You might also like
- Chapter4 Regression ModelAdequacyCheckingDocument38 pagesChapter4 Regression ModelAdequacyCheckingAishat OmotolaNo ratings yet
- Kruskal 1964bDocument15 pagesKruskal 1964byismar farith mosquera mosqueraNo ratings yet
- Partial Inverse Regression: Biometrika (2007), 94, 3, Pp. 615-625 Printed in Great BritainDocument12 pagesPartial Inverse Regression: Biometrika (2007), 94, 3, Pp. 615-625 Printed in Great BritainLiliana ForzaniNo ratings yet
- Quasi-Random Sequences and Their DiscrepanciesDocument44 pagesQuasi-Random Sequences and Their Discrepanciesabc010No ratings yet
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- On Orthogonal Polynomials in Several Variables: Fields Institute Communications Volume 00, 0000Document23 pagesOn Orthogonal Polynomials in Several Variables: Fields Institute Communications Volume 00, 0000Terwal Aandrés Oortiz VargasNo ratings yet
- Chp2 LinalgDocument8 pagesChp2 LinalgLucas KevinNo ratings yet
- Measure and Integration NotesDocument93 pagesMeasure and Integration NotessebastianavinaNo ratings yet
- Linear Regression Analysis: Module - IvDocument10 pagesLinear Regression Analysis: Module - IvupenderNo ratings yet
- S. Catterall Et Al - Baby Universes in 4d Dynamical TriangulationDocument9 pagesS. Catterall Et Al - Baby Universes in 4d Dynamical TriangulationGijke3No ratings yet
- Regression Analysis - Chapter 4 - Model Adequacy Checking - Shalabh, IIT KanpurDocument36 pagesRegression Analysis - Chapter 4 - Model Adequacy Checking - Shalabh, IIT KanpurAbcNo ratings yet
- 05 AbstractsDocument24 pages05 AbstractsMukta DebnathNo ratings yet
- Analysis of A Complex of Statistical Variables Into Principal ComponentsDocument25 pagesAnalysis of A Complex of Statistical Variables Into Principal ComponentsAhhhhhhhNo ratings yet
- 2011 ARML Advanced Combinatorics - Principle of Inclusion-ExclusionDocument4 pages2011 ARML Advanced Combinatorics - Principle of Inclusion-ExclusionAman MachraNo ratings yet
- Applications of Linear Models in Animal Breeding Henderson-1984Document385 pagesApplications of Linear Models in Animal Breeding Henderson-1984DiegoPagungAmbrosiniNo ratings yet
- Laplace Equations and The Weak Lefschetz ( (2012)Document21 pagesLaplace Equations and The Weak Lefschetz ( (2012)Matemáticas AsesoriasNo ratings yet
- Chapter-9-Simple Linear Regression & CorrelationDocument11 pagesChapter-9-Simple Linear Regression & CorrelationAyu AlemuNo ratings yet
- Aims ThesisDocument43 pagesAims ThesisNoyiessie Ndebeka RostantNo ratings yet
- Operations ResearchDocument37 pagesOperations ResearchShashank BadkulNo ratings yet
- On Contrastive Divergence LearningDocument8 pagesOn Contrastive Divergence Learningkorn651No ratings yet
- Asymptotic Analysis NotesDocument36 pagesAsymptotic Analysis NotesmihuangNo ratings yet
- Data Reduction or Structural SimplificationDocument44 pagesData Reduction or Structural SimplificationDaraaraa MulunaaNo ratings yet
- Chapter 4Document68 pagesChapter 4Nhatty WeroNo ratings yet
- Probability DistributionsDocument29 pagesProbability DistributionsPranav MishraNo ratings yet
- Primera ClaseDocument48 pagesPrimera ClaseLino Ccarhuaypiña ContrerasNo ratings yet
- Multivariate Statistical Analysis: The Multivariate Normal DistributionDocument13 pagesMultivariate Statistical Analysis: The Multivariate Normal DistributionGenesis Carrillo GranizoNo ratings yet
- Solving Systems of Algebraic Equations: Daniel LazardDocument27 pagesSolving Systems of Algebraic Equations: Daniel LazardErwan Christo Shui 廖No ratings yet
- CS 717: EndsemDocument5 pagesCS 717: EndsemGanesh RamakrishnanNo ratings yet
- Statistical ApplicationDocument18 pagesStatistical ApplicationArqam AbdulaNo ratings yet
- Uniqueness and Multiplicity of Infinite ClustersDocument13 pagesUniqueness and Multiplicity of Infinite Clusterskavv1No ratings yet
- An Introduction To FractalsDocument25 pagesAn Introduction To FractalsDimitar DobrevNo ratings yet
- Analysis of Quaternions Components in Algorithms of Attitude. A Simple Computational Solution For The Problem of Duality in The Results.Document16 pagesAnalysis of Quaternions Components in Algorithms of Attitude. A Simple Computational Solution For The Problem of Duality in The Results.Leandro CamposNo ratings yet
- On Systems of Linear Diophantine Equations PDFDocument6 pagesOn Systems of Linear Diophantine Equations PDFhumejiasNo ratings yet
- Advanced Problem Solving Lecture Notes and Problem Sets: Peter Hästö Torbjörn Helvik Eugenia MalinnikovaDocument35 pagesAdvanced Problem Solving Lecture Notes and Problem Sets: Peter Hästö Torbjörn Helvik Eugenia Malinnikovaసతీష్ కుమార్No ratings yet
- 69813Document16 pages69813Edu Merino ArbietoNo ratings yet
- MAE 300 TextbookDocument95 pagesMAE 300 Textbookmgerges15No ratings yet
- A Course of Mathematics for Engineers and Scientists: Volume 1From EverandA Course of Mathematics for Engineers and Scientists: Volume 1No ratings yet
- Tverberg's Theorem Is 50 Years Old: A Survey: Imre B Ar Any Pablo Sober OnDocument2 pagesTverberg's Theorem Is 50 Years Old: A Survey: Imre B Ar Any Pablo Sober OnZygmund BaumanNo ratings yet
- Legendre PolynomialsDocument7 pagesLegendre Polynomialsbraulio.dantas0% (1)
- Intersection Theory - Valentina KiritchenkoDocument18 pagesIntersection Theory - Valentina KiritchenkoHoracio CastellanosNo ratings yet
- Midterm 1 ReviewDocument4 pagesMidterm 1 ReviewJovan WhiteNo ratings yet
- Data Analysis: Measures of DispersionDocument6 pagesData Analysis: Measures of DispersionAadel SepahNo ratings yet
- Metric Spaces and Complex AnalysisDocument120 pagesMetric Spaces and Complex AnalysisMayank KumarNo ratings yet
- Pattern Separation and Prediction Via Linear and Semidefinite ProgrammingDocument16 pagesPattern Separation and Prediction Via Linear and Semidefinite Programmingrupaj_n954No ratings yet
- Least Squares EllipsoidDocument17 pagesLeast Squares EllipsoidJoco Franz AmanoNo ratings yet
- Mathematical FinanceDocument13 pagesMathematical FinanceAlpsNo ratings yet
- Unsolved ProblemsDocument3 pagesUnsolved ProblemsStephan BaltzerNo ratings yet
- Discrete and Continuous Dynamical Systems Volume 33, Number 6, June 2013Document17 pagesDiscrete and Continuous Dynamical Systems Volume 33, Number 6, June 2013Cras JorchilNo ratings yet
- Ojection Estimation in Multiple Regression With Application To Functional AnovaDocument31 pagesOjection Estimation in Multiple Regression With Application To Functional AnovaFrank LiuNo ratings yet
- Thisyear PDFDocument112 pagesThisyear PDFegeun mankdNo ratings yet
- Probability PresentationDocument26 pagesProbability PresentationNada KamalNo ratings yet
- Random MatricesDocument27 pagesRandom MatricesolenobleNo ratings yet
- Inequalitty Ky FanDocument15 pagesInequalitty Ky FanhungkgNo ratings yet
- Lesson Plan PPT (Ict in Math)Document23 pagesLesson Plan PPT (Ict in Math)Jennifer EugenioNo ratings yet
- Mathematics Promotional Exam Cheat SheetDocument8 pagesMathematics Promotional Exam Cheat SheetAlan AwNo ratings yet
- Ols 2Document19 pagesOls 2sanamdadNo ratings yet
- Experiment 1Document11 pagesExperiment 1Aimee RarugalNo ratings yet
- Module 2 in IStat 1 Probability DistributionDocument6 pagesModule 2 in IStat 1 Probability DistributionJefferson Cadavos CheeNo ratings yet
- Banyay, Irene Kardos-The History of The Hungarian MusicDocument301 pagesBanyay, Irene Kardos-The History of The Hungarian MusicwaldemarclausNo ratings yet
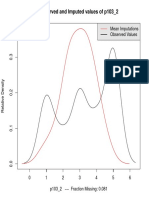
- Observed and Imputed Values of p103 - 2Document1 pageObserved and Imputed Values of p103 - 2waldemarclausNo ratings yet
- Handbook On Prisons. Willan Publishing, Collumpton: 471-495Document2 pagesHandbook On Prisons. Willan Publishing, Collumpton: 471-495waldemarclausNo ratings yet
- Chambliss StateorgcrimeDocument26 pagesChambliss StateorgcrimewaldemarclausNo ratings yet
- Crime Handbook Final PDFDocument62 pagesCrime Handbook Final PDFwaldemarclausNo ratings yet
- Illegal Markets Protection Rackets and O PDFDocument19 pagesIllegal Markets Protection Rackets and O PDFwaldemarclausNo ratings yet
- A Brief Introduction To Factor AnalysisDocument12 pagesA Brief Introduction To Factor AnalysiswaldemarclausNo ratings yet
- Tait CareandtheprisonDocument9 pagesTait CareandtheprisonwaldemarclausNo ratings yet
- Moe-The Positive Theory of Public BureaucracyDocument14 pagesMoe-The Positive Theory of Public BureaucracywaldemarclausNo ratings yet
- Staff Prisoner Relations WhitemoorDocument201 pagesStaff Prisoner Relations WhitemoorwaldemarclausNo ratings yet
- 6 F608 D 01Document64 pages6 F608 D 01waldemarclausNo ratings yet
- Managing The Dilemma: Occupational Culture and Identity Among Prison OfficersDocument1 pageManaging The Dilemma: Occupational Culture and Identity Among Prison OfficerswaldemarclausNo ratings yet
- Assignment 2Document2 pagesAssignment 2Ben ReichNo ratings yet
- Assignment 1 PDFDocument6 pagesAssignment 1 PDFSudarshan KuntumallaNo ratings yet
- Matrices PDFDocument31 pagesMatrices PDFCHAITANYA KNo ratings yet
- Controls Exit OTDocument13 pagesControls Exit OTJeffrey Wenzen AgbuyaNo ratings yet
- Linear VectorDocument36 pagesLinear VectorNirajan PandeyNo ratings yet
- B Sc-MathsDocument24 pagesB Sc-MathsVijayakumar KopNo ratings yet
- DeltaDocument81 pagesDeltaAmit MandalNo ratings yet
- Xica Bca Sem IDocument30 pagesXica Bca Sem IPrasanna Kumar DasNo ratings yet
- Matriks Simetri, Diagonal Dan SegitigaDocument11 pagesMatriks Simetri, Diagonal Dan SegitigaDieky AdzkiyaNo ratings yet
- A Review On The Inverse of Symmetric Tridiagonal and Block Tridiagonal MatricesDocument22 pagesA Review On The Inverse of Symmetric Tridiagonal and Block Tridiagonal MatricesTadiyos Hailemichael MamoNo ratings yet
- Chapterwise A' Level Questions: By: OP GUPTA (+91-9650 350 480) For Class XiiDocument16 pagesChapterwise A' Level Questions: By: OP GUPTA (+91-9650 350 480) For Class XiiharshilNo ratings yet
- Holiday Homework Class Xii MathDocument4 pagesHoliday Homework Class Xii Mathmanish kumarNo ratings yet
- 12 SQP CH 4Document3 pages12 SQP CH 4vivinsam786No ratings yet
- Maths 1A - Chapter Wise Important Questions PDFDocument27 pagesMaths 1A - Chapter Wise Important Questions PDFSk Javid0% (1)
- Novel Shannon Graph Entropy, Capacity: Spectral Graph TheoryDocument16 pagesNovel Shannon Graph Entropy, Capacity: Spectral Graph Theoryvanaj123No ratings yet
- Matrices That Commute With Their Conjugate and Transpose: Geoffrey GoodsonDocument4 pagesMatrices That Commute With Their Conjugate and Transpose: Geoffrey GoodsonJade Bong NatuilNo ratings yet
- P3 Maths MCQDocument25 pagesP3 Maths MCQMd. Sohail RazaNo ratings yet
- Maths Class Xii Sample Paper Test 02 For Board Exam 2023Document6 pagesMaths Class Xii Sample Paper Test 02 For Board Exam 2023Priyanshu KasanaNo ratings yet
- Maths PDF 2Document140 pagesMaths PDF 2tharunvara000No ratings yet
- Lecture No. 13Document11 pagesLecture No. 13Sujat AliNo ratings yet
- Nicholson Solution For Linear Algebra 7th Edition.Document194 pagesNicholson Solution For Linear Algebra 7th Edition.Peter Li60% (5)
- Supplementary MaterialsDocument38 pagesSupplementary Materials陳楷翰No ratings yet
- Hadamard Matrix Analysis and Synthesis With Applications To Communications and Signal Image ProcessingDocument119 pagesHadamard Matrix Analysis and Synthesis With Applications To Communications and Signal Image ProcessingEmerson MaucaNo ratings yet
- Homework1 SolutionsDocument3 pagesHomework1 SolutionsDominic LombardiNo ratings yet
- Chapter 2Document30 pagesChapter 2MengHan LeeNo ratings yet
- Shifting MethodDocument9 pagesShifting MethodSerkan SancakNo ratings yet
- Basic Linear AlgebraDocument268 pagesBasic Linear AlgebraAhmet DoğanNo ratings yet
- EEE I & IV Year R09Document107 pagesEEE I & IV Year R09Sravan GuptaNo ratings yet
- Advanced Level Questions Class-12Document16 pagesAdvanced Level Questions Class-12jitender8No ratings yet
- Class-12-Maths-Important Short Answer Type Questions Chapter-3Document14 pagesClass-12-Maths-Important Short Answer Type Questions Chapter-3Hf vgvvv Vg vNo ratings yet