You might also like
- Convolutional-Recursive Deep Learning For 3D Object Classif (R Socher) - NIPS 2012Document9 pagesConvolutional-Recursive Deep Learning For 3D Object Classif (R Socher) - NIPS 2012ervinonNo ratings yet
- Writer Recognition by Computer Vision: Jeffrey P. Woodard Christopher P. Saunders Mark J. LancasterDocument19 pagesWriter Recognition by Computer Vision: Jeffrey P. Woodard Christopher P. Saunders Mark J. LancasterRomario GlcNo ratings yet
- Handwritten English Character Recognition Using Neural NetworkDocument4 pagesHandwritten English Character Recognition Using Neural Networklavesh velipNo ratings yet
- Comparative Study Between Wavelet Contourlet Features Textural ClassificationDocument5 pagesComparative Study Between Wavelet Contourlet Features Textural ClassificationarjunNo ratings yet
- Presentation 2Document26 pagesPresentation 2kavi priyaNo ratings yet
- Comparison of Deep CNN and ResNet For Handwritten Devanagari Character RecognitionDocument4 pagesComparison of Deep CNN and ResNet For Handwritten Devanagari Character RecognitionsupravaNo ratings yet
- IJCSNS International Journal of Computer Science and Network Security, VOL.8Document6 pagesIJCSNS International Journal of Computer Science and Network Security, VOL.8activation12No ratings yet
- Paradigm Shift in Natural Language Processing: Tian-Xiang Sun Xiang-Yang Liu Xi-Peng Qiu Xuan-Jing HuangDocument15 pagesParadigm Shift in Natural Language Processing: Tian-Xiang Sun Xiang-Yang Liu Xi-Peng Qiu Xuan-Jing HuangNguyễn Thị Hồng NgátNo ratings yet
- 1397-Article Text-2587-1-10-20210406Document13 pages1397-Article Text-2587-1-10-20210406Aurangzaib BhattiNo ratings yet
- 2017 - Yingying - R2CNN-Rotational-Region-CNN-for-Orientation-Robust-Scene-Text-DetectionDocument8 pages2017 - Yingying - R2CNN-Rotational-Region-CNN-for-Orientation-Robust-Scene-Text-DetectionMai LamNo ratings yet
- An Improved K-Nearest Neighbor Algorithm and Its Application To High Resolution Remote Sensing Image ClassificationDocument4 pagesAn Improved K-Nearest Neighbor Algorithm and Its Application To High Resolution Remote Sensing Image ClassificationIndah Ayu DewantiNo ratings yet
- 2010 - Yanh - Supervised Translation-Invariant Sparse CodingDocument8 pages2010 - Yanh - Supervised Translation-Invariant Sparse CodingDaniel Prado de CamposNo ratings yet
- Feature CombinationsDocument5 pagesFeature Combinationssatishkumar697No ratings yet
- AI - (Deep Learning/NLP) : 5 DaysDocument4 pagesAI - (Deep Learning/NLP) : 5 DaysAmit SharmaNo ratings yet
- Dirichlet-Based Histogram Feature Transform For Image Classification CVPR2014Document8 pagesDirichlet-Based Histogram Feature Transform For Image Classification CVPR2014Hou BouNo ratings yet
- 5634 Convolutional Neural Networks With Intra Layer Recurrent Connections For Scene LabelingDocument9 pages5634 Convolutional Neural Networks With Intra Layer Recurrent Connections For Scene LabelingheavywaterNo ratings yet
- Bangla Handwritten Digit Recognition Using An Improved Deep Convolutional Neural Network ArchitectureDocument6 pagesBangla Handwritten Digit Recognition Using An Improved Deep Convolutional Neural Network ArchitectureTareque OviNo ratings yet
- CE571-DSM of FramesDocument22 pagesCE571-DSM of FramesAhmed MaherNo ratings yet
- Discrete Analytical Ridgelet TransformDocument28 pagesDiscrete Analytical Ridgelet Transformkd17209No ratings yet
- Linear Regression PDFDocument7 pagesLinear Regression PDFminkowski1987No ratings yet
- K SparseDocument9 pagesK SparseHarishwr KNo ratings yet
- Contour Analysis For Image Recognition in C# - CodeProjectDocument21 pagesContour Analysis For Image Recognition in C# - CodeProjectGerman IbarraNo ratings yet
- Politecnico Di Torino Repository ISTITUZIONALE: Loop Detection in Robotic Navigation Using MPEG CDVSDocument7 pagesPolitecnico Di Torino Repository ISTITUZIONALE: Loop Detection in Robotic Navigation Using MPEG CDVSraisin netsNo ratings yet
- Handwritten Isolated Bangla Compound Character Recognition: Asfi Fardous Shyla AfrogeDocument5 pagesHandwritten Isolated Bangla Compound Character Recognition: Asfi Fardous Shyla AfrogeTareque OviNo ratings yet
- Stellar Data Classification Using SVM With Wavelet TransformatioDocument6 pagesStellar Data Classification Using SVM With Wavelet TransformatioDRScienceNo ratings yet
- Politecnico Di Torino Repository ISTITUZIONALE: Loop Detection in Robotic Navigation Using MPEG CDVSDocument7 pagesPolitecnico Di Torino Repository ISTITUZIONALE: Loop Detection in Robotic Navigation Using MPEG CDVSPepe MNo ratings yet
- Comparison of Various Edge Detection Techniques Journal of Information and Operations ManagementDocument5 pagesComparison of Various Edge Detection Techniques Journal of Information and Operations ManagementNGUYEN KIETNo ratings yet
- Modes in Divergent Parabolic Graded-Index Optical Fibers: MemberDocument4 pagesModes in Divergent Parabolic Graded-Index Optical Fibers: MembersenthilNo ratings yet
- Electronics: An Algorithm For Natural Images Text Recognition Using Four Direction FeaturesDocument13 pagesElectronics: An Algorithm For Natural Images Text Recognition Using Four Direction FeaturesSiva ForeviewNo ratings yet
- Face Recognition Using Curvelet Based PCADocument4 pagesFace Recognition Using Curvelet Based PCAkd17209No ratings yet
- Theory Multiresolution Signal Decomposition: The Wavelet RepresentationDocument20 pagesTheory Multiresolution Signal Decomposition: The Wavelet RepresentationprincessdiaressNo ratings yet
- 1 s2.0 0167865596000517 MainDocument12 pages1 s2.0 0167865596000517 Mainmohammad khaleqiNo ratings yet
- DCT and KL TransformDocument26 pagesDCT and KL TransformMarzan Samin AshrafiNo ratings yet
- 04deconvolution Using Matlab Script To Identify Fault SealDocument11 pages04deconvolution Using Matlab Script To Identify Fault SealHerry SuhartomoNo ratings yet
- Swin Transformer V2: Scaling Up Capacity and ResolutionDocument11 pagesSwin Transformer V2: Scaling Up Capacity and ResolutionqwertyNo ratings yet
- Think Python 2Document35 pagesThink Python 2Yanquiel Mansfarroll GonzalezNo ratings yet
- Improving Bug Localization With Character-Level Convolutional Neural Network and Recurrent Neural NetworkDocument2 pagesImproving Bug Localization With Character-Level Convolutional Neural Network and Recurrent Neural NetworkNguyen Van ToanNo ratings yet
- A Region-Based Shape Descriptor Using Zernike Moments: Whoi-Yul Kim, Yong-Sung KimDocument8 pagesA Region-Based Shape Descriptor Using Zernike Moments: Whoi-Yul Kim, Yong-Sung KimSiviNo ratings yet
- MMSP SubmittedDocument7 pagesMMSP SubmittedShopnil SarkarNo ratings yet
- 3.2 Classification and Regression Models KNNDocument14 pages3.2 Classification and Regression Models KNNRajaNo ratings yet
- Zhou 2008Document5 pagesZhou 2008ilyes bensemmaneNo ratings yet
- Convolutional Neural Network With Data Augmentation For SAR Target RecognitionDocument5 pagesConvolutional Neural Network With Data Augmentation For SAR Target RecognitionS M RizviNo ratings yet
- Adaptive Local RegressionDocument10 pagesAdaptive Local Regressionvanessahoang001No ratings yet
- Research Article: Lower Order Krawtchouk Moment-Based Feature-Set For Hand Gesture RecognitionDocument11 pagesResearch Article: Lower Order Krawtchouk Moment-Based Feature-Set For Hand Gesture RecognitionGarima PantNo ratings yet
- Hypothesis Testing and Inform A Tion Theory: MutualDocument13 pagesHypothesis Testing and Inform A Tion Theory: Mutualandy briggerNo ratings yet
- Mullick 2018Document13 pagesMullick 2018EmilioNo ratings yet
- DL6 - Convnets 4Document57 pagesDL6 - Convnets 4razifa0No ratings yet
- Texture Based Land Cover Classification AlgorithmDocument7 pagesTexture Based Land Cover Classification AlgorithmAjan SenshilNo ratings yet
- 3 Optimization On Constrained Spectral ClusteringDocument7 pages3 Optimization On Constrained Spectral ClusteringAbel ThangarajaNo ratings yet
- EXP-9 To Determine The Material Fringe Constant Using Compression Method in TwoDocument3 pagesEXP-9 To Determine The Material Fringe Constant Using Compression Method in TwoSS-19-Devesh JaiswalNo ratings yet
- Under Water Image Enhancement Using Discrete Cosine TransformDocument4 pagesUnder Water Image Enhancement Using Discrete Cosine Transformanil kasotNo ratings yet
- Kami Export - 1904.01941Document5 pagesKami Export - 1904.01941asoedjfanushNo ratings yet
- Assignment 3Document8 pagesAssignment 3mohamedmariam490No ratings yet
- Classification of Diseased Arecanut Based On TextureDocument6 pagesClassification of Diseased Arecanut Based On TextureAnagha RangadholNo ratings yet
- 5.1.8 K-Nearest-Neighbor AlgorithmDocument8 pages5.1.8 K-Nearest-Neighbor Algorithmimran5705074No ratings yet
- Adaptive Learning-Based K-Nearest Neighbor Classifiers With Resilience To Class ImbalanceDocument17 pagesAdaptive Learning-Based K-Nearest Neighbor Classifiers With Resilience To Class ImbalanceAyushNo ratings yet
- Wavelet Convnets For Texture ClassificationDocument9 pagesWavelet Convnets For Texture ClassificationSachin PatilNo ratings yet
- 03 Image Formation 2Document64 pages03 Image Formation 2herusyahputraNo ratings yet
- Face Recognition Using Wavelet Based Kernel Locally Discriminating ProjectionDocument6 pagesFace Recognition Using Wavelet Based Kernel Locally Discriminating ProjectionPhanikumar SistlaNo ratings yet
- Introduction To Optical Character Recognition (OCR)Document29 pagesIntroduction To Optical Character Recognition (OCR)api-26462544No ratings yet
- Diagrams in The UMLDocument14 pagesDiagrams in The UMLapi-26462544No ratings yet
- Information System Design: Object-Oriented System TestingDocument22 pagesInformation System Design: Object-Oriented System Testingapi-26462544No ratings yet
- Scan OcrDocument17 pagesScan Ocrapi-26462544No ratings yet
- Information System Design: Statechart DiagramsDocument24 pagesInformation System Design: Statechart Diagramsapi-26462544No ratings yet
- Information System Design: Activity DiagramsDocument25 pagesInformation System Design: Activity Diagramsapi-26462544No ratings yet
- Information System Design: Unified Modeling LanguageDocument50 pagesInformation System Design: Unified Modeling Languageapi-26462544No ratings yet
- Communication Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument17 pagesCommunication Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Activity Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument18 pagesActivity Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Statechart Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument20 pagesStatechart Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Software Design: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument20 pagesSoftware Design: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Information System Design: Object-Oriented Design ParadigmsDocument51 pagesInformation System Design: Object-Oriented Design Paradigmsapi-26462544No ratings yet
- Sequence Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument16 pagesSequence Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Component Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument9 pagesComponent Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Deployment Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument9 pagesDeployment Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Use Cases: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument20 pagesUse Cases: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Package Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument8 pagesPackage Diagrams: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Composite Strutures: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - UkDocument6 pagesComposite Strutures: Massimo Felici Room 1402, JCMB, KB 0131 650 5899 Mfelici@inf - Ed.ac - Ukapi-26462544No ratings yet
- Information System Design: Interaction DiagramsDocument41 pagesInformation System Design: Interaction Diagramsapi-26462544No ratings yet
- American Panda Day 11 Lesson Condensed 2fadapted Eng482Document3 pagesAmerican Panda Day 11 Lesson Condensed 2fadapted Eng482api-296346559No ratings yet
- Summary Key ParameterDocument18 pagesSummary Key ParameterAndry JatmikoNo ratings yet
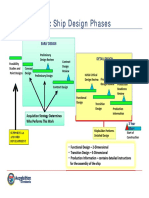
- Basic Ship Design PhasesDocument1 pageBasic Ship Design PhasesJhon GreigNo ratings yet
- D&D 5e Conditions Player ReferenceDocument1 pageD&D 5e Conditions Player ReferenceFrank Wilcox, Jr (fewilcox)No ratings yet
- Iso 21969 2009 en PDFDocument8 pagesIso 21969 2009 en PDFAnonymous P7J7V4No ratings yet
- First Russian Reader For Business Bilingual For Speakers of English Beginner Elementary (A1 A2)Document19 pagesFirst Russian Reader For Business Bilingual For Speakers of English Beginner Elementary (A1 A2)vadimznNo ratings yet
- VIOTEK Monitor ManualDocument11 pagesVIOTEK Monitor ManualJohn Michael V. LegasteNo ratings yet
- Platinum Collection v-22 Osprey ManualDocument24 pagesPlatinum Collection v-22 Osprey ManualP0wer3D100% (2)
- User Manual For Online EC With QR Code For Portal Users PDFDocument13 pagesUser Manual For Online EC With QR Code For Portal Users PDFkp pkNo ratings yet
- Lectut MI 106 PDF MI 106 Sol Tut 5 76vs9e5Document4 pagesLectut MI 106 PDF MI 106 Sol Tut 5 76vs9e5Pritam PaulNo ratings yet
- Is 7098 P-1 (1988) PDFDocument21 pagesIs 7098 P-1 (1988) PDFAmar PatwalNo ratings yet
- Syntel Mock 2Document18 pagesSyntel Mock 2Ashutosh MauryaNo ratings yet
- Pinhole Camera InformationDocument4 pagesPinhole Camera InformationD'ferti AnggraeniNo ratings yet
- AZ-Edit User ManualDocument288 pagesAZ-Edit User Manualdjjd40No ratings yet
- Process Safety BeaconDocument1 pageProcess Safety BeaconRaul tejadaNo ratings yet
- Hfe Panasonic Sa-Akx50 PH PN Service enDocument132 pagesHfe Panasonic Sa-Akx50 PH PN Service enJohntec nuñezNo ratings yet
- Performance Considerations Before Upgrading To Oracle 19c DatabaseDocument48 pagesPerformance Considerations Before Upgrading To Oracle 19c DatabaseJFLNo ratings yet
- G700 03 603333 1Document382 pagesG700 03 603333 1Jorge CruzNo ratings yet
- AssignmentDocument2 pagesAssignmentPhước ĐặngNo ratings yet
- Whitepaper InstallScape InternalsDocument4 pagesWhitepaper InstallScape InternalsKostas KalogeropoulosNo ratings yet
- ContainerDocument12 pagesContainerlakkekepsuNo ratings yet
- Coloumns & StrutsDocument14 pagesColoumns & StrutsWaseem AhmedNo ratings yet
- Sdhyper: "Make Difference, Make Better."Document2 pagesSdhyper: "Make Difference, Make Better."Juan Torres GamarraNo ratings yet
- Anthropometric MeasurementsDocument7 pagesAnthropometric MeasurementsMurti Putri UtamiNo ratings yet
- M 3094 (2013-06)Document17 pagesM 3094 (2013-06)Hatada FelipeNo ratings yet
- 752 BMW Individual High End Audio SystemDocument2 pages752 BMW Individual High End Audio SystemsteNo ratings yet
- GS-1930 GS-1530 Service Manual: Technical PublicationsDocument137 pagesGS-1930 GS-1530 Service Manual: Technical PublicationshabibullaNo ratings yet
- Culpeper County Water & Sewer Master Plan Compiled 2016-12-06 PDFDocument238 pagesCulpeper County Water & Sewer Master Plan Compiled 2016-12-06 PDFSuddhasattwa BandyopadhyayNo ratings yet
- OPA237Document21 pagesOPA237philprefNo ratings yet