You might also like
- 01 7.1 Distributions 13-14-0 PDF Week 7 New VersionDocument21 pages01 7.1 Distributions 13-14-0 PDF Week 7 New VersionBobNo ratings yet
- 10 FM 1 TN 1ppDocument101 pages10 FM 1 TN 1ppBobNo ratings yet
- Calc 1141 2Document27 pagesCalc 1141 2BobNo ratings yet
- 01 7.1 Distributions 13-14Document33 pages01 7.1 Distributions 13-14BobNo ratings yet
- ch19 3Document40 pagesch19 3BobNo ratings yet
- ch19 5Document6 pagesch19 5BobNo ratings yet
- ACTL4001 Lecture 11Document12 pagesACTL4001 Lecture 11BobNo ratings yet
- (Carmona R.a.) Interest Rate ModelsDocument58 pages(Carmona R.a.) Interest Rate ModelsBobNo ratings yet
- The Global Financial Crisis: - An Actuarial PerspectiveDocument3 pagesThe Global Financial Crisis: - An Actuarial PerspectiveBobNo ratings yet
- 301 302 303 X03mapDocument1 page301 302 303 X03mapKyungJun ShinNo ratings yet
- Linear Algebra Done WrongDocument231 pagesLinear Algebra Done WrongS NandaNo ratings yet
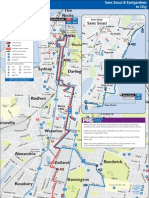
- 376 - 377 Bus MapDocument1 page376 - 377 Bus MapBobNo ratings yet
- History of The Actuarial ProfessionDocument3 pagesHistory of The Actuarial ProfessionBobNo ratings yet
- Linear Algebra Done WrongDocument231 pagesLinear Algebra Done WrongS NandaNo ratings yet
- 301 302 303 X03mapDocument1 page301 302 303 X03mapKyungJun ShinNo ratings yet
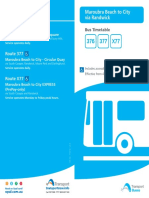
- 376 - 377 Bus Time TableDocument19 pages376 - 377 Bus Time TableBobNo ratings yet
- 376 - 377 Bus MapDocument1 page376 - 377 Bus MapBobNo ratings yet
- Hapter Xercise OlutionsDocument5 pagesHapter Xercise OlutionsBobNo ratings yet
- International: 2020 VisionDocument5 pagesInternational: 2020 VisionBobNo ratings yet
- 376 - 377 Bus Time TableDocument19 pages376 - 377 Bus Time TableBobNo ratings yet
- Takaful: An Islamic Alternative To Conventional Insurance Sees Phenomenal GrowthDocument3 pagesTakaful: An Islamic Alternative To Conventional Insurance Sees Phenomenal GrowthBobNo ratings yet
- Pension Benefit Design: Flexibility and The Integration of Insurance Over The Life CycleDocument43 pagesPension Benefit Design: Flexibility and The Integration of Insurance Over The Life CycleBobNo ratings yet
- Draft Standards For The Development of Spreadsheets: 1 Spreadsheets Can Be AssetsDocument5 pagesDraft Standards For The Development of Spreadsheets: 1 Spreadsheets Can Be AssetsBobNo ratings yet
- Is Insurance A Luxury?Document3 pagesIs Insurance A Luxury?BobNo ratings yet
- It's Time To Abolish Retirement (And Here's How To Do It) .: Work, Learn and Play Till You DropDocument47 pagesIt's Time To Abolish Retirement (And Here's How To Do It) .: Work, Learn and Play Till You DropBobNo ratings yet
- ch4 5Document37 pagesch4 5BobNo ratings yet
- Signs of Ageing: HealthcareDocument2 pagesSigns of Ageing: HealthcareBobNo ratings yet
- ch4 1Document42 pagesch4 1BobNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Ch6 Statistical HydrologyDocument16 pagesCh6 Statistical HydrologykundanNo ratings yet
- CVEN2002 Laboratory ExercisesDocument41 pagesCVEN2002 Laboratory ExercisesMary DinhNo ratings yet
- Questions and Answers On Unit Roots, Cointegration, Vars and VecmsDocument6 pagesQuestions and Answers On Unit Roots, Cointegration, Vars and VecmsTinotenda DubeNo ratings yet
- Probability, AUC, and Excel Linest FunctionDocument2 pagesProbability, AUC, and Excel Linest FunctionWathek Al Zuaiby0% (1)
- Periodic Table of The ElementsDocument36 pagesPeriodic Table of The ElementsJayakaran PachiyappanNo ratings yet
- Evaluation of Ambient Noise Levels in Port Harcourt Metropolis, South-South, NigeriaDocument7 pagesEvaluation of Ambient Noise Levels in Port Harcourt Metropolis, South-South, NigeriaIOSRjournalNo ratings yet
- Beetroot Core PracticalDocument15 pagesBeetroot Core PracticalSanngeeta100% (1)
- 03 Probability DistributionDocument3 pages03 Probability DistributionLKS-388No ratings yet
- Bayes GaussDocument29 pagesBayes GaussYogesh Nijsure100% (1)
- Fungicide Programs Used To Manage Powdery Mildew Erysiphe Ne - 2021 - Crop ProtDocument11 pagesFungicide Programs Used To Manage Powdery Mildew Erysiphe Ne - 2021 - Crop ProtIlija MileticNo ratings yet
- Analysis of Factors Affecting The Winning Percentage ODI Cricket MatchesDocument24 pagesAnalysis of Factors Affecting The Winning Percentage ODI Cricket MatchesVenu Gopal Vegi0% (1)
- Silk Reeling and Testing Manual. Chapter 2Document11 pagesSilk Reeling and Testing Manual. Chapter 2Vipin Singh KandholNo ratings yet
- 2024 State Competition Sprint RoundDocument8 pages2024 State Competition Sprint Roundshimmiguel00No ratings yet
- Inference About A Population VarianceDocument17 pagesInference About A Population VarianceIves LeeNo ratings yet
- Guia Diseño Aashto 93Document626 pagesGuia Diseño Aashto 93Geoffrey Collantes JulcaNo ratings yet
- Basic Statistics Formula SheetDocument5 pagesBasic Statistics Formula SheetHéctor FloresNo ratings yet
- Experiment 9 - DryingDocument10 pagesExperiment 9 - DryingMelike SucuNo ratings yet
- Skittles FinalDocument12 pagesSkittles Finalapi-241861434No ratings yet
- Mechanical Engineering Objective Type Questions For ExamsDocument7 pagesMechanical Engineering Objective Type Questions For ExamsSagarias AlbusNo ratings yet
- Assignment 1Document6 pagesAssignment 1Griffin William UnderwoodNo ratings yet
- Quantum XLExampleDocument83 pagesQuantum XLExamplesankar22No ratings yet
- Statistical Process Control.Document26 pagesStatistical Process Control.foofoolNo ratings yet
- Crop Yield PredictionDocument6 pagesCrop Yield PredictionVartul Tripathi100% (1)
- Materials of Construction and TestingDocument58 pagesMaterials of Construction and TestingChristian BaldoNo ratings yet
- Forecasting Long Range Dependent Time Series With Exogenous Variable Using ARFIMAX ModelDocument4 pagesForecasting Long Range Dependent Time Series With Exogenous Variable Using ARFIMAX ModelKrishna SarkarNo ratings yet
- Statistical Inference, Econometric Analysis and Matrix Algebra. Schipp, Bernhard Krämer, Walter. 2009Document445 pagesStatistical Inference, Econometric Analysis and Matrix Algebra. Schipp, Bernhard Krämer, Walter. 2009José Daniel Rivera MedinaNo ratings yet
- GraphPad Prism SlidesDocument79 pagesGraphPad Prism SlidesVasincuAlexandruNo ratings yet
- Traffic Prediction - Using AIDocument15 pagesTraffic Prediction - Using AIDhanvini BasavaNo ratings yet
- Lecture 8 - StatisticsDocument21 pagesLecture 8 - StatisticsMohanad SulimanNo ratings yet
- Every Number CountsDocument5 pagesEvery Number CountsGary GohNo ratings yet