You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Roberts (2003) Fundamentals of Signals and SystemsDocument60 pagesRoberts (2003) Fundamentals of Signals and Systemsam klmzNo ratings yet
- Refrigeration and Air Conditioning. W. F. Stoecker, J. W. JonesDocument440 pagesRefrigeration and Air Conditioning. W. F. Stoecker, J. W. JonesMarcialRuiz83% (12)
- Lesson Plan in Mathematics IDocument3 pagesLesson Plan in Mathematics IChonnah Manzo64% (14)
- Untitled 1Document3 pagesUntitled 1MarcialRuizNo ratings yet
- Untitled 1Document3 pagesUntitled 1MarcialRuizNo ratings yet
- Advanced Control Systems: NXT ProjectDocument2 pagesAdvanced Control Systems: NXT ProjectMarcialRuizNo ratings yet
- Admm Distr StatsDocument125 pagesAdmm Distr StatsMairton BarrosNo ratings yet
- Problem Set 1Document2 pagesProblem Set 1maims plapNo ratings yet
- Calculus Review: Name: - DateDocument1 pageCalculus Review: Name: - DateMarck Andrew GaleosNo ratings yet
- MATH F112-HandoutDocument2 pagesMATH F112-HandoutsaurabharpitNo ratings yet
- An1 Derivat - Ro BE 2 71 Mathematical AspectsDocument8 pagesAn1 Derivat - Ro BE 2 71 Mathematical Aspectsvlad_ch93No ratings yet
- Multiplicative CalculusDocument13 pagesMultiplicative CalculusJohnbrown1112No ratings yet
- Bio StatisticsDocument73 pagesBio StatisticsShivani RathorNo ratings yet
- Bond Duration WikiDocument9 pagesBond Duration WikihayrenikNo ratings yet
- Lec 7Document23 pagesLec 7Deepak SakkariNo ratings yet
- Che205s17 Reading 01eDocument14 pagesChe205s17 Reading 01eashraf shalghoumNo ratings yet
- Quantum Bouncing Ball PDFDocument2 pagesQuantum Bouncing Ball PDFbillytho1991No ratings yet
- Inverse Z TransformDocument14 pagesInverse Z TransformHemant ModiNo ratings yet
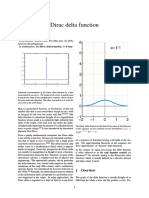
- Delta de Dirac (Propiedades)Document19 pagesDelta de Dirac (Propiedades)Sara DiSuNo ratings yet
- IASSC Green Belt Body of KnowledgeDocument5 pagesIASSC Green Belt Body of KnowledgeBilal Salameh50% (2)
- Written Report of Group 4Document3 pagesWritten Report of Group 4Joshua De Ramos LabandiloNo ratings yet
- Course Outline MLS Analytical Chemistry Laboratory - 110919Document2 pagesCourse Outline MLS Analytical Chemistry Laboratory - 110919Ralph Jan Torres RioNo ratings yet
- Parareal Algorithm: Ma. Cristina BargoDocument43 pagesParareal Algorithm: Ma. Cristina BargoTina BargoNo ratings yet
- MPC 006 PDFDocument55 pagesMPC 006 PDFJyotiNo ratings yet
- Application of Optimization Techniques To Weight Reduction of Automobile BodiesDocument6 pagesApplication of Optimization Techniques To Weight Reduction of Automobile BodiesTibebu MerideNo ratings yet
- SS Notes - VMTWDocument67 pagesSS Notes - VMTWNarendra GaliNo ratings yet
- Medequip ModelDocument4 pagesMedequip Modeldanena88No ratings yet
- Risk and Capital BudgetingDocument12 pagesRisk and Capital BudgetingImraanHossainAyaanNo ratings yet
- Ex 14.1 Domain and Range NotesDocument5 pagesEx 14.1 Domain and Range NotesFA20-BSE-056 (MUHAMMAD TAMOOR HAIDER ISHTIAQ) UnknownNo ratings yet
- Solomon Press C2ADocument18 pagesSolomon Press C2AnmanNo ratings yet
- Answer All Questions in This Section.: X F X FDocument3 pagesAnswer All Questions in This Section.: X F X Fzoe yinzNo ratings yet
- Fixed Point Theory and Applications: Fixed Point Theorems For Weakly C-Contractive Mappings in Partial Metric SpacesDocument18 pagesFixed Point Theory and Applications: Fixed Point Theorems For Weakly C-Contractive Mappings in Partial Metric SpacesAnca Maria AncaNo ratings yet
- Measurement of Central Tendency - Ungrouped Data: Tendency and The Measures of Spread or Variability. 2.12 DefinitionDocument9 pagesMeasurement of Central Tendency - Ungrouped Data: Tendency and The Measures of Spread or Variability. 2.12 DefinitionDaille Wroble GrayNo ratings yet
- One-To-One and Inverse FunctionsDocument18 pagesOne-To-One and Inverse FunctionsJaypee de GuzmanNo ratings yet