You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Discrete Choice Modeling: William Greene Stern School of Business New York UniversityDocument25 pagesDiscrete Choice Modeling: William Greene Stern School of Business New York UniversityJayita ChakrabortyNo ratings yet
- Nonlinear Spatial ModelsDocument103 pagesNonlinear Spatial ModelsJayita ChakrabortyNo ratings yet
- Book Reviews: Journal of Urban TechnologyDocument10 pagesBook Reviews: Journal of Urban TechnologyJayita ChakrabortyNo ratings yet
- Guidelines Preparing DMFDocument56 pagesGuidelines Preparing DMFJayita ChakrabortyNo ratings yet
- Building Singapore'S Mass Rapid Transit System-Some Systemic LessonsDocument9 pagesBuilding Singapore'S Mass Rapid Transit System-Some Systemic LessonsJayita ChakrabortyNo ratings yet
- Survey Map ModelDocument1 pageSurvey Map ModelJayita ChakrabortyNo ratings yet
- DCEDocument47 pagesDCEkhalid joiaNo ratings yet
- Uber: Minimizing ETA: Anna Juchnicki Sasha Sklyarenko Christina Nguyen Faith YuDocument16 pagesUber: Minimizing ETA: Anna Juchnicki Sasha Sklyarenko Christina Nguyen Faith YuJayita ChakrabortyNo ratings yet
- Planning Norms Uk 20-01-14Document13 pagesPlanning Norms Uk 20-01-14Jayita ChakrabortyNo ratings yet
- The Implications of Housing Density: Force, Chaired by Leading Architect Richard Rogers, Was Appointed To ConsiderDocument8 pagesThe Implications of Housing Density: Force, Chaired by Leading Architect Richard Rogers, Was Appointed To ConsiderSingleAspectNo ratings yet
- The Development of A Strategy For The Implementation of Adaptability in Building StructuresDocument5 pagesThe Development of A Strategy For The Implementation of Adaptability in Building StructuresJayita ChakrabortyNo ratings yet
- Fls 1146Document10 pagesFls 1146Jayita ChakrabortyNo ratings yet
- Development As FreedomDocument17 pagesDevelopment As Freedomm935513No ratings yet
- ILO WP 2012 AhmedabadDocument68 pagesILO WP 2012 AhmedabadJayita ChakrabortyNo ratings yet
- Economics For Democratic Socialism: Drexel University Spring Quarter 2009Document55 pagesEconomics For Democratic Socialism: Drexel University Spring Quarter 2009Jayita ChakrabortyNo ratings yet
- Urban Goods Movement Modelling For India CitiesDocument63 pagesUrban Goods Movement Modelling For India CitiesJayita ChakrabortyNo ratings yet
- Research Proposal - Citizenship in IndiaDocument7 pagesResearch Proposal - Citizenship in IndiaJayita ChakrabortyNo ratings yet
- Architect's Act, 1972Document18 pagesArchitect's Act, 1972Hananeel SandhiNo ratings yet
- Bitwise Operator StructuresDocument6 pagesBitwise Operator StructuresrajuhdNo ratings yet
- Chapter Test 2 ReviewDocument23 pagesChapter Test 2 ReviewSheila Mae AsuelaNo ratings yet
- Sensex 1Document354 pagesSensex 1raghav4life8724No ratings yet
- ME 171 SyllabusDocument7 pagesME 171 SyllabusLucas Penalva Costa SerraNo ratings yet
- Cost Optimization of Post-Tensioned I-GirderDocument5 pagesCost Optimization of Post-Tensioned I-GirderPUENTES2407No ratings yet
- Mangaldan Distric Ii Pogo-Palua Elementary School: ND RDDocument3 pagesMangaldan Distric Ii Pogo-Palua Elementary School: ND RDFlordeliza Manaois RamosNo ratings yet
- Measuring Inequality: An Introduction to Concepts and MeasuresDocument255 pagesMeasuring Inequality: An Introduction to Concepts and MeasuresNaresh SehdevNo ratings yet
- EGA Revisited: Key Concepts in Grothendieck's Foundational WorkDocument50 pagesEGA Revisited: Key Concepts in Grothendieck's Foundational WorkTomás CampoNo ratings yet
- Mathematics Curriculum in MalaysiaDocument38 pagesMathematics Curriculum in MalaysiaSK Lai100% (1)
- English Task For 11th GradeDocument8 pagesEnglish Task For 11th GradeDevi NurulhudaNo ratings yet
- Automata and Quantum ComputingDocument34 pagesAutomata and Quantum ComputingJorge LeandroNo ratings yet
- CE6306 NotesDocument125 pagesCE6306 Noteskl42c4300No ratings yet
- IT-Glossary French - EnglishDocument56 pagesIT-Glossary French - EnglishGosia SielickaNo ratings yet
- 0606 MW Otg MS P11Document8 pages0606 MW Otg MS P11Yu Yan ChanNo ratings yet
- Ejercicos Mentales Volumen 13Document10 pagesEjercicos Mentales Volumen 13Luis TorresNo ratings yet
- Rr210501 Discrete Structures and Graph TheoryDocument6 pagesRr210501 Discrete Structures and Graph TheorySrinivasa Rao GNo ratings yet
- On The Static Solutions in Gravity With Massive Scalar Field in Three DimensionsDocument11 pagesOn The Static Solutions in Gravity With Massive Scalar Field in Three DimensionsMojeime Igor NowakNo ratings yet
- HuwDocument12 pagesHuwCharles MorganNo ratings yet
- 9789533073248UWBTechnologiesDocument454 pages9789533073248UWBTechnologiesConstantin PişteaNo ratings yet
- Statistics___Probability_Q3__Answer_Sheet___1_.pdfDocument53 pagesStatistics___Probability_Q3__Answer_Sheet___1_.pdfJohn Michael BerteNo ratings yet
- 1-15-15 Kinematics AP1 - Review SetDocument8 pages1-15-15 Kinematics AP1 - Review SetLudwig Van Beethoven100% (1)
- 6 Noise and Multiple Attenuation PDFDocument164 pages6 Noise and Multiple Attenuation PDFFelipe CorrêaNo ratings yet
- Chapter 3. Drag Force and Its CoefficientDocument47 pagesChapter 3. Drag Force and Its Coefficientsmyeganeh100% (1)
- Multi-Objective Optimization For Football Team Member SelectionDocument13 pagesMulti-Objective Optimization For Football Team Member SelectionSezim Tokozhan kyzyNo ratings yet
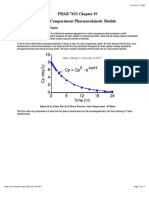
- PHAR 7633 Chapter 19 Multi-Compartment Pharmacokinetic ModelsDocument23 pagesPHAR 7633 Chapter 19 Multi-Compartment Pharmacokinetic ModelsBandameedi RamuNo ratings yet
- Unit 2. Error and The Treatment of Analytical Data: (1) Systematic Error or Determinate ErrorDocument6 pagesUnit 2. Error and The Treatment of Analytical Data: (1) Systematic Error or Determinate ErrorKamran JalilNo ratings yet
- Midterm & Final ExamDocument2 pagesMidterm & Final ExambcanturkyilmazNo ratings yet
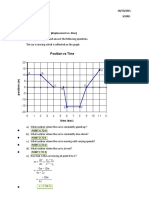
- Day 2.1 Activity 3 Jemar Wasquin.Document5 pagesDay 2.1 Activity 3 Jemar Wasquin.Jemar WasquinNo ratings yet
- Solving Problems by Searching: Artificial IntelligenceDocument43 pagesSolving Problems by Searching: Artificial IntelligenceDai TrongNo ratings yet
- 01 Dee1012 Topic 1Document52 pages01 Dee1012 Topic 1norzamira100% (1)