSBapi-3806887No ratings yet
- Data Gathering Advantage and DisadvantageDocument4 pagesData Gathering Advantage and DisadvantageJuan VeronNo ratings yet
- Jurutera August 2014Document28 pagesJurutera August 2014Edison LimNo ratings yet
- Elements of Short Story WORKBOOKDocument26 pagesElements of Short Story WORKBOOKDavid Velez Gonzalez100% (2)
- Control System QBDocument29 pagesControl System QBPrabhavathi AadhiNo ratings yet
- Teacher Induction Program Module 2Document54 pagesTeacher Induction Program Module 2Acee Lagarto75% (8)
- MGT602 Quiz 2 290411Document8 pagesMGT602 Quiz 2 290411sonutilkNo ratings yet
- Week1 - Introduction To Business Process ManagementDocument29 pagesWeek1 - Introduction To Business Process ManagementRamsky Baddongon PadigNo ratings yet
- Masterfile - Archer & Bull - UG 2022 - IITMDocument9 pagesMasterfile - Archer & Bull - UG 2022 - IITMSam TyagiNo ratings yet
- RuffaBadilla ArticlesDocument4 pagesRuffaBadilla ArticlesRuffa Mae BadillaNo ratings yet
- Nursing Research Lec 09Document116 pagesNursing Research Lec 09malyn1218100% (2)
- Extra Counting ProblemsDocument25 pagesExtra Counting ProblemsWilson ZhangNo ratings yet
- Becoming A Rhetor - Adora CurryDocument3 pagesBecoming A Rhetor - Adora CurryAdora CurryNo ratings yet
- Extemporaneous Speech in Oral CommunicationDocument3 pagesExtemporaneous Speech in Oral CommunicationStephanie BengcoNo ratings yet
- Ass AsDocument2 pagesAss AsMukesh BishtNo ratings yet
- The Essential Guide To Developing A Social Recruiting StrategyDocument48 pagesThe Essential Guide To Developing A Social Recruiting Strategysubzzz222No ratings yet
- Semantics Course BookDocument67 pagesSemantics Course BookJosipa Blažević50% (2)
- Chemistry 102 Experiment 8 ColorimetryDocument7 pagesChemistry 102 Experiment 8 ColorimetryDaniel MedeirosNo ratings yet
- CA Cooling TowerDocument19 pagesCA Cooling TowerKeshia WiseNo ratings yet
- Alternative ADHD TreatmentDocument3 pagesAlternative ADHD TreatmentCindy VanegasNo ratings yet
- Case Study ResearchDocument20 pagesCase Study ResearchManish PuttyahNo ratings yet
- McPherson Charles Case Study - DebriefDocument10 pagesMcPherson Charles Case Study - DebriefSri NarendiranNo ratings yet
- 2010-2011 CatalogDocument339 pages2010-2011 CatalogSimon TabNo ratings yet
- ONLINE20042111 MoDocument16 pagesONLINE20042111 MoPhương HoàngNo ratings yet