You might also like
- SM 2022 S1 Topic 3, 4 and 5 Learning ActivityDocument2 pagesSM 2022 S1 Topic 3, 4 and 5 Learning ActivitynguyenhoangNo ratings yet
- Math 1040 Term Project - Skittles 2Document6 pagesMath 1040 Term Project - Skittles 2api-313998583No ratings yet
- Tim HortonsDocument35 pagesTim Hortons89237284No ratings yet
- Assignment 2 S315Document5 pagesAssignment 2 S315Sadeeq Ul HasnainNo ratings yet
- Million Dollar Project RubricDocument2 pagesMillion Dollar Project Rubricspryaj40No ratings yet
- Data Visualization: Tutorial Dr. John F. TrippDocument51 pagesData Visualization: Tutorial Dr. John F. Tripppreeti agarwalNo ratings yet
- Complete NotesDocument153 pagesComplete NotesSungsoo KimNo ratings yet
- Submitting Future Requests Via Package FND - Request - Submit - RequestDocument2 pagesSubmitting Future Requests Via Package FND - Request - Submit - RequesttracejmNo ratings yet
- SPSS Tutorial 2:: Gender Seen Matrix AgeDocument5 pagesSPSS Tutorial 2:: Gender Seen Matrix AgeArunkumarNo ratings yet
- 6 D 8 e 3 ADocument35 pages6 D 8 e 3 ALuis OliveiraNo ratings yet
- Applied Statistics (Sqqs2013) Group Project (20%) InstructionsDocument6 pagesApplied Statistics (Sqqs2013) Group Project (20%) InstructionsFirdaus LasnangNo ratings yet
- IFM Module Booklet 2014 15Document11 pagesIFM Module Booklet 2014 15EYmran RExa XaYdiNo ratings yet
- PepsicoDocument8 pagesPepsicoramya4upriyaNo ratings yet
- 4570 - 4154 - 119 - 2224 - 86 - Case Based AssingnmentsDocument16 pages4570 - 4154 - 119 - 2224 - 86 - Case Based AssingnmentsLeena Bhatia0% (1)
- Stratford Report Guide 2014Document13 pagesStratford Report Guide 2014api-263335251No ratings yet
- Groups Technical-Functional Sap-Crm MiDocument5 pagesGroups Technical-Functional Sap-Crm MiccodriciNo ratings yet
- A Study On Performance of Ipos in Indian Stock MarketDocument58 pagesA Study On Performance of Ipos in Indian Stock MarketAmit SharmaNo ratings yet
- Chapter 4 of Big BazzarDocument25 pagesChapter 4 of Big Bazzargauravfast77No ratings yet
- Pre Release Material Buss4Document2 pagesPre Release Material Buss4api-246565830No ratings yet
- M - E - GTP 8 Intake Index 1: PART I: (Please Answer On The QUESTION SHEET)Document8 pagesM - E - GTP 8 Intake Index 1: PART I: (Please Answer On The QUESTION SHEET)Hoang NguyenNo ratings yet
- NicaraguaDataCollectionFile Employees EnglishDocument107 pagesNicaraguaDataCollectionFile Employees EnglishmarooharshNo ratings yet
- Marketing Research and Technology: MKT 550 Tuesday, 6:00 - 8:45 PM Fall 2004Document7 pagesMarketing Research and Technology: MKT 550 Tuesday, 6:00 - 8:45 PM Fall 2004aldehyde27No ratings yet
- Statistical Data / Periodicals Usage Survey: Check You Are Commenting UponDocument2 pagesStatistical Data / Periodicals Usage Survey: Check You Are Commenting UponFaisal AwanNo ratings yet
- Resume MudassarKhattabDocument2 pagesResume MudassarKhattabJessica ThompsonNo ratings yet
- A Comparative Study On Customer Lotalty in Retail Business (Big Bazaar & Reliance RetailDocument8 pagesA Comparative Study On Customer Lotalty in Retail Business (Big Bazaar & Reliance RetailAndy PndyNo ratings yet
- Introduction To Business Statistics Through R Software: SoftwareFrom EverandIntroduction To Business Statistics Through R Software: SoftwareNo ratings yet
- Resume Mudassar - KhattabDocument2 pagesResume Mudassar - KhattabMudassar KhattabNo ratings yet
- Grade: 4.2 Knowledge of StatisticsDocument9 pagesGrade: 4.2 Knowledge of StatisticsAshley Lamor Kanaku NishimuraNo ratings yet
- The Manager Human Resources DepartmentDocument5 pagesThe Manager Human Resources DepartmentMuzaffar KhanNo ratings yet
- Marketing Research Project On Consumer Behaviour Towards Reebok FootewarDocument20 pagesMarketing Research Project On Consumer Behaviour Towards Reebok Footewarjagdish002No ratings yet
- Tushar CaseDocument3 pagesTushar Caseshreekumar_scdlNo ratings yet
- Paper MB0040 Full AssignmentDocument9 pagesPaper MB0040 Full AssignmentHiren RaichadaNo ratings yet
- Dimensional Analysis: Prithwis Mukerjee, PH.DDocument48 pagesDimensional Analysis: Prithwis Mukerjee, PH.DSurya TejNo ratings yet
- Half Yearly As Practicals QpaperDocument4 pagesHalf Yearly As Practicals QpaperRajarathinam GopalakrishnanNo ratings yet
- ResDocument5 pagesResKavyaNo ratings yet
- Assignment: International MarketingDocument26 pagesAssignment: International MarketingPrince DiuNo ratings yet
- Assessor Feedback: 1. Assignment Criteria:: Student Name: ID Number: 1Document13 pagesAssessor Feedback: 1. Assignment Criteria:: Student Name: ID Number: 1amna_jahangir_1No ratings yet
- Stats Project Bringing It All Together!Document4 pagesStats Project Bringing It All Together!Renee Edwards McKnightNo ratings yet
- A3 Problem Solving TemplateDocument4 pagesA3 Problem Solving TemplateSabina Teodora SavaNo ratings yet
- Introduction To Statistics - LibreOfficeDocument60 pagesIntroduction To Statistics - LibreOfficeMihai VasileNo ratings yet
- Plight of Luxury Brands in IndiaDocument74 pagesPlight of Luxury Brands in IndiaGreeshmaNo ratings yet
- ValuEngine Weekly Newsletter August 22, 2014Document11 pagesValuEngine Weekly Newsletter August 22, 2014ValuEngine.comNo ratings yet
- Plantilla Entre 2 1 1Document7 pagesPlantilla Entre 2 1 1api-250218458No ratings yet
- SUB: Request For The Suitable PostDocument5 pagesSUB: Request For The Suitable Postmannusingh1953No ratings yet
- 2008 OM2 Slot6 EndTermDocument4 pages2008 OM2 Slot6 EndTermalbiesriramNo ratings yet
- Sample Contents of A Completed Feasibility StudyDocument4 pagesSample Contents of A Completed Feasibility StudyVillanueva GailNo ratings yet
- ControlsDocument33 pagesControlsmaneeshkNo ratings yet
- Front Age of Pashupati PaintsDocument6 pagesFront Age of Pashupati PaintsPrtyk AgrawalNo ratings yet
- Ap Micro Problem Set 2Document2 pagesAp Micro Problem Set 2api-244986640No ratings yet
- JspaldingresumeDocument3 pagesJspaldingresumeapi-220272917No ratings yet
- Lab 3 StudentDocument18 pagesLab 3 Studentapi-238878100100% (5)
- MGAC70 Course Outline Fall 2013Document8 pagesMGAC70 Course Outline Fall 2013Hassan ShahNo ratings yet
- Full Feasibility AnalysisDocument12 pagesFull Feasibility Analysisbrojas35No ratings yet
- Ass 1 AnsDocument2 pagesAss 1 AnsImran KhanNo ratings yet
- A Quick and Easy Guide in Using SPSS for Linear Regression AnalysisFrom EverandA Quick and Easy Guide in Using SPSS for Linear Regression AnalysisNo ratings yet
- Course SyllabusDocument9 pagesCourse SyllabusuopfinancestudentNo ratings yet
- Categorical Data Analysis-Tabular and GraphicalDocument16 pagesCategorical Data Analysis-Tabular and GraphicalSaurabh ShirodkarNo ratings yet
- MKTG 490 Fall 07 Exam PoolDocument415 pagesMKTG 490 Fall 07 Exam PoolnimamagebaNo ratings yet
- CMLD - Master Planning of Resources: ImportantDocument3 pagesCMLD - Master Planning of Resources: ImportantMohit NigamNo ratings yet
- Lab 2 WorksheetDocument3 pagesLab 2 WorksheetPohuyistNo ratings yet
- How To Read and Interpret Confusion MatrixDocument1 pageHow To Read and Interpret Confusion Matrixincognito123123No ratings yet
- Career Launcher FinanceDocument177 pagesCareer Launcher Financeincognito1231230% (1)
- CrowdFunding Is Emerging Trends in Real Estate 2015Document112 pagesCrowdFunding Is Emerging Trends in Real Estate 2015CrowdFunding BeatNo ratings yet
- Hansson Private Label - FinalDocument34 pagesHansson Private Label - Finalincognito12312333% (3)
- Hansson Private Label - FinalDocument34 pagesHansson Private Label - Finalincognito12312333% (3)
- Name: Charina Malolot-Villalon Exercise 4: Descriptive Statistics Instruction: Download Population Data at The Barangay Level of Your RespectiveDocument2 pagesName: Charina Malolot-Villalon Exercise 4: Descriptive Statistics Instruction: Download Population Data at The Barangay Level of Your RespectiveChrina MalolotNo ratings yet
- Investigation of Prediction Accuracy, Sensitivity, and Parameter Stability of Large-Scale Propagation Path Loss Models For 5G Wireless CommunicationsDocument19 pagesInvestigation of Prediction Accuracy, Sensitivity, and Parameter Stability of Large-Scale Propagation Path Loss Models For 5G Wireless CommunicationsTommy AsselinNo ratings yet
- Western Mathematics, A Weapon-Bishop A J (Article2)Document16 pagesWestern Mathematics, A Weapon-Bishop A J (Article2)Karigar Medha100% (1)
- Mid Exam 2003Document17 pagesMid Exam 2003DavidNo ratings yet
- Statistical ThermodynamicsDocument8 pagesStatistical ThermodynamicsDora Rabêlo100% (1)
- Updation After ENVI5.0Document36 pagesUpdation After ENVI5.0Vijay KumarNo ratings yet
- FX3 Programming ManualDocument986 pagesFX3 Programming ManualPaulo Alexandra SilvaNo ratings yet
- A Comparative Analysis of Sift Surf Kaze Akaze Orb and BriskDocument10 pagesA Comparative Analysis of Sift Surf Kaze Akaze Orb and Briskminu samantarayNo ratings yet
- Pengembangan Instrumen Tes Untuk Mengukur Kemampuan Berpikir Komputasi SiswaDocument10 pagesPengembangan Instrumen Tes Untuk Mengukur Kemampuan Berpikir Komputasi Siswaaliidrus2602No ratings yet
- Notes For Students Xi (Programming and Computational Thinking) PDFDocument106 pagesNotes For Students Xi (Programming and Computational Thinking) PDFsuryansh tyagi0% (2)
- Congruent Right Triangles: HL, LL, HA, LA: HypotenuseDocument6 pagesCongruent Right Triangles: HL, LL, HA, LA: Hypotenusedarlene bianzonNo ratings yet
- Engineering Mathematics IIDocument102 pagesEngineering Mathematics IIIsaac P PlanNo ratings yet
- Piping & Instrumentation DiagramsDocument19 pagesPiping & Instrumentation Diagramsian ridz100% (1)
- CSEC Maths January2006 Paper 2Document13 pagesCSEC Maths January2006 Paper 2Jason Bosland100% (1)
- Eda Module 3 AnsDocument11 pagesEda Module 3 AnsNiño AntoninoNo ratings yet
- Basic Calculus: Course Outcome 1Document24 pagesBasic Calculus: Course Outcome 1uphold88No ratings yet
- Source Code 1Document40 pagesSource Code 1dinesh181899No ratings yet
- MathematicsDocument10 pagesMathematicsKerby MendozaNo ratings yet
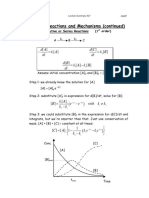
- Consecutive, Series, and Reversible ReactionsDocument6 pagesConsecutive, Series, and Reversible ReactionsRojo JohnNo ratings yet
- F F R V 0 (2.1) : A) Ideal CSTRDocument12 pagesF F R V 0 (2.1) : A) Ideal CSTRCamiloZapataNo ratings yet
- Area of A Parallelogram NotesDocument8 pagesArea of A Parallelogram NotesvenkatNo ratings yet
- Mathematics 2023 (65-4-2) Set-2Document49 pagesMathematics 2023 (65-4-2) Set-2prajjwalroyroyNo ratings yet
- Lesson Plan NBA-Operations ResearchDocument19 pagesLesson Plan NBA-Operations ResearchsunilmeNo ratings yet
- OOSD IIT Kharagpur Mid Sem-12 Question PaperDocument3 pagesOOSD IIT Kharagpur Mid Sem-12 Question PaperBandi SumanthNo ratings yet
- Assessed3 PDFDocument2 pagesAssessed3 PDFDanielaNo ratings yet
- Course Outline Number TheoryDocument2 pagesCourse Outline Number TheoryEly Balaquiao IVNo ratings yet
- امتحان على اول 3 وحدات للصف الأول الإعدادى الترم الاول 2022 مستر محمد عمارة موقع دروس تعليمية اون لاينDocument2 pagesامتحان على اول 3 وحدات للصف الأول الإعدادى الترم الاول 2022 مستر محمد عمارة موقع دروس تعليمية اون لاينBasel ElfalahaNo ratings yet
- EEE331 Lecture 1Document66 pagesEEE331 Lecture 1tolugenNo ratings yet
- Laterally Unrestrained BeamsDocument12 pagesLaterally Unrestrained BeamsVikram0% (1)
- Wave Mechanics 8Document9 pagesWave Mechanics 8DeanielNo ratings yet