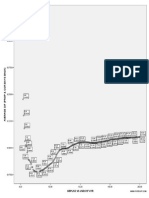
You might also like
- Exchange Rate Determination Puzzle: Long Run Behavior and Short Run DynamicsFrom EverandExchange Rate Determination Puzzle: Long Run Behavior and Short Run DynamicsNo ratings yet
- A New Approach To Modeling and Estimation For Pairs TradingDocument31 pagesA New Approach To Modeling and Estimation For Pairs Tradingneuromax74No ratings yet
- An Empirical Study of Price-Volume Relation: Contemporaneous Correlation and Dynamics Between Price Volatility and Trading Volume in the Hong Kong Stock Market.From EverandAn Empirical Study of Price-Volume Relation: Contemporaneous Correlation and Dynamics Between Price Volatility and Trading Volume in the Hong Kong Stock Market.No ratings yet
- Research On Modern Implications Of: Pairs TradingDocument23 pagesResearch On Modern Implications Of: Pairs Tradinggabriel_87No ratings yet
- Microscopic Simulation of Financial Markets: From Investor Behavior to Market PhenomenaFrom EverandMicroscopic Simulation of Financial Markets: From Investor Behavior to Market PhenomenaNo ratings yet
- Bayesian Markov Regime-Switching Models For CointeDocument6 pagesBayesian Markov Regime-Switching Models For CointeGavin RutledgeNo ratings yet
- Strategize Your Investment In 30 Minutes A Day (Steps)From EverandStrategize Your Investment In 30 Minutes A Day (Steps)No ratings yet
- Market Microstructure PDFDocument13 pagesMarket Microstructure PDFHarun Ahad100% (2)
- Manage Risk with Order TypesDocument31 pagesManage Risk with Order TypesChristian Nicolaus MbiseNo ratings yet
- Zero Hold Time - FAQs PDFDocument4 pagesZero Hold Time - FAQs PDFJorge LuisNo ratings yet
- Examination of High Frequency TradingDocument80 pagesExamination of High Frequency TradingChristopher TsaiNo ratings yet
- Maker TakerDocument50 pagesMaker TakerEduardo TocchettoNo ratings yet
- A Dynamic Model of The Limit Order Book: Ioanid Ros UDocument41 pagesA Dynamic Model of The Limit Order Book: Ioanid Ros Upinokio504No ratings yet
- Empirical Market MicrostructureDocument203 pagesEmpirical Market MicrostructureKonstantinos AngelidakisNo ratings yet
- High Frequency Market Making Model Analyzes Liquidity ProvisionDocument72 pagesHigh Frequency Market Making Model Analyzes Liquidity ProvisionIrfan SihabNo ratings yet
- Trading 101 BasicsDocument3 pagesTrading 101 BasicsNaveen KumarNo ratings yet
- Order Flow TradingDocument15 pagesOrder Flow TradingOUEDRAOGO RolandNo ratings yet
- Algo Trading Intro 2013 Steinki Session 8 PDFDocument21 pagesAlgo Trading Intro 2013 Steinki Session 8 PDFMichael ARKNo ratings yet
- Non Stationary Model For Statistical ArbitrageDocument17 pagesNon Stationary Model For Statistical ArbitrageWill BertramNo ratings yet
- GMMA Indicator ExplainedDocument6 pagesGMMA Indicator ExplainedJaime GuerreroNo ratings yet
- Algo Trading Case StudyDocument2 pagesAlgo Trading Case Studyreev011No ratings yet
- FX Arbitrage: Capturing Price Differences Across MarketsDocument1 pageFX Arbitrage: Capturing Price Differences Across MarketsKajal ChaudharyNo ratings yet
- Order FlowDocument71 pagesOrder FlowNguyen Anh QuanNo ratings yet
- Dispersion TradingDocument2 pagesDispersion TradingPuneet KinraNo ratings yet
- Pairs Trading G GRDocument31 pagesPairs Trading G GRSrinu BonuNo ratings yet
- OrderFlow Charts and Notes for Bank Nifty and Nifty Futures on 27th Sept 17Document12 pagesOrderFlow Charts and Notes for Bank Nifty and Nifty Futures on 27th Sept 17SinghRaviNo ratings yet
- Equivolume Charting RevisitedDocument12 pagesEquivolume Charting RevisitedBzasri RaoNo ratings yet
- IndicatorsDocument17 pagesIndicatorsEhsan RazaNo ratings yet
- The Application of Pairs Trading To Stock MarketsDocument31 pagesThe Application of Pairs Trading To Stock MarketsDadhich GunjanNo ratings yet
- StrategyQuant Help.3.6.1 PDFDocument130 pagesStrategyQuant Help.3.6.1 PDFenghoss77No ratings yet
- Trading Baskets ImplementationDocument44 pagesTrading Baskets ImplementationSanchit Gupta100% (1)
- OFTC Lesson 17 - Order Flow Continuation SetupsDocument24 pagesOFTC Lesson 17 - Order Flow Continuation SetupsThanhdat VoNo ratings yet
- PureDMA Manual IgmDocument12 pagesPureDMA Manual IgmMichelle RobertsNo ratings yet
- Limit Orders, Depth, and VolatilityDocument39 pagesLimit Orders, Depth, and VolatilitySamuel Martini CasagrandeNo ratings yet
- Limit Order Book Model For Latency ArbitrageDocument28 pagesLimit Order Book Model For Latency ArbitrageJong-Kwon LeeNo ratings yet
- MS&E448: Statistical Arbitrage: Group 5: Carolyn Soo, Zhengyi Lian, Jiayu Lou, Hang YangDocument31 pagesMS&E448: Statistical Arbitrage: Group 5: Carolyn Soo, Zhengyi Lian, Jiayu Lou, Hang Yang123No ratings yet
- What Is Position Delta - Options Trading Concept Guide - ProjectoptionDocument9 pagesWhat Is Position Delta - Options Trading Concept Guide - Projectoptionjose58No ratings yet
- Zones Trading StrateDocument15 pagesZones Trading StratePetter ZapataNo ratings yet
- Profitable Algorithmic Trading Strategies in Mean-Reverting MarketsDocument10 pagesProfitable Algorithmic Trading Strategies in Mean-Reverting MarketsdouglasNo ratings yet
- Sortino - A "Sharper" Ratio! - Red Rock CapitalDocument6 pagesSortino - A "Sharper" Ratio! - Red Rock CapitalInterconti Ltd.No ratings yet
- Price Action Higher Time Frame Day TradingDocument22 pagesPrice Action Higher Time Frame Day TradingjohnNo ratings yet
- D3 SpotterDocument5 pagesD3 SpotterMariafra AntonioNo ratings yet
- Trading Manual: Indicator OverviewDocument101 pagesTrading Manual: Indicator OverviewMrugenNo ratings yet
- Moving Average Convergence DivergenceDocument3 pagesMoving Average Convergence DivergenceNikita DubeyNo ratings yet
- Trading and SettlementDocument12 pagesTrading and SettlementLakhan KodiyatarNo ratings yet
- How To Trade Wyckoff For Beginners A-ZDocument3 pagesHow To Trade Wyckoff For Beginners A-ZCaser TOtNo ratings yet
- ITG Trading Around The Close 11-7-2012Document11 pagesITG Trading Around The Close 11-7-2012ej129No ratings yet
- Implied VolatilityDocument3 pagesImplied Volatilityrohit83No ratings yet
- Statistical Arbitrage Models of FTSE 100Document11 pagesStatistical Arbitrage Models of FTSE 100greg100% (20)
- Rubisov Anton 201511 MAS ThesisDocument94 pagesRubisov Anton 201511 MAS ThesisJose Antonio Dos RamosNo ratings yet
- Value and Momentum EverywhereDocument58 pagesValue and Momentum EverywhereDessy ParamitaNo ratings yet
- Trading and Market OrganizationsDocument183 pagesTrading and Market OrganizationsPham Minh Duc100% (1)
- Are Simple Momentum Strategies Too Dumb - Introducing Probabilistic Momentum - CSSADocument7 pagesAre Simple Momentum Strategies Too Dumb - Introducing Probabilistic Momentum - CSSAalexmorenoasuarNo ratings yet
- SDRC2 ORpostsDocument133 pagesSDRC2 ORpostsNg Tiong YewNo ratings yet
- Forex Correlation PeriodsDocument17 pagesForex Correlation Periodsneagucosmin100% (1)
- Confirm Market Direction Tick by Tick With: Order Flow +Document12 pagesConfirm Market Direction Tick by Tick With: Order Flow +Adolfo0% (2)
- High-frequency trading in a limit order book strategyDocument13 pagesHigh-frequency trading in a limit order book strategyKwok Chung ChuNo ratings yet
- Trade Score PDFDocument30 pagesTrade Score PDFvenkat.sqlNo ratings yet
- Causal Inference and Uplift Modeling A Review of The Literature (SURVEY) (2017)Document14 pagesCausal Inference and Uplift Modeling A Review of The Literature (SURVEY) (2017)ip01No ratings yet
- Closing The Gaps in Inertial Motion Tracking (MUSE - Magnitometer-Cenrtic Sensor Fusion) (Romit Roy Choudhury) (2018) (PPTX)Document60 pagesClosing The Gaps in Inertial Motion Tracking (MUSE - Magnitometer-Cenrtic Sensor Fusion) (Romit Roy Choudhury) (2018) (PPTX)ip01No ratings yet
- Optimal Personalized Treatment Rules For Marketing Interventions A Review of Methods, A New Proposal, and An Insurance Case Study (2014)Document35 pagesOptimal Personalized Treatment Rules For Marketing Interventions A Review of Methods, A New Proposal, and An Insurance Case Study (2014)ip01No ratings yet
- Metalearn2017 Giraud CarrierDocument32 pagesMetalearn2017 Giraud Carrierip01No ratings yet
- Pg148 Dsp48 MacroDocument34 pagesPg148 Dsp48 Macroip01No ratings yet
- Random Matrix Application To Correlations Among Volatility of AssetsDocument17 pagesRandom Matrix Application To Correlations Among Volatility of Assetsip01No ratings yet
- Sensing Vehicle Conditions For Detecting Driving Behaviors (2018) PDFDocument81 pagesSensing Vehicle Conditions For Detecting Driving Behaviors (2018) PDFip01No ratings yet
- My Complete Project B.com HONSDocument37 pagesMy Complete Project B.com HONSnitishmittal199067% (3)
- G.R. No. 176579Document6 pagesG.R. No. 176579Alee AbdulcalimNo ratings yet
- Bank Alpha Inventory Aaa Rated 15 Year Zero Coupon Bonds Fac Chapter 15 Problem 9qp Solution 9781259717772 ExcDocument1 pageBank Alpha Inventory Aaa Rated 15 Year Zero Coupon Bonds Fac Chapter 15 Problem 9qp Solution 9781259717772 ExcArihant patilNo ratings yet
- Top 10 service companiesDocument5 pagesTop 10 service companiesVishal PranavNo ratings yet
- Etisalat Annual Report 2008 PDFDocument1 pageEtisalat Annual Report 2008 PDFCharlotteNo ratings yet
- How Much Commission Mutual Fund Agent GetsDocument19 pagesHow Much Commission Mutual Fund Agent GetsjvmuruganNo ratings yet
- Dealpro Purpose Code List 190515Document8 pagesDealpro Purpose Code List 190515Sreenivas SungadiNo ratings yet
- Rosillo:61-64: 61) Pratts v. CADocument2 pagesRosillo:61-64: 61) Pratts v. CADiosa Mae SarillosaNo ratings yet
- 2nd Quarter Exam-1Document7 pages2nd Quarter Exam-1Alona Nay Calumpit AgcaoiliNo ratings yet
- Faugere Gold Required Yield TheoryDocument34 pagesFaugere Gold Required Yield TheoryZerohedgeNo ratings yet
- Letter of Intent TemplateDocument6 pagesLetter of Intent TemplateIan Gianam100% (2)
- Chapter 18Document21 pagesChapter 18BarakaNo ratings yet
- SAP VAT For GCC CountryDocument16 pagesSAP VAT For GCC CountryEdith Yit50% (2)
- Pioneers and Soldiers CemeteryDocument4 pagesPioneers and Soldiers CemeterySenateDFLNo ratings yet
- Corporate FinanceDocument8 pagesCorporate FinanceArijit BhattacharyaNo ratings yet
- ReadmeDocument5 pagesReadmeKamala KannanNo ratings yet
- ACCTBA1 - Exercises On Adjusting EntriesDocument5 pagesACCTBA1 - Exercises On Adjusting EntriesRichard Leighton100% (1)
- Msci KLD 400 Social IndexDocument2 pagesMsci KLD 400 Social IndexJose Pinto de AbreuNo ratings yet
- Lombard Risk - Regulation in HONG KONGDocument3 pagesLombard Risk - Regulation in HONG KONGLombard RiskNo ratings yet
- Financial Planning & Wealth Management: Sunder Ram Korivi, National Institute of Securities Markets, Navi MumbaiDocument20 pagesFinancial Planning & Wealth Management: Sunder Ram Korivi, National Institute of Securities Markets, Navi MumbaijayaNo ratings yet
- NSE DerivativesDocument7 pagesNSE DerivativesVivek MishraNo ratings yet
- NTEGRATOR Lodgement AnnouncementDocument1 pageNTEGRATOR Lodgement AnnouncementInvest StockNo ratings yet
- ContractsDocument21 pagesContractsAditi SoniNo ratings yet
- Government Accounting and AuditingDocument190 pagesGovernment Accounting and AuditingCharles John Palabrica CubarNo ratings yet
- Chapter 14 - Managing Foreign Exchange RiskDocument19 pagesChapter 14 - Managing Foreign Exchange RiskFami FamzNo ratings yet
- Final 9Document38 pagesFinal 9Tishina SeewoosahaNo ratings yet
- Notice of Maritime Lien ClaimDocument1 pageNotice of Maritime Lien ClaimRohan Moxley100% (1)
- Bill of exchange, promissory note and cheque regulationsDocument10 pagesBill of exchange, promissory note and cheque regulationsThéotime HabinezaNo ratings yet
- United States v. Robert A. Barbato, 471 F.2d 918, 1st Cir. (1973)Document5 pagesUnited States v. Robert A. Barbato, 471 F.2d 918, 1st Cir. (1973)Scribd Government DocsNo ratings yet
- SCIENTIFIC STORECASTING OR LARGE PROFITS ON SMALL RISKSDocument15 pagesSCIENTIFIC STORECASTING OR LARGE PROFITS ON SMALL RISKSSirrudramahasanjeevani Dhyanparihar YagnaNo ratings yet
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 5 out of 5 stars5/5 (2)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Calculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusFrom EverandCalculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusRating: 4.5 out of 5 stars4.5/5 (2)
- Psychology Behind Mathematics - The Comprehensive GuideFrom EverandPsychology Behind Mathematics - The Comprehensive GuideNo ratings yet
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathFrom EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathRating: 5 out of 5 stars5/5 (1)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- Math Magic: How To Master Everyday Math ProblemsFrom EverandMath Magic: How To Master Everyday Math ProblemsRating: 3.5 out of 5 stars3.5/5 (15)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceFrom EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceNo ratings yet
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)
- Assessment Prep for Common Core Mathematics, Grade 6From EverandAssessment Prep for Common Core Mathematics, Grade 6Rating: 5 out of 5 stars5/5 (1)