You might also like
- 05 HWDocument3 pages05 HWSandipChowdhuryNo ratings yet
- MIPS FSM Diagram!: Cycle 1!Document1 pageMIPS FSM Diagram!: Cycle 1!SandipChowdhuryNo ratings yet
- MIPS Datapath (With Exception Handling) !Document1 pageMIPS Datapath (With Exception Handling) !SandipChowdhuryNo ratings yet
- CSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsDocument8 pagesCSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsSandipChowdhuryNo ratings yet
- Lectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"Document30 pagesLectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"SandipChowdhuryNo ratings yet
- CSE 30321: Computer Architecture I: LogisticsDocument3 pagesCSE 30321: Computer Architecture I: LogisticsSandipChowdhuryNo ratings yet
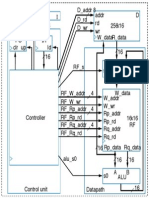
- Control Unit and Datapath For 3-Instruction Processor!Document1 pageControl Unit and Datapath For 3-Instruction Processor!SandipChowdhuryNo ratings yet
- From: Subject: Date: To: Reply-ToDocument1 pageFrom: Subject: Date: To: Reply-ToSandipChowdhuryNo ratings yet
- 1HDocument8 pages1HSandipChowdhuryNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Kristian Tlangau - November, 2016 PDFDocument52 pagesKristian Tlangau - November, 2016 PDFMizoram Presbyterian Church SynodNo ratings yet
- Comparison Between Six-Stroke and Four-Stroke EngineDocument15 pagesComparison Between Six-Stroke and Four-Stroke EnginefaizanbasharatNo ratings yet
- 4455770110e1 Parts ManualDocument31 pages4455770110e1 Parts ManualSimon AlbertNo ratings yet
- White BoxDocument9 pagesWhite BoxAmitsonu222No ratings yet
- Broaching PrsDocument41 pagesBroaching PrsParag PatelNo ratings yet
- Kobelco 30SR Service ManualDocument6 pagesKobelco 30SR Service ManualG NEELAKANDANNo ratings yet
- 8 Candidate Quiz Buzzer Using 8051Document33 pages8 Candidate Quiz Buzzer Using 8051prasadzeal0% (1)
- Whose Online Video Lectures Are Best For The IIT JEE?Document6 pagesWhose Online Video Lectures Are Best For The IIT JEE?Buzz PriyanshuNo ratings yet
- Vestron VideoDocument3 pagesVestron VideoMIDNITECAMPZNo ratings yet
- Harga Jual Genset Deutz GermanyDocument2 pagesHarga Jual Genset Deutz GermanyAgung SetiawanNo ratings yet
- Oracle Secure BackupDocument294 pagesOracle Secure BackupCarlos ValderramaNo ratings yet
- How To Size Hydropneumatic TankDocument3 pagesHow To Size Hydropneumatic TankfelipeNo ratings yet
- Lab 7Document12 pagesLab 7api-25252422380% (5)
- 2012-02-29 An Introduction To OptimizationDocument4 pages2012-02-29 An Introduction To OptimizationSam ShahNo ratings yet
- Basement Masonry Wall Design Based On TMS 402-16/13: Input Data & Design SummaryDocument2 pagesBasement Masonry Wall Design Based On TMS 402-16/13: Input Data & Design SummaryRidho ZiskaNo ratings yet
- A Modified Vince Gingery PlasticDocument13 pagesA Modified Vince Gingery PlasticgeppaNo ratings yet
- Energy Cable Accessories Epp1984 EngDocument156 pagesEnergy Cable Accessories Epp1984 EngSathiyanathan ManiNo ratings yet
- Namibian Diplomatic Missions Abroad 2011Document6 pagesNamibian Diplomatic Missions Abroad 2011Milton LouwNo ratings yet
- Nessus 6.3 Installation GuideDocument109 pagesNessus 6.3 Installation GuideminardmiNo ratings yet
- Capitulo 9 - Flujo de DatosDocument24 pagesCapitulo 9 - Flujo de DatosOrlando Espinoza ZevallosNo ratings yet
- BOB SO Information HandoutDocument5 pagesBOB SO Information HandoutKabya SrivastavaNo ratings yet
- 15mm K115 GW-S CUP STD (SH005 1014 B)Document2 pages15mm K115 GW-S CUP STD (SH005 1014 B)Ionut BucurNo ratings yet
- Ne40 Ne80 PDFDocument192 pagesNe40 Ne80 PDFณัชชา ธนปัญจาภรณ์No ratings yet
- Econ 103 - 01Document3 pagesEcon 103 - 01perrerNo ratings yet
- PESTLE Analysis Patanjali Ayurved LTDDocument7 pagesPESTLE Analysis Patanjali Ayurved LTDvaidehi50% (2)
- Regional VP Sales Director in USA Resume Margo PappDocument2 pagesRegional VP Sales Director in USA Resume Margo PappMargoPappNo ratings yet
- Telenor Organization Structure and CultureDocument29 pagesTelenor Organization Structure and CultureAli Farooqui85% (20)
- Fit-Up Piping B192-5-S2Document22 pagesFit-Up Piping B192-5-S2Prathamesh OmtechNo ratings yet
- Experiment No.7 Study of Disc Pelletizer: ObjectivesDocument4 pagesExperiment No.7 Study of Disc Pelletizer: ObjectivesPrafulla Subhash SarodeNo ratings yet
- The Impact of Internet Use For StudentsDocument8 pagesThe Impact of Internet Use For StudentsCharlesNo ratings yet