You might also like
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- 5606 - 2 - Zoeller 400 Series Owners Manual PDFDocument8 pages5606 - 2 - Zoeller 400 Series Owners Manual PDFbugmenot_testNo ratings yet
- Lecture 14 Heat TransferDocument2 pagesLecture 14 Heat Transferbugmenot_testNo ratings yet
- CPT IOM 20051101 EnglishDocument87 pagesCPT IOM 20051101 EnglishEnoch TwumasiNo ratings yet
- Theoretical Study of An Efficient Bracketing Camera System ArchitectureDocument8 pagesTheoretical Study of An Efficient Bracketing Camera System Architecturebugmenot_testNo ratings yet
- Budget For Building ComputerDocument2 pagesBudget For Building Computerbugmenot_testNo ratings yet
- Workout With CalculationsDocument24 pagesWorkout With Calculationsbugmenot_testNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Mirsab, S Word DoccumentDocument5 pagesMirsab, S Word Doccumentfalcon21152115No ratings yet
- Computer Basics ElementsDocument413 pagesComputer Basics ElementsFaquir Sanoar SanyNo ratings yet
- PageFlip Cicada User GuideDocument29 pagesPageFlip Cicada User GuideDave JohnsonNo ratings yet
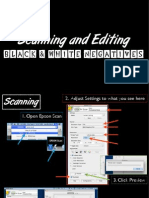
- Scanning and Editing Black and White NegativesDocument17 pagesScanning and Editing Black and White Negativescaro sturgesNo ratings yet
- Service Manual: L200/L201 L100/L101Document47 pagesService Manual: L200/L201 L100/L101Photocopy Sửa Máy PhotocopyNo ratings yet
- Book For Data Entry Operator IISDDocument170 pagesBook For Data Entry Operator IISDShubham DhimaanNo ratings yet
- Troubleshooting Guide imageRUNNER ADVANCE 85006500 Series - en - 26.0 PDFDocument107 pagesTroubleshooting Guide imageRUNNER ADVANCE 85006500 Series - en - 26.0 PDF07overdoNo ratings yet
- Release Notes For Paperport 14: Minimum System RequirementsDocument9 pagesRelease Notes For Paperport 14: Minimum System Requirementsmaria teresa gonzalez hernanadezNo ratings yet
- Application GuideDocument432 pagesApplication GuideYann Christian HIENNo ratings yet
- EKIP Connect - User S Manual - 1SDH000891R0002 - ABB PDFDocument51 pagesEKIP Connect - User S Manual - 1SDH000891R0002 - ABB PDFpevare100% (1)
- VSCL 6 0 6 Unix PGDocument45 pagesVSCL 6 0 6 Unix PGGábor MásikNo ratings yet
- Canon I-Sensys MF231, MF232w, MF237wDocument4 pagesCanon I-Sensys MF231, MF232w, MF237wToma ObretenovNo ratings yet
- GimpUsersManual SecondEdition PDFDocument924 pagesGimpUsersManual SecondEdition PDFc_n_i100% (1)
- Stellar Data Recovery Editions ComparisonDocument2 pagesStellar Data Recovery Editions Comparisonwael haddadNo ratings yet
- Learn Hardware and Software ComponentsDocument11 pagesLearn Hardware and Software ComponentsRizaldo C. LeonardoNo ratings yet
- NT 6 Contrast ScannersDocument2 pagesNT 6 Contrast ScannershiloactiveNo ratings yet
- CyScan Operators GuideDocument45 pagesCyScan Operators GuideDan ZoltnerNo ratings yet
- Ir105 PDFDocument1,029 pagesIr105 PDFpurjanjipurNo ratings yet
- HP Laserjet Pro MFP M521Dn: DatasheetDocument2 pagesHP Laserjet Pro MFP M521Dn: Datasheetoscar Daniel Grajeda cortesNo ratings yet
- Sensing: Encoded Information: Representations: Algorithms:: Machine Vision Computer VisionDocument20 pagesSensing: Encoded Information: Representations: Algorithms:: Machine Vision Computer VisionfrrreshNo ratings yet
- Epson InkTankSystemPrinter M100 M200 June2019Document4 pagesEpson InkTankSystemPrinter M100 M200 June2019Bryan SolutaNo ratings yet
- Accura 102Document8 pagesAccura 102Representaciones y Distribuciones FAL100% (1)
- Standard Operation Procedure For VISION ESR AnalyzerDocument16 pagesStandard Operation Procedure For VISION ESR AnalyzerStephano PalmaNo ratings yet
- BCST-50 User Guide for Barcode ScannerDocument76 pagesBCST-50 User Guide for Barcode ScannerBruno MagneNo ratings yet
- Kodak Portra Data SheetDocument6 pagesKodak Portra Data SheetNate CochraneNo ratings yet
- Kyosera ECOSYS M5521cdwDocument2 pagesKyosera ECOSYS M5521cdwNicolae MariaNo ratings yet
- Tatmeen Training Manual For Master Data - v1.0Document42 pagesTatmeen Training Manual For Master Data - v1.0Jaweed SheikhNo ratings yet
- CMM Inspection FundamentalsDocument60 pagesCMM Inspection FundamentalsChandana DeepthiNo ratings yet
- Machine Vision Technology Take-Up in Industrial ApplicationsDocument7 pagesMachine Vision Technology Take-Up in Industrial ApplicationsMekaTronNo ratings yet