Professional Documents
Culture Documents
Bear
Uploaded by
hilifemx000 ratings0% found this document useful (0 votes)
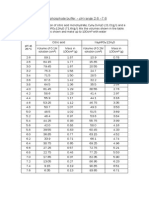
65 views109 pagesAn average bioequivalence (ABE) and bioavailability data analysis tool including sample size estimation, noncompartmental analysis (NCA) for a standard RT / TR 2x2x2 crossover design or a parallel study. Package 'bear' May 28, 2010 Version 2.5.
Original Description:
Copyright
© © All Rights Reserved
Available Formats
PDF, TXT or read online from Scribd
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentAn average bioequivalence (ABE) and bioavailability data analysis tool including sample size estimation, noncompartmental analysis (NCA) for a standard RT / TR 2x2x2 crossover design or a parallel study. Package 'bear' May 28, 2010 Version 2.5.
Copyright:
© All Rights Reserved
Available Formats
Download as PDF, TXT or read online from Scribd
0 ratings0% found this document useful (0 votes)
65 views109 pagesBear
Uploaded by
hilifemx00An average bioequivalence (ABE) and bioavailability data analysis tool including sample size estimation, noncompartmental analysis (NCA) for a standard RT / TR 2x2x2 crossover design or a parallel study. Package 'bear' May 28, 2010 Version 2.5.
Copyright:
© All Rights Reserved
Available Formats
Download as PDF, TXT or read online from Scribd
You are on page 1of 109
Package bear
May 28, 2010
Version 2.5.2
Date 2010-05-31
Title Average bioequivalence and bioavailability data analysis tool
Author Hsin-ya Lee, Yung-jin Lee
Maintainer Yung-jin Lee <mobilePK@gmail.com>
Depends R (>= 2.10.0), reshape, nlme, sciplot, plotrix, ICSNP, gdata
Description An average bioequivalence (ABE) and bioavailability data analysis tool including sample
size estimation, noncompartmental analysis (NCA), ANOVA (lm) for a standard RT/TR 2x2x2
crossover design or a parallel study. And linear mixed effect model (lme of nlme) for a
2-treatment, 2-sequence with 2 periods or more (i.e. 2x2x3/2x2x4) replicate crossover design.
License GPL (>= 2)
URL http://pkpd.kmu.edu.tw/bear
Repository CRAN
Date/Publication 2010-05-28 06:55:45
R topics documented:
aic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
AICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
AICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
AIC_BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
ARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
ARS.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
ARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
ARSdemo.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
ARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
BANOVAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
BANOVAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1
2 R topics documented:
BANOVAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
BANOVAmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
BANOVAoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
BANOVAplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
bye . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
demoBANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
demomenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
demomenu1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
demopara . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
demosize . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
description_AIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
description_ARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
description_BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
description_drug . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
description_drugcode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
description_import . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
description_load . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
description_Multipledrugcode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
description_NCA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
description_NCAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
description_NCAinput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
description_ParaMIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
description_ParaNCAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
description_ParaNCAinput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
description_plot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
description_Repdrugcode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
description_RepMIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
description_RepNCAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
description_RepNCAinput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
description_size . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
description_size_para . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
description_TOST1_lnAUC0INF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
description_TOST1_lnAUC0t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
description_TOST1_lnCmax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
description_TOST_lnAUC0INF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
description_TOST_lnAUC0t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
description_TOST_lnCmax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
description_TTT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
description_TTTAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
description_TTTARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
description_version . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
entertitle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
entertitle.demo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
go . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
logdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Multiple1menu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Multipleaic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
MultipleAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
R topics documented: 3
MultipleAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
MultipleAIC_BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
MultipleARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
MultipleARS.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
MultipleARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
MultipleARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
MultipleBANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
MultipleBANOVAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
MultipleBANOVAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
MultipleBANOVAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
MultipleBANOVAmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
MultipleBANOVAoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
MultipleBANOVAplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Multipledata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
MultipledemoBANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Multipledemomenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Multipledemomenu1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Multiplego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Multiplemenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
MultipleNCA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
MultipleNCA.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
MultipleNCA.BANOVAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
MultipleNCA.BANOVAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
MultipleNCA.BANOVAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
MultipleNCA.BANOVAmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
MultipleNCAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
MultipleNCAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
MultipleNCAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
MultipleNCAdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
MultipleNCAdemo.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
MultipleNCAmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
MultipleNCAoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
MultipleNCAplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
MultipleNCAsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
MultipleNCAselect . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
MultipleNCAselect.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
MultipleNCAselectdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
MultipleNCAselectdemo.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
MultipleNCAselectsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
MultipleNCAselectsave.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Multiplentertitle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Multiplentertitle.demo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
MultipleParaAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
MultipleParaAIC.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
MultipleParaAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
MultipleParaAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
MultipleParaARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
MultipleParaARS.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4 R topics documented:
MultipleParaARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
MultipleParaARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
MultipleParadata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
MultipleParademomenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
MultipleParademomenu1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
MultipleParademoMIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
MultipleParamenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
MultipleParaMIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
MultipleParaMIXanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
MultipleParaMIXcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
MultipleParaMIXdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
MultipleParaMIXmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
MultipleParaMIXoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
MultipleParaNCA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
MultipleParaNCA.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
MultipleParaNCA.MIXanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
MultipleParaNCA.MIXcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
MultipleParaNCA.MIXdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
MultipleParaNCA.MIXmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
MultipleParaNCAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
MultipleParaNCAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
MultipleParaNCAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
MultipleParaNCAdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
MultipleParaNCAdemo.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
MultipleParaNCAoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
MultipleParaNCAplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
MultipleParaNCAsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
MultipleParaNCAselect . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
MultipleParaNCAselect.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
MultipleParaNCAselectdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
MultipleParaNCAselectdemo.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
MultipleParaNCAselectsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
MultipleParaNCAselectsave.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
MultipleParaTTT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
MultipleParaTTT.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
MultipleParaTTTAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
MultipleParaTTTAIC.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
MultipleParaTTTAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
MultipleParaTTTAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
MultipleParaTTTARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
MultipleParaTTTARS.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
MultipleParaTTTARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
MultipleParaTTTARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
MultipleParaTTTdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
MultipleParaTTToutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
Multipleplotsingle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Multipleplotsingle.para . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Multiplestat1menu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
R topics documented: 5
Multiplestatmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
MultipleTTT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
MultipleTTT.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
MultipleTTTAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
MultipleTTTAIC.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
MultipleTTTAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
MultipleTTTAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
MultipleTTTARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
MultipleTTTARS.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
MultipleTTTARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
MultipleTTTARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
MultipleTTTdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
MultipleTTToutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
NCA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
NCA.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
NCA.BANOVAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
NCA.BANOVAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
NCA.BANOVAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
NCA.BANOVAmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
NCAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
NCAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
NCAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
NCAdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
NCAdemo.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
NCAmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
NCAoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
NCAplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
NCAsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
NCAselect . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
NCAselect.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
NCAselectdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
NCAselectdemo.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
NCAselectsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
NCAselectsave.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
ParaAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
ParaAIC.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
ParaAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
ParaAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
ParaARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
ParaARS.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
ParaARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
ParaARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
Paradata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
Parademomenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
Parademomenu1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
ParademoMIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
Paralleldata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
Paramenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
6 R topics documented:
ParaMIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
ParaMIXanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
ParaMIXcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
ParaMIXdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
ParaMIXmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
ParaMIXoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
ParaNCA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
ParaNCA.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
ParaNCA.MIXanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
ParaNCA.MIXcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
ParaNCA.MIXdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
ParaNCA.MIXmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
ParaNCAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
ParaNCAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
ParaNCAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
ParaNCAdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
ParaNCAdemo.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
ParaNCAoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
ParaNCAplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
ParaNCAsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
ParaNCAselect . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
ParaNCAselect.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
ParaNCAselectdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
ParaNCAselectdemo.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
ParaNCAselectsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
ParaNCAselectsave.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
ParaTTT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
ParaTTT.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
ParaTTTAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
ParaTTTAIC.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
ParaTTTAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
ParaTTTAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
ParaTTTARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
ParaTTTARS.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
ParaTTTARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
ParaTTTARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
ParaTTTdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
ParaTTToutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
plotsingle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
plotsingle.para . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
plotsingle.Rep . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
prdcount . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
Repaic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
RepAIC.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
RepAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
RepAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
RepARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
RepARS.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
R topics documented: 7
RepARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
RepARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
Repdemomenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
Repdemomenu1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
RepdemoMIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
Replicateddata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
Repmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
RepMIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
RepMIXanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
RepMIXcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
RepMIXdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
RepMIXmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
RepMIXoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
RepNCA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
RepNCA.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
RepNCA.MIXanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
RepNCA.MIXcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
RepNCA.MIXdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
RepNCA.MIXmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
RepNCAanalyze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
RepNCAcsv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
RepNCAdata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
RepNCAdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
RepNCAdemo.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
RepNCAoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
RepNCAplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
RepNCAsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
RepNCAselect . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
RepNCAselect.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
RepNCAselectdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
RepNCAselectdemo.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
RepNCAselectsave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
RepNCAselectsave.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
RepTTT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
RepTTT.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
RepTTTAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
RepTTTAIC.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
RepTTTAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
RepTTTAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
RepTTTARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
RepTTTARS.MIX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
RepTTTARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
RepTTTARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
RepTTTdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
RepTTToutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
Singlego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
sizemenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
stat1menu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
8 AICdemo
statmenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
TotalSingledata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
TTT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
TTT.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
TTTAIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
TTTAIC.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
TTTAICdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
TTTAICoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
TTTARS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
TTTARS.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
TTTARSdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
TTTARSoutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
TTTdemo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
TTTdemo.BANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
TTToutput . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
xtick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
ytick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
Index 103
aic Akaike information criterion (AIC) method
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
AICdemo Akaike information criterion (AIC) method for demo function
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
AICoutput 9
AICoutput Output for Adjusted R squared (ARS) method
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
AIC_BANOVA Akaike information criterion (AIC) method and ANOVA
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
ARS Adjusted R squared (ARS) method
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
10 ARSdemo.BANOVA
ARS.BANOVA Adjusted R squared (ARS) method and ANOVA
Description
Adjusted R squared (ARS) method: This method selects data points to estimate lambda(z) based on
the maximun adjustedRsqured values. It starts with the last three data points fromthe concentration-
time course, performing log-linear regression to calculate the slope of that tail portion of the
concentration-time curve. And then the last 4 data points, the last 5 data points, on and on un-
til it excludes the data points of Cmax. Thus, this method may exclude the data point of (Tmax,
Cmax). WNL v6. has the similar algoirthms like this.
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
ARSdemo Adjusted R squared (ARS) method for demo function
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
ARSdemo.BANOVA Adjusted R squared (ARS) method and ANOVA for demo function
Description
Adjusted R squared (ARS) method: This method selects data points to estimate lambda(z) based on
the maximun adjustedRsqured values. It starts with the last three data points fromthe concentration-
time course, performing log-linear regression to calculate the slope of that tail portion of the
concentration-time curve. And then the last 4 data points, the last 5 data points, on and on un-
til it excludes the data points of Cmax. Thus, this method may exclude the data point of (Tmax,
Cmax). WNL v6. has the similar algoirthms like this.
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
ARSoutput 11
ARSoutput Output for Adjusted R squared (ARS) method
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
From: NCAoutput
BANOVA Statistical analysis (ANOVA(lm), 90CI...)
Description
With a two-treatment, two-period, two-sequence randomized crossover design, ANOVA statistical
model includes factors of the following sources: sequence, subjects nested in sequences, period
and treatment. ANOVA will be applied to obtain estimates for the adjusted differences between
treatment means and the standard error associated with these differences. Log-transformed BA
measures will also be analyzed.
We investigate the assessment of equivalence in intra-subject variabilities of bioavailability between
formulations. Point and interval estimates for the inter-subject and intra-subject variabilities are also
provided.
Moreover, a normal distribution test procedure based on Spearmans rank and Pearsons correlation
coefcient and Pitman-Morgans adjusted F test are provided.
Finally, several tests for assumptions using the inter-subject and intra-subject residuals are dis-
cussed. Statistical tests for detection of outlying subjects such as Hotelling T2 are presented.
References
1. Chow SC and Liu JP. Design and analysis of bioavailability- bioequivalence studies. Chapman &
Hall/CRC, New York (2009). 2. Liu JP and Weng CS. Detection of outlying data in bioavailability-
bioequivalence studies. Statist. Med. 10, 1375-1389 (1991).
12 BANOVAmenu
BANOVAanalyze ANOVA function
Description
Data for ANOVA
References
Guidance for Industry. Statistical approaches to establishing Bioequivalence.
BANOVAcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
BANOVAdata Input/Edit data for ANOVA function
Description
->subject no.(subj) ->drug 1:Reference 2:Test ->sequence (seq) Sequence 1:Reference>Test se-
quence Sequence 2:Test>Reference sequence ->period (prd) Period 1: rst treatmetn period Pe-
riod 2: second treatmetn period ->Cmax ->AUC0t: area under the predicted plasma concentration
time curve for test data. (time = 0 to t) ->AUC0INF: area under the predicted plasma concentration
time curve for test data. (time = 0 to innity) ->LnCmax: Log-transformed Cmax ->LnAUC0t:
Log-transformed AUC0t ->LnAUC0INF: Log-transformed AUC0INF
BANOVAmenu List of ANOVA Menu
Description
You can use the functions as follows: 1.Statistical analysis (ANOVA(lm), 90CI...) 2.Demo for
Statistical analysis (ANOVA(lm), 90CI...)
BANOVAoutput 13
BANOVAoutput Output of ANOVA function
Description
We provides several txt outputs. 1.ANOVA stat.txt >ANOVA:Cmax, AUC0t, AUC0inf, ln(Cmax),
ln(AUC0t), ln(AUC0inf) >90CI: ln(Cmax), ln(AUC0t), and ln(AUC0inf)
BANOVAplot BANOVAplot
Description
We provides several pdf. outputs about BANOVA plots for outlier detections. 1.Normal Probabil-
ity Plot of lnCmax (intrasubj) 2.Normal Probability Plot of lnCmax (intersubj) 3.lnCmax(expected
value) vs. studentized residuals(intrasubj) 4.lnCmax(expected value) vs. studentized residuals(intersubj)
5.Normal Probability Plot of lnAUC0t (intrasubj) 6.Normal Probability Plot of lnAUC0t (inter-
subj) 7.lnAUC0t(expected value) vs. studentized residuals(intrasubj) 8.lnAUC0t(expected value)
vs. studentized residuals(intersubj) 9.Normal Probability Plot of lnAUC0INF (intrasubj) 10.Nor-
mal Probability Plot of lnAUC0INF (intersubj) 11.lnAUC0INF(expected value) vs. studentized
residuals(intrasubj) 12.lnAUC0INF(expected value) vs. studentized residuals(intersubj)
bye The nal step Menu
Description
try again or leave bear package.
demoBANOVA Statistical analysis (ANOVA(lm), 90CI...)for demo le
Description
With a two-treatment, two-period, two-sequence randomized crossover design, ANOVA statistical
model includes factors of the following sources: sequence, subjects nested in sequences, period
and treatment. ANOVA will be applied to obtain estimates for the adjusted differences between
treatment means and the standard error associated with these differences. Log-transformed BA
measures will also be analyzed.
14 description_AIC
demomenu menu for NCA demo le
Description
lambda z est. from the exact 3 data points, lambda z est. with adjusted R sq. (ARS), lambda z
est. with Akaike information criterion (AIC), lambda z est. with Two-Times-Tmax method (TTT),
lambda z est. with TTT and ARS, lambda z est. with TTT and AIC
demomenu1 menu for NCA demo le
Description
lambda z est. from the exact 3 data points> Statistical analysis, lambda z est. with adjusted R sq.
(ARS)> Statistical analysis, lambda z est. with Akaike information criterion (AIC)> Statistical
analysis, lambda z est. with Two-Times-Tmax method (TTT)> Statistical analysis, lambda z est.
with TTT and ARS> Statistical analysis, lambda z est. with TTT and AIC> Statistical analysis,
demopara Demo for sample size estimation
Description
Demo le for sample size estimation (crossover and replicated study)function
demosize Demo for sample size estimation
Description
Demo le for sample size estimation (crossover and replicated study)function
description_AIC Description for Akaike information criterion (AIC) method
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
description_ARS 15
description_ARS Description for Adjusted R squared (ARS) method
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
description_BANOVA Description for ANOVA
Description
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
description_drug Description for drug
Description
drug 1: Ref. drug 2: Test
description_drugcode
Description for drug code
Description
Data Codes: Drug: 1: Ref. 2: Test Sequence: 1: Ref. > Test 2: Test > Ref. Period: 1: 1st-
treatment period 2: 2nd-treatment period
16 description_NCAcsv
description_import Description for import csv
Description
Description for import csv le
description_load Description for load Rdata
Description
Description for load Rdata le
description_Multipledrugcode
Description for drug code for multiple study
Description
Data Codes: Drug: 1: Ref. 2: Test Sequence: 1: Ref. > Test 2: Test > Ref. Period: 1: 1st-
treatment period 2: 2nd-treatment period
description_NCA Description for Noncompartmental analysis (NCA)
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
description_NCAcsv Description for NCA csv le
Description
Data le should consist of row1: column title, such as subj, seq, prd, time, conc & etc. column1:
subject no.(subj) column2: sequence (seq) -> Sequence = 1 if Ref.>Test -> Sequence = 2 if Test
>Ref. column3: period (prd) -> Period = 1: the 1st-treatment period -> Period = 2: the 2nd-
treatment period column4: sampling time column5: drug plasma/serum/blood concentration (conc)
description_NCAinput 17
description_NCAinput
Description for NCA input data
Description
Input/Edit Data -> subject no.(subj) -> sequence (seq) 1:Ref.>Test 2:Test>Ref. -> period (prd)
1: 1st-treatment period 2: 2nd-treatment period -> sampling time -> drug plasma/serum/blood
concentration (conc)
description_ParaMIX
Description for lme for parallel study
Description
With a two-treatment, two-sequence, one-period, parallel design, bear deploys the linear mixed
effect model (lme). The statistical model includes a factor regarding only one source of variation -
treatment. There are no sources of variation associated with sequence or period because there are no
sequences or periods in a parallel design. Moreover, lme in nlme package is used to obtain estimates
for the adjusted differences between treatment means and the standard error. Log-transformed BA
measures will also be analyzed.
description_ParaNCAcsv
Description for NCA csv le for parallel study
Description
Data le should consist of row1: column title, such as subj, drug, time, conc &etc. column1: subject
no.(subj) column2: treatment (drug) column3: sampling time column4: drug plasma/serum/blood
concentration (conc)
description_ParaNCAinput
Description for NCA input data for parallel study
Description
Input/Edit Data -> subject no.(subj) -> treatment (drug) 1: Ref. 2: Test -> sampling time -> drug
plasma/serum/blood concentration (conc)
18 description_RepNCAcsv
description_plot Description for plot
Description
Authors: Hsin-ya Lee, Yung-jin Lee 100, Shih-chuan 1st Rd. College of Pharmacy, Kaohsiung
Medical University, Kaoshiung, Taiwan 80708 E-mail: hsinyalee@gmail.com, pkpd.taiwan@gmail.com
bears website: http://pkpd.kmu.edu.tw/bear R website: www.r-project.org
description_Repdrugcode
Description of drug code for replicated study
Description
Data Codes: Drug: 1: Ref. 2: Test
description_RepMIX Description for lme for replicated study
Description
With a two-treatment, more than two period, two-sequence randomized crossover design, linear
mixed-effects model may be used. The lme in nlme package is used to obtain estimates for the ad-
justed differences between treatment means and the standard error associated with these differences.
Log-transformed BA measures will also be analyzed.
description_RepNCAcsv
Description of NCA csv le for replicated study
Description
Data le should consist of row1: column title, such as subj, seq, prd, time, conc & etc. column1:
subject no.(subj) column2: sequence (seq) -> Sequence = 1 if Ref.>Test -> Sequence = 2 if Test
>Ref. column3: period (prd) -> Period = 1: the 1st-treatment period -> Period = 2: the 2nd-
treatment period
column4: treatment (drug) column5: sampling time column6: drug plasma/serum/blood concentra-
tion (conc)
description_RepNCAinput 19
description_RepNCAinput
Description for NCA input data for replicated study
Description
Input/Edit Data -> subject no.(subj) -> sequence (seq) ex. 4 periods 1:Ref.>Test>Ref.>Test
2:Test>Ref.>Test>Ref. or ex. 3 periods 1:Ref.>Test>Test 2:Test>Ref.>Ref. -> period (prd)
1: 1st-treatment period 2: 2nd-treatment period 3: 3rd-treatment period 4: 4th-treatment period ->
treatment (drug) 1: Ref. 2: Test -> sampling time -> drug plasma/serum/blood concentration (conc)
description_size Description for sample size input for crossover and replicated study
Description
Required data 1. Theta is the ratio in average BA between the two formulations expressed in per-
centage of the average reference BA. 2. Theta=Ut/Ur, where Ut and Ur denote the median BA for
the Test and the Reference products. 3. CV stands for the intra-subject coefcient of variation.
description_size_para
Description for sample size input for parallel study
Description
Required data 1. Theta is the ratio in average BA between the two formulations expressed in per-
centage of the average reference BA. 2. Theta=Ut/Ur, where Ut and Ur denote the median BA for
the Test and the Reference products. 3. CV stands for the inter-subject coefcient of variation.
20 description_TOST1_lnAUC0t
description_TOST1_lnAUC0INF
Description for Two One-Sided Test for lnAUC0INF
Description
Interpretation: Ho: MEAN-test/MEAN-ref =< ln(lower acceptance) or MEAN-test/MEAN-ref >=
ln(Upper acceptance) Ha: ln(lower acceptance) < MEAN-test/MEAN-ref < ln(Upper acceptance)
Because all P values are less than 0.05, we will reject the null hypothesis (Ho).
References
1. Chow SC and Liu JP. Design and Analysis of Bioavailability- Bioequivalence Studies. 3rd ed.,
Chapman & Hall/CRC, New York (2009). 2. Schuirmann DJ. On hypothesis testing to determine
if the mean of a normal distribution is continued in a known interval.Biometrics, 37, 617(1981). 3.
Schuirmann DJ. A comparison of the two one-sided tests procedure and the power approach for as-
sessing the equivalence of average bioavailability. Journal of Pharmacokinetics and Biopharmaceu-
tics, 15, 657-680 (1987). 4. Anderson S and Hauck WW. A new procedure for testing equivalence
in comparative bioavailability and other clinical trials. Communications in Statistics-Theory and
Methods, 12, 2663-2692 (1983).
description_TOST1_lnAUC0t
Description for Two One-Sided Test for lnAUC0t
Description
Interpretation: Ho: MEAN-test/MEAN-ref =< ln(lower acceptance) or MEAN-test/MEAN-ref >=
ln(Upper acceptance) Ha: ln(lower acceptance) < MEAN-test/MEAN-ref < ln(Upper acceptance)
Because all P values are less than 0.05, we will reject the null hypothesis (Ho).
References
1. Chow SC and Liu JP. Design and Analysis of Bioavailability- Bioequivalence Studies. 3rd ed.,
Chapman & Hall/CRC, New York (2009). 2. Schuirmann DJ. On hypothesis testing to determine
if the mean of a normal distribution is continued in a known interval.Biometrics, 37, 617(1981). 3.
Schuirmann DJ. A comparison of the two one-sided tests procedure and the power approach for as-
sessing the equivalence of average bioavailability. Journal of Pharmacokinetics and Biopharmaceu-
tics, 15, 657-680 (1987). 4. Anderson S and Hauck WW. A new procedure for testing equivalence
in comparative bioavailability and other clinical trials. Communications in Statistics-Theory and
Methods, 12, 2663-2692 (1983).
description_TOST1_lnCmax 21
description_TOST1_lnCmax
Description for Two One-Sided Test for lnCmax
Description
Interpretation: Ho: MEAN-test/MEAN-ref =< ln(lower acceptance) or MEAN-test/MEAN-ref >=
ln(Upper acceptance) Ha: ln(lower acceptance) < MEAN-test/MEAN-ref < ln(Upper acceptance)
Because all P values are less than 0.05, we will reject the null hypothesis (Ho).
References
1. Chow SC and Liu JP. Design and Analysis of Bioavailability- Bioequivalence Studies. 3rd ed.,
Chapman & Hall/CRC, New York (2009). 2. Schuirmann DJ. On hypothesis testing to determine
if the mean of a normal distribution is continued in a known interval.Biometrics, 37, 617(1981). 3.
Schuirmann DJ. A comparison of the two one-sided tests procedure and the power approach for as-
sessing the equivalence of average bioavailability. Journal of Pharmacokinetics and Biopharmaceu-
tics, 15, 657-680 (1987). 4. Anderson S and Hauck WW. A new procedure for testing equivalence
in comparative bioavailability and other clinical trials. Communications in Statistics-Theory and
Methods, 12, 2663-2692 (1983).
description_TOST_lnAUC0INF
Description for Two One-Sided Test for lnAUC0INF
Description
Interpretation: Ho: MEAN-test/MEAN-ref =< ln(lower acceptance) or MEAN-test/MEAN-ref >=
ln(Upper acceptance) Ha: ln(lower acceptance) < MEAN-test/MEAN-ref < ln(Upper acceptance)
If at least one of P value is more than 0.05, we will not reject the null hypothesis (Ho).
References
1. Chow SC and Liu JP. Design and Analysis of Bioavailability- Bioequivalence Studies. 3rd ed.,
Chapman & Hall/CRC, New York (2009). 2. Schuirmann DJ. On hypothesis testing to determine
if the mean of a normal distribution is continued in a known interval.Biometrics, 37, 617(1981). 3.
Schuirmann DJ. A comparison of the two one-sided tests procedure and the power approach for as-
sessing the equivalence of average bioavailability. Journal of Pharmacokinetics and Biopharmaceu-
tics, 15, 657-680 (1987). 4. Anderson S and Hauck WW. A new procedure for testing equivalence
in comparative bioavailability and other clinical trials. Communications in Statistics-Theory and
Methods, 12, 2663-2692 (1983).
22 description_TOST_lnCmax
description_TOST_lnAUC0t
Description for Two One-Sided Test for lnAUC0t
Description
Interpretation: Ho: MEAN-test/MEAN-ref =< ln(lower acceptance) or MEAN-test/MEAN-ref >=
ln(Upper acceptance) Ha: ln(lower acceptance) < MEAN-test/MEAN-ref < ln(Upper acceptance)
If at least one of P value is more than 0.05, we will not reject the null hypothesis (Ho).
References
1. Chow SC and Liu JP. Design and Analysis of Bioavailability- Bioequivalence Studies. 3rd ed.,
Chapman & Hall/CRC, New York (2009). 2. Schuirmann DJ. On hypothesis testing to determine
if the mean of a normal distribution is continued in a known interval.Biometrics, 37, 617(1981). 3.
Schuirmann DJ. A comparison of the two one-sided tests procedure and the power approach for as-
sessing the equivalence of average bioavailability. Journal of Pharmacokinetics and Biopharmaceu-
tics, 15, 657-680 (1987). 4. Anderson S and Hauck WW. A new procedure for testing equivalence
in comparative bioavailability and other clinical trials. Communications in Statistics-Theory and
Methods, 12, 2663-2692 (1983).
description_TOST_lnCmax
Description for Two One-Sided Test for lnCmax
Description
Interpretation: Ho: MEAN-test/MEAN-ref =< ln(lower acceptance) or MEAN-test/MEAN-ref >=
ln(Upper acceptance) Ha: ln(lower acceptance) < MEAN-test/MEAN-ref < ln(Upper acceptance)
If at least one of P value is more than 0.05, we will not reject the null hypothesis (Ho).
References
1. Chow SC and Liu JP. Design and Analysis of Bioavailability- Bioequivalence Studies. 3rd ed.,
Chapman & Hall/CRC, New York (2009). 2. Schuirmann DJ. On hypothesis testing to determine
if the mean of a normal distribution is continued in a known interval.Biometrics, 37, 617(1981). 3.
Schuirmann DJ. A comparison of the two one-sided tests procedure and the power approach for as-
sessing the equivalence of average bioavailability. Journal of Pharmacokinetics and Biopharmaceu-
tics, 15, 657-680 (1987). 4. Anderson S and Hauck WW. A new procedure for testing equivalence
in comparative bioavailability and other clinical trials. Communications in Statistics-Theory and
Methods, 12, 2663-2692 (1983).
description_TTT 23
description_TTT Description for Two Times Tmax (TTT) method
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
description_TTTAIC Description for Two-Times-Tmax (TTT) and Akaike information crite-
rion (AIC)
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
description_TTTARS Description for Two Times Tmax (TTT) and Adjusted R squared (ARS)
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
24 go
description_version
Description for version
Description
Authors: Hsin-ya Lee, Yung-jin Lee 100, Shih-chuan 1st Rd. College of Pharmacy, Kaohsiung
Medical University, Kaoshiung, Taiwan 80708 E-mail: hsinyalee@gmail.com, pkpd.taiwan@gmail.com
bears website: http://pkpd.kmu.edu.tw/bear R website: www.r-project.org
entertitle enter Dose, xaxis and yaxis
Description
enter Dose, xaxis and yaxis
entertitle.demo enter Dose, xaxis and yaxis for demo le
Description
enter Dose, xaxis and yaxis
go List of bear Menu
Description
You can use the functions as follows: 1.Single dose study 2.Multiple dose study
logdata 25
logdata Sample size estimation for log transformation data for crossover and
replicated study
Description
This function will help you to choose appropriate sample size.
References
R-code based on SAS-code by (1) B. Jones and M.G. Kenward Design and Analysis of Cross-
Over Trials Chapman & Hall/CRC, Boca Raton (2nd Edition 2000) (2) S. Patterson and B. Jones
Bioequivalence and Statistics in Clinical Pharmacology Chapman & Hall/CRC, Boca Raton (2006)
/*** WARNING : PROGRAM OFFERED FOR USE WITHOUT ANY GUARANTEES ***/ /***
NO LIABILITY IS ACCEPTED FOR ANY LOSS RESULTING FROM USE OF ***/ /*** THIS
SET OF SAS INTRUCTIONS ***/ Modication of degrees of freedom according to a personal
message by D. Hauschke (E-mail 2006-01-05) Tested in R-versions 2.6.2 / 2.5.1 / 1.9.1 / 1.9.0
2008-04-04 Sample size R-code was referred from Helmut Schuetz BEBAC - Consultancy services
for Bioequivalence and Bioavailability Studies 1070 Vienna, Austria
Hauschke D, Steinijans VW, Diletti E and Burke M. Sample size determination for bioequivalence
assessment using a multiplicative model. J. Pharmacokin. Biopharm. 20:557-561 (1992).
Multiple1menu List of NCA non-replicated and replicated study
Description
You can use the functions as follows: 1. NCA for non-replicated crossover study, 2. NCA for
replicated crossover study,
Multipleaic Akaike information criterion (AIC) method for multiple study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
26 MultipleAIC_BANOVA
MultipleAICdemo Akaike information criterion (AIC) method for demo function
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
MultipleAICoutput Output for Adjusted R squared (ARS) method for multiple dose
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
MultipleAIC_BANOVA Akaike information criterion (AIC) method and ANOVA for multiple
dose
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
MultipleARS 27
MultipleARS Adjusted R squared (ARS) method for multiple dose
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
MultipleARS.BANOVA Adjusted R squared (ARS) method and ANOVA for multiple dose
Description
Adjusted R squared (ARS) method: This method selects data points to estimate lambda(z) based on
the maximun adjustedRsqured values. It starts with the last three data points fromthe concentration-
time course, performing log-linear regression to calculate the slope of that tail portion of the
concentration-time curve. And then the last 4 data points, the last 5 data points, on and on un-
til it excludes the data points of Cmax. Thus, this method may exclude the data point of (Tmax,
Cmax). WNL v6. has the similar algoirthms like this.
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
MultipleARSdemo Adjusted R squared (ARS) method for demo function for multiple dose
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
28 MultipleBANOVA
MultipleARSoutput Output for Adjusted R squared (ARS) method for multiple dose
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
MultipleBANOVA Statistical analysis (ANOVA(lm), 90CI...)
Description
With a two-treatment, two-period, two-sequence randomized crossover design, ANOVA statistical
model includes factors of the following sources: sequence, subjects nested in sequences, period
and treatment. ANOVA will be applied to obtain estimates for the adjusted differences between
treatment means and the standard error associated with these differences. Log-transformed BA
measures will also be analyzed.
We investigate the assessment of equivalence in intra-subject variabilities of bioavailability between
formulations. Point and interval estimates for the inter-subject and intra-subject variabilities are also
provided.
Moreover, a normal distribution test procedure based on Spearmans rank and Pearsons correlation
coefcient and Pitman-Morgans adjusted F test are provided.
Finally, several tests for assumptions using the inter-subject and intra-subject residuals are dis-
cussed. Statistical tests for detection of outlying subjects such as Hotelling T2 are presented.
References
1. Chow SC and Liu JP. Design and analysis of bioavailability- bioequivalence studies. Chapman &
Hall/CRC, New York (2009). 2. Liu JP and Weng CS. Detection of outlying data in bioavailability-
bioequivalence studies. Statist. Med. 10, 1375-1389 (1991).
MultipleBANOVAanalyze 29
MultipleBANOVAanalyze
ANOVA function for multiple dose
Description
Data for ANOVA
References
Guidance for Industry. Statistical approaches to establishing Bioequivalence.
MultipleBANOVAcsv choose separator and decimal type for multiple dose
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
MultipleBANOVAdata Input/Edit data for ANOVA function for multiple dose
Description
->subject no.(subj) ->drug 1:Reference 2:Test ->sequence (seq) Sequence 1:Reference>Test se-
quence Sequence 2:Test>Reference sequence ->period (prd) Period 1: rst treatmetn period Pe-
riod 2: second treatmetn period ->Css_max ->AUCss(tau): area under the predicted plasma con-
centration time curve (time = tau) ->LnCss_max: Log-transformed Cmax ->LnAUC0ss(tau): Log-
transformed AUC0ss(tau)
MultipleBANOVAmenu List of ANOVA Menu for multiple dose
Description
You can use the functions as follows: 1.Statistical analysis (ANOVA(lm), 90CI...) 2.Demo for
Statistical analysis (ANOVA(lm), 90CI...)
30 MultipledemoBANOVA
MultipleBANOVAoutput
Output of ANOVA function for multiple dose
Description
We provides several txt outputs. 1.ANOVA stat.txt >ANOVA:Css_max, AUCss(tau), lnCss_max,
lnAUCss(tau) >90CI: lnCss_max, lnAUCss(tau)
MultipleBANOVAplot BANOVAplot for multiple dose
Description
We provides several pdf. outputs about BANOVA plots for outlier detections. 1.Normal Probability
Plot of lnCss_max (intrasubj) 2.Normal Probability Plot of lnCss_max (intersubj) 3.lnCss_max(expected
value) vs. studentized residuals(intrasubj) 4.lnCss_max(expected value) vs. studentized resid-
uals(intersubj) 5.Normal Probability Plot of lnAUCss(tau) (intrasubj) 6.Normal Probability Plot
of lnAUCss(tau) (intersubj) 7.lnAUCss(tau)(expected value) vs. studentized residuals(intrasubj)
8.lnAUCss(tau)(expected value) vs. studentized residuals(intersubj)
Multipledata Data for NCA analyze for multiple dose
Description
The data give the data of subjects, drug, sequence, period, time, and concentration.
MultipledemoBANOVA Statistical analysis (ANOVA(lm), 90CI...)for demo le
Description
With a two-treatment, two-period, two-sequence randomized crossover design, ANOVA statistical
model includes factors of the following sources: sequence, subjects nested in sequences, period
and treatment. ANOVA will be applied to obtain estimates for the adjusted differences between
treatment means and the standard error associated with these differences. Log-transformed BA
measures will also be analyzed.
Multipledemomenu 31
Multipledemomenu menu for NCA demo le
Description
lambda z est. from the exact 3 data points, lambda z est. with adjusted R sq. (ARS), lambda z
est. with Akaike information criterion (AIC), lambda z est. with Two-Times-Tmax method (TTT),
lambda z est. with TTT and ARS, lambda z est. with TTT and AIC
Multipledemomenu1 menu for NCA demo le
Description
lambda z est. from the exact 3 data points> Statistical analysis, lambda z est. with adjusted R sq.
(ARS)> Statistical analysis, lambda z est. with Akaike information criterion (AIC)> Statistical
analysis, lambda z est. with Two-Times-Tmax method (TTT)> Statistical analysis, lambda z est.
with TTT and ARS> Statistical analysis, lambda z est. with TTT and AIC> Statistical analysis,
Multiplego List of bear Menu
Description
You can use the functions as follows: 1.Sample size estimation for average BE 2.Noncompartment
Analysis (NCA) 3.ANOVA 4.NCA->ANOVA
Multiplemenu List of NCA non-replicated and replicated study
Description
You can use the functions as follows: 1. NCA for non-replicated crossover study, 2. NCA for
replicated crossover study,
32 MultipleNCA.BANOVAcsv
MultipleNCA Noncompartmental analysis (NCA) for multiple dose
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
MultipleNCA.BANOVA NCA and ANOVA for multiple dose
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
MultipleNCA.BANOVAanalyze
NCA and ANOVA function for multiple dose
Description
This function includes both NCAanalyze and BANOVAanalyze functions.
MultipleNCA.BANOVAcsv
choose separator and decimal type for multiple dose
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
MultipleNCA.BANOVAdata 33
MultipleNCA.BANOVAdata
Input/Edit data for NCA and ANOVA function for multiple dose
Description
Input/Edit Data ->subject no.(subj) ->sequence (seq) Sequence 1:Reference>Test sequence Se-
quence 2:Test>Reference sequence ->period (prd) Period 1: rst treatmetn period Period 2: second
treatmetn period ->time ->concentration (conc)
MultipleNCA.BANOVAmenu
List of NCA and ANOVA Menu for multiple dose
Description
You can use the functions as follows: 1.NCA>ANOVA 2.Run demo for NCA > Statistical anal-
ysis
MultipleNCAanalyze NCA analyze function for multiple dose
Description
We provide noncompartmental analysis (NCA) approach to compute AUCs and terminal elimina-
tion rate constant (kel) for plasma concentration. Here we provide six methods, exact 3 data points,
ARS, TTT, AIC, TTT and ARS, and TTT and AIC.
MultipleNCAcsv choose separator and decimal type for multiple dose
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
34 MultipleNCAmenu
MultipleNCAdata Input/Edit data for NCA function for multiple dose
Description
Input/Edit Data ->subject no.(subj) ->sequence (seq) Sequence 1:Reference>Test sequence Se-
quence 2:Test>Reference sequence ->period (prd) Period 1: rst treatmetn period Period 2: second
treatmetn period ->time ->concentration (conc)
MultipleNCAdemo Select the exact 3 data points(NCA) for demo function for multiple
dose
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
MultipleNCAdemo.BANOVA
Select the exact 3 data points(NCA) and ANOVA for demo function for
multiple dose
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
MultipleNCAmenu List of NCA 2x2x2 Menu for multiple dose
Description
You can use the functions as follows: 1.multiple Dose 2.Demo for multiple Dose
MultipleNCAoutput 35
MultipleNCAoutput Output of NCA for multiple dose
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
MultipleNCAplot NCAplot for multiple dose
Description
We provides several pdf. outputs about NCA plots. 1.Conc. vs. Time for individual subjects
2.Log10(Conc.) vs. Time for individual subjects 3.Test (.Conc. vs. Time) for all subjects 4.Refer-
ence (.Conc. vs. Time) for all subjects 5.Conc.(mean+-sd) vs Time for test and reference
MultipleNCAsave Save NCA outputs for multiple dose
Description
This function can save the results after NCA.
MultipleNCAselect Select the exact 3 points in NCA for multiple dose
Description
This function can help users select the exact 3 points for NCA function.
MultipleNCAselect.BANOVA
Select the exact 3 points in NCA and ANOVA for multiple dose
Description
This function can help users select the exact 3 points for NCA function.
36 Multiplentertitle
MultipleNCAselectdemo
Select the exact 3 points in NCA for demo function for multiple dose
Description
This function can help users select the exact 3 points for NCA function.
MultipleNCAselectdemo.BANOVA
Select the exact 3 points in NCA and ANOVA for demo function for
multiple dose
Description
This function can help users select the exact 3 points for NCA function.
MultipleNCAselectsave
Select the exact 3 points in NCA and Save the data for multiple dose
Description
This function can save the exact 3 points.
MultipleNCAselectsave.BANOVA
Select the exact 3 points in NCA and Save the data for multiple dose
Description
This function can save the exact 3 points.
Multiplentertitle enter Dose, tau, time of last dose, xaxis and yaxis for multiple dose
Description
enter Dose, tau, time of last dose, xaxis and yaxis
Multiplentertitle.demo 37
Multiplentertitle.demo
enter Dose, tau, time of last dose, xaxis and yaxis for multiple dose for
demo le
Description
enter Dose, tau, time of last dose, xaxis and yaxis
MultipleParaAIC Akaike information criterion (AIC) method for parallel with multiple
dose study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
MultipleParaAIC.MIX
Akaike information criterion (AIC) method->statictics for parallel
with multiple dose study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
38 MultipleParaARS
MultipleParaAICdemo
Akaike information criterion (AIC) method for demo function for par-
allel with multiple dose study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
MultipleParaAICoutput
Output for Adjusted R squared (ARS) method for parallel with multiple
dose study
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
MultipleParaARS Adjusted R squared (ARS) method for parallel with multiple dose study
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
MultipleParaARS.MIX 39
MultipleParaARS.MIX
Adjusted R squared (ARS) method and lme for parallel with multiple
dose study
Description
Adjusted R squared (ARS) method: This method selects data points to estimate lambda(z) based on
the maximun adjustedRsqured values. It starts with the last three data points fromthe concentration-
time course, performing log-linear regression to calculate the slope of that tail portion of the
concentration-time curve. And then the last 4 data points, the last 5 data points, on and on un-
til it excludes the data points of Cmax. Thus, this method may exclude the data point of (Tmax,
Cmax). WNL v6. has the similar algoirthms like this.
With a two-treatment, two-sequence, one-period, parallel design, bear deploys the linear mixed
effect model (lme). The statistical model includes a factor regarding only one source of variation -
treatment. There are no sources of variation associated with sequence or period because there are no
sequences or periods in a parallel design. Moreover, lme in nlme package is used to obtain estimates
for the adjusted differences between treatment means and the standard error. Log-transformed BA
measures will also be analyzed.
MultipleParaARSdemo
Adjusted R squared (ARS) method for demo function for parallel with
multiple dose study
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
MultipleParaARSoutput
Output for Adjusted R squared (ARS) method for parallel study
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
40 MultipleParademoMIX
MultipleParadata Data for NCA analyze for parallel with multiple dose study
Description
The data give the data of subjects, drug, time, and concentration.
MultipleParademomenu
menu for NCA demo le for parallel with multiple dose study
Description
lambda z est. from the exact 3 data points, lambda z est. with adjusted R sq. (ARS), lambda z
est. with Akaike information criterion (AIC), lambda z est. with Two-Times-Tmax method (TTT),
lambda z est. with TTT and ARS, lambda z est. with TTT and AIC
MultipleParademomenu1
menu for NCA->Statistical analysis demo le for parallel with multi-
ple dose study
Description
lambda z est. from the exact 3 data points> Statistical analysis, lambda z est. with adjusted R sq.
(ARS)> Statistical analysis, lambda z est. with Akaike information criterion (AIC)> Statistical
analysis, lambda z est. with Two-Times-Tmax method (TTT)> Statistical analysis, lambda z est.
with TTT and ARS> Statistical analysis, lambda z est. with TTT and AIC> Statistical analysis,
MultipleParademoMIX
Statistical analysis (lme, 90CI...)for demo le for parallel with multi-
ple dose study
Description
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
MultipleParamenu 41
MultipleParamenu List of NCA 2x2x1 Menu for multiple dose
Description
You can use the functions as follows: 1.run NCA 2.Demo for NCA
MultipleParaMIX Statistical analysis (lme, 90CI...) for parallel with multiple dose study
Description
With a two-treatment, two-sequence, one-period, parallel design, bear deploys the linear mixed
effect model (lme). The statistical model includes a factor regarding only one source of variation -
treatment. There are no sources of variation associated with sequence or period because there are no
sequences or periods in a parallel design. Moreover, lme in nlme package is used to obtain estimates
for the adjusted differences between treatment means and the standard error. Log-transformed BA
measures will also be analyzed.
MultipleParaMIXanalyze
Split data to perform lme function for parallel with multiple dose study
Description
Split data for lme function
References
Guidance for Industry. Statistical approaches to establishing Bioequivalence.
MultipleParaMIXcsv choose separator and decimal type for multiple dose
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
42 MultipleParaNCA
MultipleParaMIXdata
Input/Edit data for lme function for parallel with multiple dose study
Description
->subject no.(subj) ->drug 1:Reference 2:Test ->Css_max ->AUCss(tau): area under the predicted
plasma concentration time curve (time = tau) ->LnCss_max: Log-transformed Cmax ->LnAUC0ss(tau):
Log-transformed AUC0ss(tau)
MultipleParaMIXmenu
List of lme Menu for multiple dose
Description
You can use the functions as follows: 1.Statistical analysis (lme, 90CI...) 2.Demo for Statistical
analysis (lme, 90CI...)
MultipleParaMIXoutput
Output of lme function for multiple dose
Description
We provides several txt outputs. 1.lme stat.txt >lme: Css_max, AUCss(tau), lnCss_max, lnAUCss(tau)
>90CI: lnCss_max, lnAUCss(tau)
MultipleParaNCA Noncompartmental analysis (NCA) for parallel with multiple dose
study
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
MultipleParaNCA.MIX 43
MultipleParaNCA.MIX
NCA and lme for parallel study for multiple dose
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
MultipleParaNCA.MIXanalyze
NCA and lme function for multiple dose
Description
This function includes both NCA and lme functions.
MultipleParaNCA.MIXcsv
choose separator and decimal type for multiple dose
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
MultipleParaNCA.MIXdata
Input/Edit data for NCA and lme function for parallel with multiple
dose study
Description
Input/Edit Data ->subject no.(subj) ->drug ref.: 1 test: 2 ->time ->concentration (conc)
44 MultipleParaNCAdata
MultipleParaNCA.MIXmenu
List of NCA and lme Menu for multiple dose
Description
You can use the functions as follows: 1.NCA>lme 2.Run demo for NCA > Statistical analysis
MultipleParaNCAanalyze
NCA analyze function for parallel with multiple dose study
Description
We provide noncompartmental analysis (NCA) approach to compute AUCs and terminal elimina-
tion rate constant (kel) for plasma concentration. Here we provide six methods, exact 3 data points,
ARS, TTT, AIC, TTT and ARS, and TTT and AIC.
MultipleParaNCAcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
MultipleParaNCAdata
Input/Edit data for NCA function for parallel study
Description
Input/Edit Data ->subject no.(subj) ->drug ->time ->concentration (conc)
MultipleParaNCAdemo 45
MultipleParaNCAdemo
Select the exact 3 data points(NCA) for demo function for parallel
study
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
MultipleParaNCAdemo.MIX
Select the exact 3 data points(NCA) and lme for demo function
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
MultipleParaNCAoutput
Output of NCA for parallel study
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
46 MultipleParaNCAselectdemo
MultipleParaNCAplot
NCAplot for parallel study
Description
We provides several pdf. outputs about NCA plots. 1.Conc. vs. Time for individual subjects
2.Log10(Conc.) vs. Time for individual subjects 3.Test (.Conc. vs. Time) for all subjects 4.Refer-
ence (.Conc. vs. Time) for all subjects 5.Conc.(mean+-sd) vs Time for test and reference
MultipleParaNCAsave
Save NCA outputs for parallel study
Description
This function can save the results after NCA.
MultipleParaNCAselect
Select the exact 3 points in NCA for parallel study
Description
This function can help users select the exact 3 points for NCA function.
MultipleParaNCAselect.MIX
Select the exact 3 points in NCA and lme for parallel study
Description
This function can help users select the exact 3 points for NCA function.
MultipleParaNCAselectdemo
Select the exact 3 points in NCA for demo function for parallel study
Description
This function can help users select the exact 3 points for NCA function.
MultipleParaNCAselectdemo.MIX 47
MultipleParaNCAselectdemo.MIX
Select the exact 3 points in NCA and lme for demo function (parallel
study)
Description
This function can help users select the exact 3 points for NCA function.
MultipleParaNCAselectsave
Select the exact 3 points in NCA and Save the data for parallel study
Description
This function can save data of the exact 3 points.
MultipleParaNCAselectsave.MIX
Select the exact 3 points in NCA and Save the data
Description
This function can save the exact 3 points.
MultipleParaTTT Two Times Tmax (TTT) method for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
48 MultipleParaTTTAIC
MultipleParaTTT.MIX
TTT and lme for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleParaTTTAIC TTT and AIC for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleParaTTTAIC.MIX 49
MultipleParaTTTAIC.MIX
TTT ,AIC and lme for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
MultipleParaTTTAICdemo
TTT and AIC for demo function for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
50 MultipleParaTTTARS
MultipleParaTTTAICoutput
Output for TTT and AIC for parallel study
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleParaTTTARS TTT and ARS for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleParaTTTARS.MIX 51
MultipleParaTTTARS.MIX
TTT ,ARS and lme for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleParaTTTARSdemo
TTT and ARS for demo function for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
52 MultipleParaTTToutput
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleParaTTTARSoutput
Output for TTT and ARS for parallel study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleParaTTTdemo
Two Times Tmax (TTT) method for demo function for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
MultipleParaTTToutput
Output for Two Times Tmax (TTT) method for parallel study
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
Multipleplotsingle 53
Multipleplotsingle plot individual data for crossover study
Description
Plot for individual person for BA (conc vs. time) and ln(BA)(lnconc vs. time)
Multipleplotsingle.para
plot individual data for parallel study
Description
Plot for individual person for BA (conc vs. time) and ln(BA)(lnconc vs. time)
Multiplestat1menu List of Statistical analysis non-replicated and replicated study
Description
You can use the functions as follows: 1. Statistical analysis for non-replicated crossover study, 2.
Statistical analysis for replicated crossover study,
Multiplestatmenu List of NCA>statistics non-replicated and replicated study
Description
You can use the functions as follows: 1. NCA for non-replicated crossover study, 2. NCA for
replicated crossover study,
54 MultipleTTT.BANOVA
MultipleTTT Two Times Tmax (TTT) method
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTT.BANOVA TTT and ANOVA
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTTAIC 55
MultipleTTTAIC TTT and AIC
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTTAIC.BANOVA
TTT ,AIC and ANOVA
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
56 MultipleTTTAICoutput
MultipleTTTAICdemo TTT and AIC for demo function
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTTAICoutput
Output for TTT and AIC
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTTARS 57
MultipleTTTARS TTT and ARS
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTTARS.BANOVA
TTT ,ARS and ANOVA
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
58 MultipleTTTARSoutput
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTTARSdemo TTT and ARS for demo function
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTTARSoutput
Output for TTT and ARS
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
MultipleTTTdemo 59
MultipleTTTdemo Two Times Tmax (TTT) method for demo function
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
MultipleTTToutput Output for Two Times Tmax (TTT) method
Description
We provides several txt outputs. 1. NCA PK.txt: >Css_max, Tss_max, AUCss(tau), ln(Css_max),
ln(AUCss(tau)), MRTss(tau), T1/2(z), Vd/F, lambda, Clss/F, Cav and Fluctuation > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
NCA Noncompartmental analysis (NCA)
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
60 NCA.BANOVAdata
NCA.BANOVA NCA and ANOVA
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
NCA.BANOVAanalyze NCA and ANOVA function
Description
This function includes both NCAanalyze and BANOVAanalyze functions.
NCA.BANOVAcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
NCA.BANOVAdata Input/Edit data for NCA and ANOVA function
Description
Input/Edit Data ->subject no.(subj) ->sequence (seq) Sequence 1:Reference>Test sequence Se-
quence 2:Test>Reference sequence ->period (prd) Period 1: rst treatmetn period Period 2: second
treatmetn period ->time ->concentration (conc)
NCA.BANOVAmenu 61
NCA.BANOVAmenu List of NCA and ANOVA Menu
Description
You can use the functions as follows: 1.NCA>ANOVA 2.Run demo for NCA > Statistical anal-
ysis
NCAanalyze NCA analyze function
Description
We provide noncompartmental analysis (NCA) approach to compute AUCs and terminal elimina-
tion rate constant (kel) for plasma concentration. Here we provide six methods, exact 3 data points,
ARS, TTT, AIC, TTT and ARS, and TTT and AIC.
NCAcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
NCAdata Input/Edit data for NCA function
Description
Input/Edit Data ->subject no.(subj) ->sequence (seq) Sequence 1:Reference>Test sequence Se-
quence 2:Test>Reference sequence ->period (prd) Period 1: rst treatmetn period Period 2: second
treatmetn period ->time ->concentration (conc)
NCAdemo Select the exact 3 data points(NCA) for demo function
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
62 NCAplot
NCAdemo.BANOVA Select the exact 3 data points(NCA) and ANOVA for demo function
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
NCAmenu List of NCA 2x2x2 Menu
Description
You can use the functions as follows: 1.Single Dose 2.Demo for Single Dose
NCAoutput Output of NCA
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
NCAplot NCAplot
Description
We provides several pdf. outputs about NCA plots. 1.Conc. vs. Time for individual subjects
2.Log10(Conc.) vs. Time for individual subjects 3.Test (.Conc. vs. Time) for all subjects 4.Refer-
ence (.Conc. vs. Time) for all subjects 5.Conc.(mean+-sd) vs Time for test and reference
NCAsave 63
NCAsave Save NCA outputs
Description
This function can save the results after NCA.
NCAselect Select the exact 3 points in NCA
Description
This function can help users select the exact 3 points for NCA function.
NCAselect.BANOVA Select the exact 3 points in NCA and ANOVA
Description
This function can help users select the exact 3 points for NCA function.
NCAselectdemo Select the exact 3 points in NCA for demo function
Description
This function can help users select the exact 3 points for NCA function.
NCAselectdemo.BANOVA
Select the exact 3 points in NCA and ANOVA for demo function
Description
This function can help users select the exact 3 points for NCA function.
64 ParaAIC.MIX
NCAselectsave Select the exact 3 points in NCA and Save the data
Description
This function can save the exact 3 points.
NCAselectsave.BANOVA
Select the exact 3 points in NCA and Save the data
Description
This function can save the exact 3 points.
ParaAIC Akaike information criterion (AIC) method for parallel study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
ParaAIC.MIX Akaike information criterion (AIC) method->statictics for parallel
study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
ParaAICdemo 65
ParaAICdemo Akaike information criterion (AIC) method for demo function for par-
allel study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
ParaAICoutput Output for Adjusted R squared (ARS) method for parallel study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
ParaARS Adjusted R squared (ARS) method for parallel study
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
66 ParaARSoutput
ParaARS.MIX Adjusted R squared (ARS) method and lme for parallel study
Description
Adjusted R squared (ARS) method: This method selects data points to estimate lambda(z) based on
the maximun adjustedRsqured values. It starts with the last three data points fromthe concentration-
time course, performing log-linear regression to calculate the slope of that tail portion of the
concentration-time curve. And then the last 4 data points, the last 5 data points, on and on un-
til it excludes the data points of Cmax. Thus, this method may exclude the data point of (Tmax,
Cmax). WNL v6. has the similar algoirthms like this.
With a two-treatment, two-sequence, one-period, parallel design, bear deploys the linear mixed
effect model (lme). The statistical model includes a factor regarding only one source of variation -
treatment. There are no sources of variation associated with sequence or period because there are no
sequences or periods in a parallel design. Moreover, lme in nlme package is used to obtain estimates
for the adjusted differences between treatment means and the standard error. Log-transformed BA
measures will also be analyzed.
ParaARSdemo Adjusted R squared (ARS) method for demo function for parallel study
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
ParaARSoutput Output for Adjusted R squared (ARS) method for parallel study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
Paradata 67
Paradata Sample size estimation for log transformation data for parallel study
Description
This function will help you to choose appropriate sample size.
References
1. Hauschke D, Steinijans VW, Diletti E and Burke M. Sample size determination for bioequiva-
lence assessment using a multiplicative model. J. Pharmacokin. Biopharm. 20:557-561 (1992). 2.
Julious SA. Tutorial in biostatistics: Sample sizes for clinical trials with normal data. Statist. Med.
23:1921-1986 (2004)
Parademomenu menu for NCA demo le for parallel study
Description
lambda z est. from the exact 3 data points, lambda z est. with adjusted R sq. (ARS), lambda z
est. with Akaike information criterion (AIC), lambda z est. with Two-Times-Tmax method (TTT),
lambda z est. with TTT and ARS, lambda z est. with TTT and AIC
Parademomenu1 menu for NCA->Statistical analysis demo le for parallel study
Description
lambda z est. from the exact 3 data points> Statistical analysis, lambda z est. with adjusted R sq.
(ARS)> Statistical analysis, lambda z est. with Akaike information criterion (AIC)> Statistical
analysis, lambda z est. with Two-Times-Tmax method (TTT)> Statistical analysis, lambda z est.
with TTT and ARS> Statistical analysis, lambda z est. with TTT and AIC> Statistical analysis,
ParademoMIX Statistical analysis (lme, 90CI...)for demo le for parallel study
Description
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
68 ParaMIXanalyze
Paralleldata Data for NCA analyze for parallel study
Description
The data give the data of subjects, drug, time, and concentration.
Paramenu List of NCA 2x2x1 Menu
Description
You can use the functions as follows: 1.run NCA 2.Demo for NCA
ParaMIX Statistical analysis (lme, 90CI...) for parallel study
Description
With a two-treatment, two-sequence, one-period, parallel design, bear deploys the linear mixed
effect model (lme). The statistical model includes a factor regarding only one source of variation -
treatment. There are no sources of variation associated with sequence or period because there are no
sequences or periods in a parallel design. Moreover, lme in nlme package is used to obtain estimates
for the adjusted differences between treatment means and the standard error. Log-transformed BA
measures will also be analyzed.
ParaMIXanalyze Split data to perform lme function for parallel study
Description
Split data for lme function
References
Guidance for Industry. Statistical approaches to establishing Bioequivalence.
ParaMIXcsv 69
ParaMIXcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
ParaMIXdata Input/Edit data for lme function for parallel study
Description
->subject no.(subj) ->drug 1:Reference 2:Test ->Cmax ->AUC0t: area under the predicted plasma
concentration time curve for test data. (time = 0 to t) ->AUC0INF: area under the predicted plasma
concentration time curve for test data. (time = 0 to innity) ->LnCmax: Log-transformed Cmax
->LnAUC0t: Log-transformed AUC0t ->LnAUC0INF: Log-transformed AUC0INF
ParaMIXmenu List of lme Menu
Description
You can use the functions as follows: 1.Statistical analysis (lme, 90CI...) 2.Demo for Statistical
analysis (lme, 90CI...)
ParaMIXoutput Output of lme function
Description
We provides several txt outputs. 1.lme stat.txt >lme:Cmax, AUC0t, AUC0inf, ln(Cmax), ln(AUC0t),
ln(AUC0inf) >90CI: ln(Cmax), ln(AUC0t), and ln(AUC0inf)
ParaNCA Noncompartmental analysis (NCA) for parallel study
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
70 ParaNCA.MIXdata
ParaNCA.MIX NCA and lme for parallel study
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
ParaNCA.MIXanalyze NCA and lme function
Description
This function includes both NCA and lme functions.
ParaNCA.MIXcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
ParaNCA.MIXdata Input/Edit data for NCA and lme function for parallel study
Description
Input/Edit Data ->subject no.(subj) ->drug ref.: 1 test: 2 ->time ->concentration (conc)
ParaNCA.MIXmenu 71
ParaNCA.MIXmenu List of NCA and lme Menu
Description
You can use the functions as follows: 1.NCA>lme 2.Run demo for NCA > Statistical analysis
ParaNCAanalyze NCA analyze function for parallel study
Description
We provide noncompartmental analysis (NCA) approach to compute AUCs and terminal elimina-
tion rate constant (kel) for plasma concentration. Here we provide six methods, exact 3 data points,
ARS, TTT, AIC, TTT and ARS, and TTT and AIC.
ParaNCAcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
ParaNCAdata Input/Edit data for NCA function for parallel study
Description
Input/Edit Data ->subject no.(subj) ->drug ->time ->concentration (conc)
ParaNCAdemo Select the exact 3 data points(NCA) for demo function for parallel
study
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
72 ParaNCAsave
ParaNCAdemo.MIX Select the exact 3 data points(NCA) and lme for demo function
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
ParaNCAoutput Output of NCA for parallel study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
ParaNCAplot NCAplot for parallel study
Description
We provides several pdf. outputs about NCA plots. 1.Conc. vs. Time for individual subjects
2.Log10(Conc.) vs. Time for individual subjects 3.Test (.Conc. vs. Time) for all subjects 4.Refer-
ence (.Conc. vs. Time) for all subjects 5.Conc.(mean+-sd) vs Time for test and reference
ParaNCAsave Save NCA outputs for parallel study
Description
This function can save the results after NCA.
ParaNCAselect 73
ParaNCAselect Select the exact 3 points in NCA for parallel study
Description
This function can help users select the exact 3 points for NCA function.
ParaNCAselect.MIX Select the exact 3 points in NCA and lme for parallel study
Description
This function can help users select the exact 3 points for NCA function.
ParaNCAselectdemo Select the exact 3 points in NCA for demo function for parallel study
Description
This function can help users select the exact 3 points for NCA function.
ParaNCAselectdemo.MIX
Select the exact 3 points in NCA and lme for demo function (parallel
study)
Description
This function can help users select the exact 3 points for NCA function.
ParaNCAselectsave Select the exact 3 points in NCA and Save the data for parallel study
Description
This function can save data of the exact 3 points.
74 ParaTTT.MIX
ParaNCAselectsave.MIX
Select the exact 3 points in NCA and Save the data
Description
This function can save the exact 3 points.
ParaTTT Two Times Tmax (TTT) method for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTT.MIX TTT and lme for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
ParaTTTAIC 75
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTTAIC TTT and AIC for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTTAIC.MIX TTT ,AIC and lme for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
76 ParaTTTAICoutput
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
ParaTTTAICdemo TTT and AIC for demo function for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTTAICoutput Output for TTT and AIC for parallel study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTTARS 77
ParaTTTARS TTT and ARS for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTTARS.MIX TTT ,ARS and lme for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
Statistical analysis (lme, 90CI...): With a two-treatment, two-sequence, one-period, parallel design,
bear deploys the linear mixed effect model (lme). The statistical model includes a factor regarding
only one source of variation - treatment. There are no sources of variation associated with sequence
or period because there are no sequences or periods in a parallel design. Moreover, lme in nlme
package is used to obtain estimates for the adjusted differences between treatment means and the
standard error. Log-transformed BA measures will also be analyzed.
78 ParaTTTARSoutput
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTTARSdemo TTT and ARS for demo function for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTTARSoutput Output for TTT and ARS for parallel study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
ParaTTTdemo 79
ParaTTTdemo Two Times Tmax (TTT) method for demo function for parallel study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
ParaTTToutput Output for Two Times Tmax (TTT) method for parallel study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda, and Cl/F > PKparameter sum-
mary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
plotsingle plot individual data for crossover study
Description
Plot for individual person for BA (conc vs. time) and ln(BA)(lnconc vs. time)
plotsingle.para plot individual data for parallel study
Description
Plot for individual person for BA (conc vs. time) and ln(BA)(lnconc vs. time)
80 RepAIC.MIX
plotsingle.Rep plot individual data for replicated study
Description
Plot for individual person for BA (conc vs. time) and ln(BA)(lnconc vs. time)
prdcount legends for plots
Description
The legend description for replicated study
Repaic Akaike information criterion (AIC) method for replicated study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
RepAIC.MIX Akaike information criterion (AIC) method->statictics for replicated
study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
RepAICdemo 81
RepAICdemo Akaike information criterion (AIC) method for demo function for repli-
cated study
Description
This method selects data points to estimate lambda(z) based on the minimun AIC values. It starts
with the last three data points from the concentration -time prole, performing log-linear regression
to calculate the slope of that tail portion of the concentration-time curve. And then the last 4 data
points, the last 5 data points, on and on until it reaches the data point right after Cmax. Thus, this
method will not include the data point of (Tmax, Cmax).
RepAICoutput Output for Adjusted R squared (ARS) method for replicated study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
RepARS Adjusted R squared (ARS) method for replicated study
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
82 RepARSoutput
RepARS.MIX Adjusted R squared (ARS) method and lme for replicated study
Description
Adjusted R squared (ARS) method: This method selects data points to estimate lambda(z) based on
the maximun adjustedRsqured values. It starts with the last three data points fromthe concentration-
time course, performing log-linear regression to calculate the slope of that tail portion of the
concentration-time curve. And then the last 4 data points, the last 5 data points, on and on un-
til it excludes the data points of Cmax. Thus, this method may exclude the data point of (Tmax,
Cmax). WNL v6. has the similar algoirthms like this.
Statistical analysis (lme, 90CI...): With a two-treatment, more than two period, two-sequence ran-
domized crossover design, linear mixed-effects model may be used. The lme in nlme package is
used to obtain estimates for the adjusted differences between treatment means and the standard error
associated with these differences. Log-transformed BA measures will also be analyzed.
RepARSdemo Adjusted R squared (ARS) method for demo function for replicated
study
Description
This method selects data points to estimate lambda(z) based on the maximun adjustedR squred
values. It starts with the last three data points from the concentration-time course, performing log-
linear regression to calculate the slope of that tail portion of the concentration-time curve. And
then the last 4 data points, the last 5 data points, on and on until it excludes the data points of
Cmax. Thus, this method may exclude the data point of (Tmax, Cmax). WNL v6. has the similar
algoirthms like this.
RepARSoutput Output for Adjusted R squared (ARS) method for replicated study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
Repdemomenu 83
Repdemomenu menu for NCA demo le for replicated study
Description
lambda z est. from the exact 3 data points, lambda z est. with adjusted R sq. (ARS), lambda z
est. with Akaike information criterion (AIC), lambda z est. with Two-Times-Tmax method (TTT),
lambda z est. with TTT and ARS, lambda z est. with TTT and AIC
Repdemomenu1 menu for NCA->Statistical analysis demo le for replicated study
Description
lambda z est. from the exact 3 data points> Statistical analysis, lambda z est. with adjusted R sq.
(ARS)> Statistical analysis, lambda z est. with Akaike information criterion (AIC)> Statistical
analysis, lambda z est. with Two-Times-Tmax method (TTT)> Statistical analysis, lambda z est.
with TTT and ARS> Statistical analysis, lambda z est. with TTT and AIC> Statistical analysis,
RepdemoMIX Statistical analysis (lme, 90CI...)for demo le for replicated study
Description
Statistical analysis (lme, 90CI...): With a two-treatment, more than two period, two-sequence ran-
domized crossover design, linear mixed-effects model may be used. The lme in nlme package is
used to obtain estimates for the adjusted differences between treatment means and the standard error
associated with these differences. Log-transformed BA measures will also be analyzed.
Replicateddata Data for NCA analyze for replicated study
Description
The data give the data of subjects, drug, sequence, period, time, and concentration.
84 RepMIXcsv
Repmenu List of NCA 2x2xn Menu
Description
You can use the functions as follows: 1.run NCA 2.Demo for NCAe
RepMIX Statistical analysis (lme, 90CI...) for replicated study
Description
With a two-treatment, more than two period, two-sequence randomized crossover design, linear
mixed-effects model may be used. The lme in nlme package is used to obtain estimates for the ad-
justed differences between treatment means and the standard error associated with these differences.
Log-transformed BA measures will also be analyzed.
RepMIXanalyze Split data to perform lme function for replicated study
Description
Split data for lme function
References
Guidance for Industry. Statistical approaches to establishing Bioequivalence.
RepMIXcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
RepMIXdata 85
RepMIXdata Input/Edit data for lme function for replicated study
Description
->subject no.(subj) ->drug 1:Reference 2:Test ->sequence (seq) Sequence 1:Reference>Test se-
quence Sequence 2:Test>Reference sequence ->period (prd) Period 1: rst treatmetn period Pe-
riod 2: second treatmetn period ->Cmax ->AUC0t: area under the predicted plasma concentration
time curve for test data. (time = 0 to t) ->AUC0INF: area under the predicted plasma concentration
time curve for test data. (time = 0 to innity) ->LnCmax: Log-transformed Cmax ->LnAUC0t:
Log-transformed AUC0t ->LnAUC0INF: Log-transformed AUC0INF
RepMIXmenu List of lme Menu
Description
You can use the functions as follows: 1.Statistical analysis (lme, 90CI...) 2.Demo for Statistical
analysis (lme, 90CI...)
RepMIXoutput Output of lme function
Description
We provides several txt outputs. 1.lme stat.txt >lme:Cmax, AUC0t, AUC0inf, ln(Cmax), ln(AUC0t),
ln(AUC0inf) >90CI: ln(Cmax), ln(AUC0t), and ln(AUC0inf)
RepNCA Noncompartmental analysis (NCA) for replicated study
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
86 RepNCA.MIXdata
RepNCA.MIX NCA and lme for replicated study
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (lme, 90CI...): With a two-treatment, more than two period, two-sequence ran-
domized crossover design, linear mixed-effects model may be used. The lme in nlme package is
used to obtain estimates for the adjusted differences between treatment means and the standard error
associated with these differences. Log-transformed BA measures will also be analyzed.
RepNCA.MIXanalyze NCA and lme function
Description
This function includes both NCA and lme functions.
RepNCA.MIXcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
RepNCA.MIXdata Input/Edit data for NCA and lme function for replicated study
Description
Input/Edit Data ->subject no.(subj) ->sequence (seq) ->period (prd) Period 1: rst treatmetn period
Period 2: second treatmetn period ->drug ->time ->concentration (conc)
RepNCA.MIXmenu 87
RepNCA.MIXmenu List of NCA and lme Menu
Description
You can use the functions as follows: 1.NCA>lme 2.Run demo for NCA > Statistical analysis
RepNCAanalyze NCA analyze function for replicated study
Description
We provide noncompartmental analysis (NCA) approach to compute AUCs and terminal elimina-
tion rate constant (kel) for plasma concentration. Here we provide six methods, exact 3 data points,
ARS, TTT, AIC, TTT and ARS, and TTT and AIC.
RepNCAcsv choose separator and decimal type
Description
Separator : comma, semicolon ,white space. Decimal: comma, point.
RepNCAdata Input/Edit data for NCA function for replicated study
Description
Input/Edit Data ->subject no.(subj) ->sequence (seq) Sequence 1:Reference>Test sequence Se-
quence 2:Test>Reference sequence ->period (prd) Period 1: rst treatmetn period Period 2: second
treatmetn period ->drug ->time ->concentration (conc)
RepNCAdemo Select the exact 3 data points(NCA) for demo function for replicated
study
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
88 RepNCAsave
RepNCAdemo.MIX Select the exact 3 data points(NCA) and lme for demo function
Description
Noncompartmental analysis (NCA) approach is used to compute AUCs and the terminal elimination
rate constants (lambda z) for drug plasma concentration. The linear trapezoidal method is applied
to calculate AUC(time 0 to the last measurable Cp). The extrapolated AUC (from time of the last
measurable Cp to time innity) is equal to the last measurable Cp divided by lambda z.
Statistical analysis (lme, 90CI...): With a two-treatment, more than two period, two-sequence ran-
domized crossover design, linear mixed-effects model may be used. The lme in nlme package is
used to obtain estimates for the adjusted differences between treatment means and the standard error
associated with these differences. Log-transformed BA measures will also be analyzed.
RepNCAoutput Output of NCA for replicated study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
RepNCAplot NCAplot for replicated study
Description
We provides several pdf. outputs about NCA plots. 1.Conc. vs. Time for individual subjects
2.Log10(Conc.) vs. Time for individual subjects 3.Test (.Conc. vs. Time) for all subjects 4.Refer-
ence (.Conc. vs. Time) for all subjects 5.Conc.(mean+-sd) vs Time for test and reference
RepNCAsave Save NCA outputs for replicated study
Description
This function can save the results after NCA.
RepNCAselect 89
RepNCAselect Select the exact 3 points in NCA for replicated study
Description
This function can help users select the exact 3 points for NCA function.
RepNCAselect.MIX Select the exact 3 points in NCA and lme for replicated study
Description
This function can help users select the exact 3 points for NCA function.
RepNCAselectdemo Select the exact 3 points in NCA for demo function for replicated study
Description
This function can help users select the exact 3 points for NCA function.
RepNCAselectdemo.MIX
Select the exact 3 points in NCA and lme for demo function (replicated
study)
Description
This function can help users select the exact 3 points for NCA function.
RepNCAselectsave Select the exact 3 points in NCA and Save the data for replicated study
Description
This function can save data of the exact 3 points.
90 RepTTT.MIX
RepNCAselectsave.MIX
Select the exact 3 points in NCA and Save the data
Description
This function can save the exact 3 points.
RepTTT Two Times Tmax (TTT) method for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTT.MIX TTT and lme for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
With a two-treatment, more than two period, two-sequence randomized crossover design, linear
mixed-effects model may be used. The lme in nlme package is used to obtain estimates for the ad-
justed differences between treatment means and the standard error associated with these differences.
Log-transformed BA measures will also be analyzed.
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTTAIC 91
RepTTTAIC TTT and AIC for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTTAIC.MIX TTT ,AIC and lme for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
With a two-treatment, more than two period, two-sequence randomized crossover design, linear
mixed-effects model may be used. The lme in nlme package is used to obtain estimates for the ad-
justed differences between treatment means and the standard error associated with these differences.
Log-transformed BA measures will also be analyzed.
92 RepTTTAICoutput
RepTTTAICdemo TTT and AIC for demo function for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTTAICoutput Output for TTT and AIC for replicated study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTTARS 93
RepTTTARS TTT and ARS for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTTARS.MIX TTT ,ARS and lme for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
With a two-treatment, more than two period, two-sequence randomized crossover design, linear
mixed-effects model may be used. The lme in nlme package is used to obtain estimates for the ad-
justed differences between treatment means and the standard error associated with these differences.
Log-transformed BA measures will also be analyzed.
94 RepTTTARSoutput
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTTARSdemo TTT and ARS for demo function for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTTARSoutput Output for TTT and ARS for replicated study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
RepTTTdemo 95
RepTTTdemo Two Times Tmax (TTT) method for demo function for replicated study
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
RepTTToutput Output for Two Times Tmax (TTT) method for replicated study
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda, and Cl/F > PKparameter sum-
mary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
Singlego List of bear Menu
Description
You can use the functions as follows: 1.Sample size estimation for average BE 2.Noncompartment
Analysis (NCA) 3.ANOVA 4.NCA->ANOVA
sizemenu List of Sample size estimation Menu
Description
You can use the functions as follows: 1.Sample size estimation (Raw data) 2.Sample size estimation
(Log transformation) 3.Demo for sample size estimation (Raw data)
96 TTT
stat1menu List of Statistical analysis non-replicated and replicated study
Description
You can use the functions as follows: 1. Statistical analysis for non-replicated crossover study, 2.
Statistical analysis for replicated crossover study,
statmenu List of Statistical analysis non-replicated and replicated study
Description
You can use the functions as follows: 1. Statistical analysis for non-replicated crossover study, 2.
Statistical analysis for replicated crossover study,
TotalSingledata Data for NCA analyze
Description
The data give the data of subjects, drug, sequence, period, time, and concentration.
TTT Two Times Tmax (TTT) method
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
TTT.BANOVA 97
TTT.BANOVA TTT and ANOVA
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
TTTAIC TTT and AIC
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
98 TTTAICdemo
TTTAIC.BANOVA TTT ,AIC and ANOVA
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
TTTAICdemo TTT and AIC for demo function
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply minimun AIC values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
TTTAICoutput 99
TTTAICoutput Output for TTT and AIC
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
TTTARS TTT and ARS
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
100 TTTARSdemo
TTTARS.BANOVA TTT ,ARS and ANOVA
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
TTTARSdemo TTT and ARS for demo function
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Then, within that range, we apply maximun ARS values to get best t. It starts with the last three
data points from the concentration-time prole, performing log-linear regression to calculate the
slope of that tail portion of the concentration- time curve. And then the last 4 data points, the last
5 data points, on and on until it reaches the data point right after Cmax. Thus, this method will not
include the data point of (Tmax, Cmax).
TTTARSoutput 101
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
TTTARSoutput Output for TTT and ARS
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda z, and Cl/F > PK parameter
summary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and
mean conc. plots.
3. Statistical summaries.txt
References
Scheerans C, Derendorf H and C Kloft. Proposal for a Standardised Identication of the Mono-
Exponential Terminal Phase for Orally Administered Drugs. Biopharm Drug Dispos 29, 145-157
(2008).
TTTdemo Two Times Tmax (TTT) method for demo function
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
102 ytick
TTTdemo.BANOVA Two Times Tmax (TTT) method and ANOVA for demo function
Description
The TTT method is based on the Bateman function. The Bateman function has two outstanding
points. First, the maximum of the curve (Cmax at Tmax) and secondly, the inection point of the
curve (Cinpt at Tinpt). The inection point of the curve describes the point where the algebraic sign
of the curvature changes. Tinpt is equal to two times Tmax. Thus, The twofold of the observed
Tmax value can be used as a threshold of time points to be included in the calculation of lambda(z).
Statistical analysis (ANOVA(lm), 90CI...): With a two-treatment, two-period, two-sequence ran-
domized crossover design, ANOVA statistical model includes factors of the following sources:
sequence, subjects nested in sequences, period and treatment. ANOVA will be applied to obtain
estimates for the adjusted differences between treatment means and the standard error associated
with these differences. Log-transformed BA measures will also be analyzed.
TTToutput Output for Two Times Tmax (TTT) method
Description
We provides several txt outputs. 1. NCAPK.txt: > Cmax, Tmax, AUC0t, AUC0inf, AUC0t/AUC0inf,
ln(Cmax), ln(AUC0t), ln(AUC0inf), MRT0inf, T1/2, Vd/F, lambda, and Cl/F > PKparameter sum-
mary (NCA outputs) 2. plots.pdf: individual linear and semilog plots, spaghetti plots, and mean
conc. plots.
3. Statistical summaries.txt
xtick x-tick
Description
Tick for plots.
ytick y-tick
Description
Tick for plots.
Index
Topic misc
aic, 1
AIC_BANOVA, 2
AICdemo, 2
AICoutput, 2
ARS, 3
ARS.BANOVA, 3
ARSdemo, 3
ARSdemo.BANOVA, 4
ARSoutput, 4
BANOVA, 4
BANOVAanalyze, 5
BANOVAcsv, 5
BANOVAdata, 5
BANOVAmenu, 6
BANOVAoutput, 6
BANOVAplot, 6
bye, 6
demoBANOVA, 7
demomenu, 7
demomenu1, 7
demopara, 7
demosize, 8
description_AIC, 8
description_ARS, 8
description_BANOVA, 8
description_drug, 9
description_drugcode, 9
description_import, 9
description_load, 9
description_Multipledrugcode,
9
description_NCA, 10
description_NCAcsv, 10
description_NCAinput, 10
description_ParaMIX, 10
description_ParaNCAcsv, 11
description_ParaNCAinput, 11
description_plot, 11
description_Repdrugcode, 11
description_RepMIX, 12
description_RepNCAcsv, 12
description_RepNCAinput, 12
description_size, 12
description_size_para, 13
description_TOST1_lnAUC0INF,
13
description_TOST1_lnAUC0t, 13
description_TOST1_lnCmax, 14
description_TOST_lnAUC0INF,
14
description_TOST_lnAUC0t, 15
description_TOST_lnCmax, 15
description_TTT, 16
description_TTTAIC, 16
description_TTTARS, 17
description_version, 17
entertitle, 17
entertitle.demo, 17
go, 18
logdata, 18
Multiple1menu, 18
Multipleaic, 19
MultipleAIC_BANOVA, 20
MultipleAICdemo, 19
MultipleAICoutput, 19
MultipleARS, 20
MultipleARS.BANOVA, 20
MultipleARSdemo, 21
MultipleARSoutput, 21
MultipleBANOVA, 21
MultipleBANOVAanalyze, 22
MultipleBANOVAcsv, 22
MultipleBANOVAdata, 22
MultipleBANOVAmenu, 22
MultipleBANOVAoutput, 23
MultipleBANOVAplot, 23
Multipledata, 23
103
104 INDEX
MultipledemoBANOVA, 23
Multipledemomenu, 24
Multipledemomenu1, 24
Multiplego, 24
Multiplemenu, 24
MultipleNCA, 25
MultipleNCA.BANOVA, 25
MultipleNCA.BANOVAanalyze, 25
MultipleNCA.BANOVAcsv, 25
MultipleNCA.BANOVAdata, 26
MultipleNCA.BANOVAmenu, 26
MultipleNCAanalyze, 26
MultipleNCAcsv, 26
MultipleNCAdata, 27
MultipleNCAdemo, 27
MultipleNCAdemo.BANOVA, 27
MultipleNCAmenu, 27
MultipleNCAoutput, 28
MultipleNCAplot, 28
MultipleNCAsave, 28
MultipleNCAselect, 28
MultipleNCAselect.BANOVA, 28
MultipleNCAselectdemo, 29
MultipleNCAselectdemo.BANOVA,
29
MultipleNCAselectsave, 29
MultipleNCAselectsave.BANOVA,
29
Multiplentertitle, 29
Multiplentertitle.demo, 30
MultipleParaAIC, 30
MultipleParaAIC.MIX, 30
MultipleParaAICdemo, 31
MultipleParaAICoutput, 31
MultipleParaARS, 31
MultipleParaARS.MIX, 32
MultipleParaARSdemo, 32
MultipleParaARSoutput, 32
MultipleParadata, 33
MultipleParademomenu, 33
MultipleParademomenu1, 33
MultipleParademoMIX, 33
MultipleParamenu, 34
MultipleParaMIX, 34
MultipleParaMIXanalyze, 34
MultipleParaMIXcsv, 34
MultipleParaMIXdata, 35
MultipleParaMIXmenu, 35
MultipleParaMIXoutput, 35
MultipleParaNCA, 35
MultipleParaNCA.MIX, 36
MultipleParaNCA.MIXanalyze,
36
MultipleParaNCA.MIXcsv, 36
MultipleParaNCA.MIXdata, 36
MultipleParaNCA.MIXmenu, 37
MultipleParaNCAanalyze, 37
MultipleParaNCAcsv, 37
MultipleParaNCAdata, 37
MultipleParaNCAdemo, 38
MultipleParaNCAdemo.MIX, 38
MultipleParaNCAoutput, 38
MultipleParaNCAplot, 39
MultipleParaNCAsave, 39
MultipleParaNCAselect, 39
MultipleParaNCAselect.MIX, 39
MultipleParaNCAselectdemo, 39
MultipleParaNCAselectdemo.MIX,
40
MultipleParaNCAselectsave, 40
MultipleParaNCAselectsave.MIX,
40
MultipleParaTTT, 40
MultipleParaTTT.MIX, 41
MultipleParaTTTAIC, 41
MultipleParaTTTAIC.MIX, 42
MultipleParaTTTAICdemo, 42
MultipleParaTTTAICoutput, 43
MultipleParaTTTARS, 43
MultipleParaTTTARS.MIX, 44
MultipleParaTTTARSdemo, 44
MultipleParaTTTARSoutput, 45
MultipleParaTTTdemo, 45
MultipleParaTTToutput, 45
Multipleplotsingle, 46
Multipleplotsingle.para, 46
Multiplestat1menu, 46
Multiplestatmenu, 46
MultipleTTT, 47
MultipleTTT.BANOVA, 47
MultipleTTTAIC, 48
MultipleTTTAIC.BANOVA, 48
MultipleTTTAICdemo, 49
MultipleTTTAICoutput, 49
MultipleTTTARS, 50
MultipleTTTARS.BANOVA, 50
INDEX 105
MultipleTTTARSdemo, 51
MultipleTTTARSoutput, 51
MultipleTTTdemo, 52
MultipleTTToutput, 52
NCA, 52
NCA.BANOVA, 53
NCA.BANOVAanalyze, 53
NCA.BANOVAcsv, 53
NCA.BANOVAdata, 53
NCA.BANOVAmenu, 54
NCAanalyze, 54
NCAcsv, 54
NCAdata, 54
NCAdemo, 54
NCAdemo.BANOVA, 55
NCAmenu, 55
NCAoutput, 55
NCAplot, 55
NCAsave, 56
NCAselect, 56
NCAselect.BANOVA, 56
NCAselectdemo, 56
NCAselectdemo.BANOVA, 56
NCAselectsave, 57
NCAselectsave.BANOVA, 57
ParaAIC, 57
ParaAIC.MIX, 57
ParaAICdemo, 58
ParaAICoutput, 58
ParaARS, 58
ParaARS.MIX, 59
ParaARSdemo, 59
ParaARSoutput, 59
Paradata, 60
Parademomenu, 60
Parademomenu1, 60
ParademoMIX, 60
Paralleldata, 61
Paramenu, 61
ParaMIX, 61
ParaMIXanalyze, 61
ParaMIXcsv, 62
ParaMIXdata, 62
ParaMIXmenu, 62
ParaMIXoutput, 62
ParaNCA, 62
ParaNCA.MIX, 63
ParaNCA.MIXanalyze, 63
ParaNCA.MIXcsv, 63
ParaNCA.MIXdata, 63
ParaNCA.MIXmenu, 64
ParaNCAanalyze, 64
ParaNCAcsv, 64
ParaNCAdata, 64
ParaNCAdemo, 64
ParaNCAdemo.MIX, 65
ParaNCAoutput, 65
ParaNCAplot, 65
ParaNCAsave, 65
ParaNCAselect, 66
ParaNCAselect.MIX, 66
ParaNCAselectdemo, 66
ParaNCAselectdemo.MIX, 66
ParaNCAselectsave, 66
ParaNCAselectsave.MIX, 67
ParaTTT, 67
ParaTTT.MIX, 67
ParaTTTAIC, 68
ParaTTTAIC.MIX, 68
ParaTTTAICdemo, 69
ParaTTTAICoutput, 69
ParaTTTARS, 70
ParaTTTARS.MIX, 70
ParaTTTARSdemo, 71
ParaTTTARSoutput, 71
ParaTTTdemo, 72
ParaTTToutput, 72
plotsingle, 72
plotsingle.para, 72
plotsingle.Rep, 73
prdcount, 73
Repaic, 73
RepAIC.MIX, 73
RepAICdemo, 74
RepAICoutput, 74
RepARS, 74
RepARS.MIX, 75
RepARSdemo, 75
RepARSoutput, 75
Repdemomenu, 76
Repdemomenu1, 76
RepdemoMIX, 76
Replicateddata, 76
Repmenu, 77
RepMIX, 77
RepMIXanalyze, 77
106 INDEX
RepMIXcsv, 77
RepMIXdata, 78
RepMIXmenu, 78
RepMIXoutput, 78
RepNCA, 78
RepNCA.MIX, 79
RepNCA.MIXanalyze, 79
RepNCA.MIXcsv, 79
RepNCA.MIXdata, 79
RepNCA.MIXmenu, 80
RepNCAanalyze, 80
RepNCAcsv, 80
RepNCAdata, 80
RepNCAdemo, 80
RepNCAdemo.MIX, 81
RepNCAoutput, 81
RepNCAplot, 81
RepNCAsave, 81
RepNCAselect, 82
RepNCAselect.MIX, 82
RepNCAselectdemo, 82
RepNCAselectdemo.MIX, 82
RepNCAselectsave, 82
RepNCAselectsave.MIX, 83
RepTTT, 83
RepTTT.MIX, 83
RepTTTAIC, 84
RepTTTAIC.MIX, 84
RepTTTAICdemo, 85
RepTTTAICoutput, 85
RepTTTARS, 86
RepTTTARS.MIX, 86
RepTTTARSdemo, 87
RepTTTARSoutput, 87
RepTTTdemo, 88
RepTTToutput, 88
Singlego, 88
sizemenu, 88
stat1menu, 89
statmenu, 89
TotalSingledata, 89
TTT, 89
TTT.BANOVA, 90
TTTAIC, 90
TTTAIC.BANOVA, 91
TTTAICdemo, 91
TTTAICoutput, 92
TTTARS, 92
TTTARS.BANOVA, 93
TTTARSdemo, 93
TTTARSoutput, 94
TTTdemo, 94
TTTdemo.BANOVA, 95
TTToutput, 95
xtick, 95
ytick, 95
aic, 1
AIC_BANOVA, 2
AICdemo, 2
AICoutput, 2
ARS, 3
ARS.BANOVA, 3
ARSdemo, 3
ARSdemo.BANOVA, 4
ARSoutput, 4
BANOVA, 4
BANOVAanalyze, 5
BANOVAcsv, 5
BANOVAdata, 5
BANOVAmenu, 6
BANOVAoutput, 6
BANOVAplot, 6
bye, 6
demoBANOVA, 7
demomenu, 7
demomenu1, 7
demopara, 7
demosize, 8
description_AIC, 8
description_ARS, 8
description_BANOVA, 8
description_drug, 9
description_drugcode, 9
description_import, 9
description_load, 9
description_Multipledrugcode, 9
description_NCA, 10
description_NCAcsv, 10
description_NCAinput, 10
description_ParaMIX, 10
description_ParaNCAcsv, 11
description_ParaNCAinput, 11
description_plot, 11
description_Repdrugcode, 11
INDEX 107
description_RepMIX, 12
description_RepNCAcsv, 12
description_RepNCAinput, 12
description_size, 12
description_size_para, 13
description_TOST1_lnAUC0INF, 13
description_TOST1_lnAUC0t, 13
description_TOST1_lnCmax, 14
description_TOST_lnAUC0INF, 14
description_TOST_lnAUC0t, 15
description_TOST_lnCmax, 15
description_TTT, 16
description_TTTAIC, 16
description_TTTARS, 17
description_version, 17
entertitle, 17
entertitle.demo, 17
go, 18
logdata, 18
Multiple1menu, 18
Multipleaic, 19
MultipleAIC_BANOVA, 20
MultipleAICdemo, 19
MultipleAICoutput, 19
MultipleARS, 20
MultipleARS.BANOVA, 20
MultipleARSdemo, 21
MultipleARSoutput, 21
MultipleBANOVA, 21
MultipleBANOVAanalyze, 22
MultipleBANOVAcsv, 22
MultipleBANOVAdata, 22
MultipleBANOVAmenu, 22
MultipleBANOVAoutput, 23
MultipleBANOVAplot, 23
Multipledata, 23
MultipledemoBANOVA, 23
Multipledemomenu, 24
Multipledemomenu1, 24
Multiplego, 24
Multiplemenu, 24
MultipleNCA, 25
MultipleNCA.BANOVA, 25
MultipleNCA.BANOVAanalyze, 25
MultipleNCA.BANOVAcsv, 25
MultipleNCA.BANOVAdata, 26
MultipleNCA.BANOVAmenu, 26
MultipleNCAanalyze, 26
MultipleNCAcsv, 26
MultipleNCAdata, 27
MultipleNCAdemo, 27
MultipleNCAdemo.BANOVA, 27
MultipleNCAmenu, 27
MultipleNCAoutput, 28
MultipleNCAplot, 28
MultipleNCAsave, 28
MultipleNCAselect, 28
MultipleNCAselect.BANOVA, 28
MultipleNCAselectdemo, 29
MultipleNCAselectdemo.BANOVA, 29
MultipleNCAselectsave, 29
MultipleNCAselectsave.BANOVA, 29
Multiplentertitle, 29
Multiplentertitle.demo, 30
MultipleParaAIC, 30
MultipleParaAIC.MIX, 30
MultipleParaAICdemo, 31
MultipleParaAICoutput, 31
MultipleParaARS, 31
MultipleParaARS.MIX, 32
MultipleParaARSdemo, 32
MultipleParaARSoutput, 32
MultipleParadata, 33
MultipleParademomenu, 33
MultipleParademomenu1, 33
MultipleParademoMIX, 33
MultipleParamenu, 34
MultipleParaMIX, 34
MultipleParaMIXanalyze, 34
MultipleParaMIXcsv, 34
MultipleParaMIXdata, 35
MultipleParaMIXmenu, 35
MultipleParaMIXoutput, 35
MultipleParaNCA, 35
MultipleParaNCA.MIX, 36
MultipleParaNCA.MIXanalyze, 36
MultipleParaNCA.MIXcsv, 36
MultipleParaNCA.MIXdata, 36
MultipleParaNCA.MIXmenu, 37
MultipleParaNCAanalyze, 37
MultipleParaNCAcsv, 37
MultipleParaNCAdata, 37
MultipleParaNCAdemo, 38
108 INDEX
MultipleParaNCAdemo.MIX, 38
MultipleParaNCAoutput, 38
MultipleParaNCAplot, 39
MultipleParaNCAsave, 39
MultipleParaNCAselect, 39
MultipleParaNCAselect.MIX, 39
MultipleParaNCAselectdemo, 39
MultipleParaNCAselectdemo.MIX, 40
MultipleParaNCAselectsave, 40
MultipleParaNCAselectsave.MIX, 40
MultipleParaTTT, 40
MultipleParaTTT.MIX, 41
MultipleParaTTTAIC, 41
MultipleParaTTTAIC.MIX, 42
MultipleParaTTTAICdemo, 42
MultipleParaTTTAICoutput, 43
MultipleParaTTTARS, 43
MultipleParaTTTARS.MIX, 44
MultipleParaTTTARSdemo, 44
MultipleParaTTTARSoutput, 45
MultipleParaTTTdemo, 45
MultipleParaTTToutput, 45
Multipleplotsingle, 46
Multipleplotsingle.para, 46
Multiplestat1menu, 46
Multiplestatmenu, 46
MultipleTTT, 47
MultipleTTT.BANOVA, 47
MultipleTTTAIC, 48
MultipleTTTAIC.BANOVA, 48
MultipleTTTAICdemo, 49
MultipleTTTAICoutput, 49
MultipleTTTARS, 50
MultipleTTTARS.BANOVA, 50
MultipleTTTARSdemo, 51
MultipleTTTARSoutput, 51
MultipleTTTdemo, 52
MultipleTTToutput, 52
NCA, 52
NCA.BANOVA, 53
NCA.BANOVAanalyze, 53
NCA.BANOVAcsv, 53
NCA.BANOVAdata, 53
NCA.BANOVAmenu, 54
NCAanalyze, 54
NCAcsv, 54
NCAdata, 54
NCAdemo, 54
NCAdemo.BANOVA, 55
NCAmenu, 55
NCAoutput, 55
NCAplot, 55
NCAsave, 56
NCAselect, 56
NCAselect.BANOVA, 56
NCAselectdemo, 56
NCAselectdemo.BANOVA, 56
NCAselectsave, 57
NCAselectsave.BANOVA, 57
ParaAIC, 57
ParaAIC.MIX, 57
ParaAICdemo, 58
ParaAICoutput, 58
ParaARS, 58
ParaARS.MIX, 59
ParaARSdemo, 59
ParaARSoutput, 59
Paradata, 60
Parademomenu, 60
Parademomenu1, 60
ParademoMIX, 60
Paralleldata, 61
Paramenu, 61
ParaMIX, 61
ParaMIXanalyze, 61
ParaMIXcsv, 62
ParaMIXdata, 62
ParaMIXmenu, 62
ParaMIXoutput, 62
ParaNCA, 62
ParaNCA.MIX, 63
ParaNCA.MIXanalyze, 63
ParaNCA.MIXcsv, 63
ParaNCA.MIXdata, 63
ParaNCA.MIXmenu, 64
ParaNCAanalyze, 64
ParaNCAcsv, 64
ParaNCAdata, 64
ParaNCAdemo, 64
ParaNCAdemo.MIX, 65
ParaNCAoutput, 65
ParaNCAplot, 65
ParaNCAsave, 65
ParaNCAselect, 66
ParaNCAselect.MIX, 66
ParaNCAselectdemo, 66
INDEX 109
ParaNCAselectdemo.MIX, 66
ParaNCAselectsave, 66
ParaNCAselectsave.MIX, 67
ParaTTT, 67
ParaTTT.MIX, 67
ParaTTTAIC, 68
ParaTTTAIC.MIX, 68
ParaTTTAICdemo, 69
ParaTTTAICoutput, 69
ParaTTTARS, 70
ParaTTTARS.MIX, 70
ParaTTTARSdemo, 71
ParaTTTARSoutput, 71
ParaTTTdemo, 72
ParaTTToutput, 72
plotsingle, 72
plotsingle.para, 72
plotsingle.Rep, 73
prdcount, 73
Repaic, 73
RepAIC.MIX, 73
RepAICdemo, 74
RepAICoutput, 74
RepARS, 74
RepARS.MIX, 75
RepARSdemo, 75
RepARSoutput, 75
Repdemomenu, 76
Repdemomenu1, 76
RepdemoMIX, 76
Replicateddata, 76
Repmenu, 77
RepMIX, 77
RepMIXanalyze, 77
RepMIXcsv, 77
RepMIXdata, 78
RepMIXmenu, 78
RepMIXoutput, 78
RepNCA, 78
RepNCA.MIX, 79
RepNCA.MIXanalyze, 79
RepNCA.MIXcsv, 79
RepNCA.MIXdata, 79
RepNCA.MIXmenu, 80
RepNCAanalyze, 80
RepNCAcsv, 80
RepNCAdata, 80
RepNCAdemo, 80
RepNCAdemo.MIX, 81
RepNCAoutput, 81
RepNCAplot, 81
RepNCAsave, 81
RepNCAselect, 82
RepNCAselect.MIX, 82
RepNCAselectdemo, 82
RepNCAselectdemo.MIX, 82
RepNCAselectsave, 82
RepNCAselectsave.MIX, 83
RepTTT, 83
RepTTT.MIX, 83
RepTTTAIC, 84
RepTTTAIC.MIX, 84
RepTTTAICdemo, 85
RepTTTAICoutput, 85
RepTTTARS, 86
RepTTTARS.MIX, 86
RepTTTARSdemo, 87
RepTTTARSoutput, 87
RepTTTdemo, 88
RepTTToutput, 88
Singlego, 88
sizemenu, 88
stat1menu, 89
statmenu, 89
TotalSingledata, 89
TTT, 89
TTT.BANOVA, 90
TTTAIC, 90
TTTAIC.BANOVA, 91
TTTAICdemo, 91
TTTAICoutput, 92
TTTARS, 92
TTTARS.BANOVA, 93
TTTARSdemo, 93
TTTARSoutput, 94
TTTdemo, 94
TTTdemo.BANOVA, 95
TTToutput, 95
xtick, 95
ytick, 95
You might also like
- Introduction To AlgorithmsDocument769 pagesIntroduction To AlgorithmsShri Man90% (10)
- Gnu AwkDocument89 pagesGnu AwkMiguel OrihuelaNo ratings yet
- How To Set Up A Call Centre From Scratch - The Checklist PDFDocument12 pagesHow To Set Up A Call Centre From Scratch - The Checklist PDFOmar BenkiraneNo ratings yet
- Column RegenerationDocument5 pagesColumn RegenerationAmruta SuryanNo ratings yet
- AWS-Optimizing AWS Cloud Costs and Lowering TCO EbookDocument15 pagesAWS-Optimizing AWS Cloud Costs and Lowering TCO EbookRazvan MunteanuNo ratings yet
- Time ManagementDocument7 pagesTime Managementricha928No ratings yet
- PASWRPROBABILITY and STATISTICS WITH RDocument89 pagesPASWRPROBABILITY and STATISTICS WITH RVibhav Prasad MathurNo ratings yet
- Ts DynDocument86 pagesTs Dynaloo+gubhiNo ratings yet
- Easy CODADocument45 pagesEasy CODAFawzan BhaktiNo ratings yet
- COVID-19 and Mental Health: By: Lorna CollierDocument18 pagesCOVID-19 and Mental Health: By: Lorna CollierOluwadara AkaNo ratings yet
- Fin CalDocument44 pagesFin Calfabricioace1978No ratings yet
- Gnu Awk v2p0Document127 pagesGnu Awk v2p0AlejandroNo ratings yet
- Data Mining 12Document94 pagesData Mining 12CutMelindaNo ratings yet
- QuestionrDocument45 pagesQuestionrkonemina85No ratings yet
- Profile RDocument22 pagesProfile Rsyedwasif moinNo ratings yet
- Package Dplyr': July 21, 2017Document73 pagesPackage Dplyr': July 21, 2017saNo ratings yet
- ReshapeDocument20 pagesReshapemasykur18No ratings yet
- SPL RcompyDocument141 pagesSPL RcompyentewasteNo ratings yet
- FactoMineR PDFDocument100 pagesFactoMineR PDFDidiNo ratings yet
- Package MPV': R Topics DocumentedDocument81 pagesPackage MPV': R Topics DocumentedAyushi MauryaNo ratings yet
- MorphoDocument183 pagesMorphoYosueNo ratings yet
- Package Factominer': R Topics DocumentedDocument100 pagesPackage Factominer': R Topics DocumentedAlejandroNo ratings yet
- R ManualDocument1,378 pagesR Manualsairam781No ratings yet
- R Package SysidDocument37 pagesR Package SysidildenarNo ratings yet
- Eric Redmond John Daily: Basho Basho Basho Basho BashoDocument105 pagesEric Redmond John Daily: Basho Basho Basho Basho Bashopepas12345No ratings yet
- VI DimensionStrings Manual v2Document30 pagesVI DimensionStrings Manual v2Nils Van der PlanckenNo ratings yet
- Package Elorating': R Topics DocumentedDocument26 pagesPackage Elorating': R Topics DocumentedBrian LachNo ratings yet
- TftUV - Official Guide v0.13Document65 pagesTftUV - Official Guide v0.13lboyer04No ratings yet
- Package Phytools': R Topics DocumentedDocument132 pagesPackage Phytools': R Topics Documentedpathanfor786No ratings yet
- Package Dplyr': September 28, 2017Document73 pagesPackage Dplyr': September 28, 2017William RamosNo ratings yet
- Little Riak BookDocument105 pagesLittle Riak BookBilash DashNo ratings yet
- Discrimi NerDocument34 pagesDiscrimi NerSoufiane El KhantoutiNo ratings yet
- Package TSA': R Topics DocumentedDocument79 pagesPackage TSA': R Topics DocumentedOscar José Ospino AyalaNo ratings yet
- BETSDocument54 pagesBETSSeven StreamsNo ratings yet
- GCDkit ManualDocument175 pagesGCDkit ManualRheza FirmansyahNo ratings yet
- Gnu Awk SampleDocument54 pagesGnu Awk SampleNgô Trọng NguyênNo ratings yet
- Package TSA RstudioDocument79 pagesPackage TSA RstudioHospital BasisNo ratings yet
- Package Boa': R Topics DocumentedDocument40 pagesPackage Boa': R Topics DocumentedCristian ArieelNo ratings yet
- CaracasDocument61 pagesCaracasucmatik1043No ratings yet
- 09 - Package Metrics'Document26 pages09 - Package Metrics'alanNo ratings yet
- GNU GREP and RIPGREPDocument111 pagesGNU GREP and RIPGREPSolon CarrenoNo ratings yet
- Yeni Metin BelgesiDocument164 pagesYeni Metin BelgesiAnonymous W4aCgqd5No ratings yet
- R - A Language and Environment For Statistical ComputingDocument1,731 pagesR - A Language and Environment For Statistical ComputingTombadoNo ratings yet
- Facto MinerDocument84 pagesFacto MinerRéda TsouliNo ratings yet
- Package Treeclim': October 8, 2020Document23 pagesPackage Treeclim': October 8, 2020Catalin RoibuNo ratings yet
- Grep v1p5Document111 pagesGrep v1p5joseNo ratings yet
- SitarDocument49 pagesSitarG. SilvaNo ratings yet
- RpartDocument28 pagesRpartGeorge MireaNo ratings yet
- FANTOM-06 07 08 Parameter Eng01 WDocument102 pagesFANTOM-06 07 08 Parameter Eng01 WRaul De SáNo ratings yet
- Package Rfit': R Topics DocumentedDocument35 pagesPackage Rfit': R Topics DocumentedsdsdfsdsNo ratings yet
- Cli Text Processing Coreutils v1p0Document111 pagesCli Text Processing Coreutils v1p0Muhammad Habib MananNo ratings yet
- Para MapDocument29 pagesPara MapananyaajatasatruNo ratings yet
- TswgeDocument157 pagesTswgeHsbs HheNo ratings yet
- Package Astsa': R Topics DocumentedDocument99 pagesPackage Astsa': R Topics DocumentedAloth FuentesNo ratings yet
- Package Bootstrap': R Topics DocumentedDocument28 pagesPackage Bootstrap': R Topics Documentedcamus CaNo ratings yet
- Python Regex v3p2Document113 pagesPython Regex v3p2Frank Weber100% (1)
- Clean Energy Transition November 12 2021Document30 pagesClean Energy Transition November 12 2021HikaruNo ratings yet
- Benford's LawDocument19 pagesBenford's LawRamesh Chandra DasNo ratings yet
- Mess PDFDocument94 pagesMess PDFzethembetholusizoNo ratings yet
- Package Genarise2': R Topics DocumentedDocument34 pagesPackage Genarise2': R Topics DocumentedAnonymous MqprQvjEKNo ratings yet
- Model DataDocument41 pagesModel DataJhon GalvánNo ratings yet
- Package Lfstat': R Topics DocumentedDocument63 pagesPackage Lfstat': R Topics DocumentedLAYANE CARMEM ARRUDA DA ROCHANo ratings yet
- Ts DynDocument93 pagesTs DynDante Palacios ValdiviezoNo ratings yet
- The New Labor Market February 4 2022Document30 pagesThe New Labor Market February 4 2022Hồ Gia LinhNo ratings yet
- Citric Phosphate BufferDocument1 pageCitric Phosphate Bufferhilifemx00No ratings yet
- Biomolecule ChromatographyDocument238 pagesBiomolecule Chromatographyhilifemx00No ratings yet
- Guide To Laboratory Filtration WhatmanDocument2 pagesGuide To Laboratory Filtration Whatmanhilifemx00No ratings yet
- Terms of Reference For Sifmis Implementation Quality Assurance Consultant (Firm)Document8 pagesTerms of Reference For Sifmis Implementation Quality Assurance Consultant (Firm)Oshinfowokan OloladeNo ratings yet
- Liu 2021Document13 pagesLiu 2021dinhcauduong12No ratings yet
- ComputerDocument18 pagesComputeruzoran68No ratings yet
- Autodesk Factory Design Utilities Essentials: Course Length: 4 DaysDocument5 pagesAutodesk Factory Design Utilities Essentials: Course Length: 4 DaysRey Panda RulNo ratings yet
- Chini Chinni Aasa Chinadani AasaDocument3 pagesChini Chinni Aasa Chinadani AasaMastan RaoNo ratings yet
- WMIC Sample OutputDocument1 pageWMIC Sample OutputMarek SokalNo ratings yet
- MCQ CsDocument71 pagesMCQ CspreethiNo ratings yet
- Wireless Programming Project Report 181022090116Document9 pagesWireless Programming Project Report 181022090116Kulveer singhNo ratings yet
- Lecture 2Document61 pagesLecture 2AMBELEMBIJENo ratings yet
- Java Unit-3 Lecture-30 31Document40 pagesJava Unit-3 Lecture-30 31aasthabansal1803No ratings yet
- Distributed SystemsDocument7 pagesDistributed SystemsMurari NayuduNo ratings yet
- How To Integrate Google Drive With OdooDocument13 pagesHow To Integrate Google Drive With OdoorobogormanNo ratings yet
- Online Cosmetics: A Project ReportDocument82 pagesOnline Cosmetics: A Project Reportpraveen goddatiNo ratings yet
- Practical FileDocument79 pagesPractical FileShallu Madan KNo ratings yet
- Touch Less Touch Screen Technology: Rohith 18311A12M1Document21 pagesTouch Less Touch Screen Technology: Rohith 18311A12M1Rishi BNo ratings yet
- SOP For Automation Multiple GRN - HSD - ProcessDocument9 pagesSOP For Automation Multiple GRN - HSD - ProcessVibhor JainNo ratings yet
- Scilab/Scicos Toolboxes For TelecommunicationsDocument15 pagesScilab/Scicos Toolboxes For TelecommunicationsJuanNo ratings yet
- MAC Address and MAC FilteringDocument2 pagesMAC Address and MAC FilteringCleo RubinoNo ratings yet
- FND Lobs PctversionDocument2 pagesFND Lobs PctversionhyddbaNo ratings yet
- Penetratuioin ToolsDocument9 pagesPenetratuioin ToolsMian Talha RiazNo ratings yet
- Reward Your CuriosityDocument1 pageReward Your CuriosityKimjoonsNo ratings yet
- 1st Sem 1st QTR - Week 4-5 Module in Computer Programming JAVA - Modular 11 PagesDocument11 pages1st Sem 1st QTR - Week 4-5 Module in Computer Programming JAVA - Modular 11 PagesJoshua Fandialan MaderaNo ratings yet
- ItpDocument2 pagesItphazim gomer PangodNo ratings yet
- Expressing "Unless" With "Chufei" - Chinese Grammar WikiDocument4 pagesExpressing "Unless" With "Chufei" - Chinese Grammar WikiluffyNo ratings yet
- Digi ClassDocument15 pagesDigi Classsaurabhchhabra01No ratings yet
- CV AbinitioDocument1 pageCV AbinitioSandeep ShawNo ratings yet