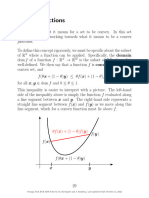
You might also like
- 06 Subgradients ScribedDocument5 pages06 Subgradients ScribedFaragNo ratings yet
- 1B Methods Lecture Notes: Richard Jozsa, DAMTP Cambridge Rj310@cam - Ac.ukDocument36 pages1B Methods Lecture Notes: Richard Jozsa, DAMTP Cambridge Rj310@cam - Ac.ukRomain LiNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- 1 Functions: 1.1 Definition of FunctionDocument9 pages1 Functions: 1.1 Definition of FunctionKen NuguidNo ratings yet
- Convex OptimizationDocument152 pagesConvex OptimizationnudalaNo ratings yet
- Chapter 2, Lecture 3: Building Convex FunctionsDocument4 pagesChapter 2, Lecture 3: Building Convex FunctionsCơ Đinh VănNo ratings yet
- Notes Day 18-22Document12 pagesNotes Day 18-22api-272815616No ratings yet
- Convexity Print VersionDocument13 pagesConvexity Print Versionsundari_muraliNo ratings yet
- Math 55 LE1 Reviewer NotesDocument6 pagesMath 55 LE1 Reviewer NotesJc QuintosNo ratings yet
- 18 GenfuncDocument20 pages18 GenfuncDương Minh ĐứcNo ratings yet
- Differential and Integral Calculus (Article) Author Kosuke ImaiDocument9 pagesDifferential and Integral Calculus (Article) Author Kosuke Imaistrangeowl1001No ratings yet
- Aditional Exercises Boyd PDFDocument164 pagesAditional Exercises Boyd PDFlandinluklaNo ratings yet
- Math Notes 2Document9 pagesMath Notes 2pravankarjog12345678No ratings yet
- Difference Calculus: N K 1 3 M X 1 N y 1 2 N K 0 KDocument9 pagesDifference Calculus: N K 1 3 M X 1 N y 1 2 N K 0 KAline GuedesNo ratings yet
- BV Cvxbook Extra ExercisesDocument156 pagesBV Cvxbook Extra ExercisesAnonymous WkbmWCa8MNo ratings yet
- A Graphical Derivation of The Legendre Transform: Sam Kennerly April 12, 2011Document9 pagesA Graphical Derivation of The Legendre Transform: Sam Kennerly April 12, 2011mlepck2No ratings yet
- Additional Exercises For Convex Optimization: Stephen Boyd Lieven Vandenberghe March 30, 2012Document143 pagesAdditional Exercises For Convex Optimization: Stephen Boyd Lieven Vandenberghe March 30, 2012api-127299018No ratings yet
- 9 Calculus: Differentiation: 9.1 First Optimization Result: Weierstraß TheoremDocument8 pages9 Calculus: Differentiation: 9.1 First Optimization Result: Weierstraß TheoremAqua Nail SpaNo ratings yet
- BV Cvxbook Extra ExercisesDocument139 pagesBV Cvxbook Extra ExercisesAkhil AmritaNo ratings yet
- AcamDocument32 pagesAcamAlin FodorNo ratings yet
- BV Cvxbook Extra Exercises2Document175 pagesBV Cvxbook Extra Exercises2Morokot AngelaNo ratings yet
- Calculus To First ExamDocument9 pagesCalculus To First ExamSteven WalkerNo ratings yet
- Midterm 18s SolDocument3 pagesMidterm 18s SolHamdi M. SaifNo ratings yet
- BV Cvxbook Extra ExercisesDocument165 pagesBV Cvxbook Extra ExercisesscatterwalkerNo ratings yet
- 1 Limits of FunctionsDocument6 pages1 Limits of FunctionsjoshNo ratings yet
- Bellocruz 2016Document19 pagesBellocruz 2016zhongyu xiaNo ratings yet
- Em14 IIDocument16 pagesEm14 IIAdri adriNo ratings yet
- sm192 1 03Document9 pagessm192 1 03FaidherRodriguezNo ratings yet
- Limits and Derivatives: 3.1 Limit at A PointDocument15 pagesLimits and Derivatives: 3.1 Limit at A PointKelvin LauNo ratings yet
- Elementary FunctionsDocument6 pagesElementary FunctionsHoàng Thành NguyễnNo ratings yet
- Intro To CalculusDocument26 pagesIntro To Calculuspgdm23samamalNo ratings yet
- Derivada de FréchetDocument18 pagesDerivada de FréchetVa LentínNo ratings yet
- Jefferson Socias Final Exam in CalculusDocument3 pagesJefferson Socias Final Exam in CalculusJefferson SociasNo ratings yet
- NCERT Continuity & DifferentiationDocument31 pagesNCERT Continuity & Differentiationmastermohit1No ratings yet
- Chapter 2Document82 pagesChapter 2Joenkon LiNo ratings yet
- MATH 115: Lecture II NotesDocument3 pagesMATH 115: Lecture II NotesDylan C. BeckNo ratings yet
- The Definite Integral SummationDocument7 pagesThe Definite Integral Summationmandy lagguiNo ratings yet
- 03 Convex Functions Notes Cvxopt f22Document21 pages03 Convex Functions Notes Cvxopt f22jchill2018No ratings yet
- Delta FunctionDocument4 pagesDelta FunctionRajib AdhikariNo ratings yet
- Improper IntegralDocument23 pagesImproper IntegralPblock Saher100% (1)
- 18.657: Mathematics of Machine Learning: S R LR LK KDocument9 pages18.657: Mathematics of Machine Learning: S R LR LK KBanupriya BalasubramanianNo ratings yet
- CSC2411 - Linear Programming and Combinatorial Optimization Lecture 1: Introduction To Optimization Problems and Mathematical ProgrammingDocument9 pagesCSC2411 - Linear Programming and Combinatorial Optimization Lecture 1: Introduction To Optimization Problems and Mathematical Programmingkostas_ntougias5453No ratings yet
- Calculation and Modelling of Radar Performance 4 Fourier TransformsDocument25 pagesCalculation and Modelling of Radar Performance 4 Fourier TransformsmmhoriiNo ratings yet
- Review of School Math Content Limits and IntegralDocument13 pagesReview of School Math Content Limits and IntegralwidhissNo ratings yet
- BV Cvxbook Extra ExercisesDocument187 pagesBV Cvxbook Extra ExercisesMorokot AngelaNo ratings yet
- Quantum Mech HandoutDocument153 pagesQuantum Mech HandoutFredrick MutungaNo ratings yet
- LP1 Math1 Unit-2 Edited-083121Document13 pagesLP1 Math1 Unit-2 Edited-083121hajiNo ratings yet
- Functions PDFDocument16 pagesFunctions PDFGaziyah BenthamNo ratings yet
- Lecture 14Document2 pagesLecture 14Syahir IshakNo ratings yet
- Calculus Review and Formulas: 1 FunctionsDocument11 pagesCalculus Review and Formulas: 1 FunctionsRaymond BalladNo ratings yet
- The Fundamental Theorem of CalculusDocument5 pagesThe Fundamental Theorem of CalculusDaiszyBarakaNo ratings yet
- Fundamental Theorem of CalculusDocument6 pagesFundamental Theorem of CalculusAmama ShafqatNo ratings yet
- Maths IntgrationDocument153 pagesMaths IntgrationLI DiaNo ratings yet
- Matrix Calculus: 1 The DerivativeDocument13 pagesMatrix Calculus: 1 The Derivativef270784100% (1)
- Green Functions For The Klein-Gordon Operator (v0.81)Document4 pagesGreen Functions For The Klein-Gordon Operator (v0.81)unwantedNo ratings yet
- Integral Inequalities For Concave FunctionsDocument15 pagesIntegral Inequalities For Concave FunctionsnastasescuNo ratings yet
- Summary Notes On Maximization: KC BorderDocument20 pagesSummary Notes On Maximization: KC BorderMiloje ĐukanovićNo ratings yet
- Quackery Begets Quackery: JakartaDocument15 pagesQuackery Begets Quackery: Jakartaamisha2562585No ratings yet
- Kaizen: The Five Foundation Elements of KaizenDocument2 pagesKaizen: The Five Foundation Elements of Kaizenamisha2562585No ratings yet
- Steel Report: Steel Sector News (Domestic and Global)Document2 pagesSteel Report: Steel Sector News (Domestic and Global)amisha2562585No ratings yet
- Earn Daily Profits From Any MarketDocument9 pagesEarn Daily Profits From Any MarketAmit Kumra100% (1)
- Five Competitive ForcesDocument3 pagesFive Competitive Forcesamisha2562585No ratings yet
- Leadership StylesDocument2 pagesLeadership Stylesamisha2562585No ratings yet
- P S. D - PMPDocument6 pagesP S. D - PMPamisha2562585No ratings yet
- Parenting AdvantageDocument1 pageParenting Advantageamisha2562585No ratings yet
- Marketing Mix - 4PsDocument1 pageMarketing Mix - 4Psamisha2562585No ratings yet
- How Industries ChangeDocument1 pageHow Industries Changeamisha2562585No ratings yet
- 14 Principles of ManagementDocument2 pages14 Principles of Managementamisha2562585No ratings yet
- Tacit KnowledgeDocument1 pageTacit Knowledgeamisha2562585No ratings yet
- IntroDocument1 pageIntroamisha2562585No ratings yet
- Credit Scoring ModifiedDocument51 pagesCredit Scoring Modifiedamisha2562585No ratings yet
- Breast CancerDocument12 pagesBreast Canceramisha2562585No ratings yet
- Clone Spy ResultDocument31 pagesClone Spy Resultamisha2562585No ratings yet
- ChurnDocument112 pagesChurnamisha2562585No ratings yet
- Errata Chapters6 11Document5 pagesErrata Chapters6 11amisha2562585No ratings yet
- Errata Chapters1 5Document3 pagesErrata Chapters1 5amisha2562585No ratings yet
- Consumer BehaviorDocument20 pagesConsumer BehaviorAmit GiriNo ratings yet
- PassportDocument1 pagePassportamisha2562585No ratings yet
- Survey Questionnaire - E Commerce Companies - BookAddaDocument3 pagesSurvey Questionnaire - E Commerce Companies - BookAddaamisha2562585No ratings yet
- MA Freelance Photography PSDocument6 pagesMA Freelance Photography PSamisha2562585No ratings yet
- Medical Center AddressesDocument7 pagesMedical Center Addressesamisha2562585No ratings yet
- How To Use DocusignDocument4 pagesHow To Use Docusignamisha2562585No ratings yet
- Required For GuesstimateDocument1 pageRequired For Guesstimateamisha2562585No ratings yet
- Medical Check Up1Document2 pagesMedical Check Up1amisha2562585No ratings yet
- Booklist PDFDocument7 pagesBooklist PDFpankajagg121No ratings yet
- BooksDocument1 pageBooksamisha2562585No ratings yet
- The Abcs of Edi: A Comprehensive Guide For 3Pl Warehouses: White PaperDocument12 pagesThe Abcs of Edi: A Comprehensive Guide For 3Pl Warehouses: White PaperIgor SangulinNo ratings yet
- LhiannanDocument6 pagesLhiannanGreybornNo ratings yet
- Pepsi Mix Max Mox ExperimentDocument2 pagesPepsi Mix Max Mox Experimentanon_192325873No ratings yet
- ZyLAB EDiscovery 3.11 What's New ManualDocument32 pagesZyLAB EDiscovery 3.11 What's New ManualyawahabNo ratings yet
- Form PersonalizationDocument5 pagesForm PersonalizationSuneelTejNo ratings yet
- Security Policy 6 E CommerceDocument6 pagesSecurity Policy 6 E CommerceShikha MehtaNo ratings yet
- Research in International Business and Finance: Huizheng Liu, Zhe Zong, Kate Hynes, Karolien de Bruyne TDocument13 pagesResearch in International Business and Finance: Huizheng Liu, Zhe Zong, Kate Hynes, Karolien de Bruyne TDessy ParamitaNo ratings yet
- ADP G2 Spreadsheet Loader Data Entry: End-User GuideDocument48 pagesADP G2 Spreadsheet Loader Data Entry: End-User Guideraokumar250% (2)
- Northern Lights - 7 Best Places To See The Aurora Borealis in 2022Document15 pagesNorthern Lights - 7 Best Places To See The Aurora Borealis in 2022labendetNo ratings yet
- Nodal Analysis Collection 2Document21 pagesNodal Analysis Collection 2Manoj ManmathanNo ratings yet
- COACHING TOOLS Mod4 TGOROWDocument6 pagesCOACHING TOOLS Mod4 TGOROWZoltan GZoltanNo ratings yet
- Communication MethodDocument30 pagesCommunication MethodMisganaw GishenNo ratings yet
- Service M5X0G SMDocument98 pagesService M5X0G SMbiancocfNo ratings yet
- Matter Around Me: SC1 - Teaching Science in ElementaryDocument27 pagesMatter Around Me: SC1 - Teaching Science in ElementaryYanna Marie Porlucas Macaraeg50% (2)
- BSBSTR602 Project PortfolioDocument16 pagesBSBSTR602 Project Portfoliocruzfabricio0No ratings yet
- KPJ Healthcare Berhad (NUS ANalyst)Document11 pagesKPJ Healthcare Berhad (NUS ANalyst)noniemoklasNo ratings yet
- Idoc - Pub - Pokemon Liquid Crystal PokedexDocument19 pagesIdoc - Pub - Pokemon Liquid Crystal PokedexPerfect SlaNaaCNo ratings yet
- Body Temperature PDFDocument56 pagesBody Temperature PDFBanupriya-No ratings yet
- Term Paper A and CDocument9 pagesTerm Paper A and CKishaloy NathNo ratings yet
- Opening Checklist: Duties: Monday Tuesday Wednesday Thursday Friday Saturday SundayDocument3 pagesOpening Checklist: Duties: Monday Tuesday Wednesday Thursday Friday Saturday SundayAlven BlancoNo ratings yet
- Product 97 File1Document2 pagesProduct 97 File1Stefan StefanNo ratings yet
- Unix SapDocument4 pagesUnix SapsatyavaninaiduNo ratings yet
- Installation, Operation & Maintenance Manual - Original VersionDocument11 pagesInstallation, Operation & Maintenance Manual - Original VersionAli AafaaqNo ratings yet
- Group 3 Presenta Tion: Prepared By: Queen Cayell Soyenn Gulo Roilan Jade RosasDocument12 pagesGroup 3 Presenta Tion: Prepared By: Queen Cayell Soyenn Gulo Roilan Jade RosasSeyell DumpNo ratings yet
- Characteristics: Our in Vitro IdentityDocument4 pagesCharacteristics: Our in Vitro IdentityMohammed ArifNo ratings yet
- SOLVING THE STEADY STATE SOLVER AND UNSTEADY or TRANSIENT SOLVER 2D HEAT CONDUCTION PROBLEM BY USINGDocument3 pagesSOLVING THE STEADY STATE SOLVER AND UNSTEADY or TRANSIENT SOLVER 2D HEAT CONDUCTION PROBLEM BY USINGGodwin LarryNo ratings yet
- TSR 9440 - Ruined KingdomsDocument128 pagesTSR 9440 - Ruined KingdomsJulien Noblet100% (15)
- Promotion of Coconut in The Production of YoghurtDocument4 pagesPromotion of Coconut in The Production of YoghurtԱբրենիկա ՖերլինNo ratings yet
- Study of Employees Performance Appraisal System in Hindustan Unilever LimitedDocument9 pagesStudy of Employees Performance Appraisal System in Hindustan Unilever LimitedSimranjitNo ratings yet
- Quadratic SDocument20 pagesQuadratic SAnubastNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziFrom Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNo ratings yet
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)From EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Rating: 5 out of 5 stars5/5 (5)
- Four Battlegrounds: Power in the Age of Artificial IntelligenceFrom EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceRating: 5 out of 5 stars5/5 (5)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)From EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Rating: 4 out of 5 stars4/5 (1)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeFrom EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeRating: 4.5 out of 5 stars4.5/5 (69)
- Artificial Intelligence & Generative AI for Beginners: The Complete GuideFrom EverandArtificial Intelligence & Generative AI for Beginners: The Complete GuideRating: 5 out of 5 stars5/5 (1)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet