You might also like
- Understanding Oracle Explain PlanDocument30 pagesUnderstanding Oracle Explain Planjenasatyabrata825999No ratings yet
- TWP Parallel Execution Fundamentals 133639Document29 pagesTWP Parallel Execution Fundamentals 133639yogeeswarNo ratings yet
- Oracle Revenue Management Cloud: Seamless and Comprehensive Business SolutionDocument6 pagesOracle Revenue Management Cloud: Seamless and Comprehensive Business SolutionVenkatesh GurusamyNo ratings yet
- Trading 101 BasicsDocument3 pagesTrading 101 BasicsNaveen KumarNo ratings yet
- Oaf Personalization SDocument99 pagesOaf Personalization Sumar7318No ratings yet
- Steps Involved in Oracle Apps Forms PersonalizationDocument74 pagesSteps Involved in Oracle Apps Forms Personalizationsupernova13No ratings yet
- Applies To:: Cannot Replace Record Group With Form Personalization (Doc ID 763410.1)Document2 pagesApplies To:: Cannot Replace Record Group With Form Personalization (Doc ID 763410.1)Venkatesh GurusamyNo ratings yet
- SQL Statement HintsDocument6 pagesSQL Statement HintsVenkatesh GurusamyNo ratings yet
- Understanding MutualFundsDocument12 pagesUnderstanding MutualFundsVenkatesh GurusamyNo ratings yet
- Oracle Index InternalsDocument83 pagesOracle Index InternalsSanthosh ThatojuNo ratings yet
- Steven Feuerstein Best Practice PLSQLDocument106 pagesSteven Feuerstein Best Practice PLSQLreuveng100% (1)
- Understanding MutualFundsDocument12 pagesUnderstanding MutualFundsVenkatesh GurusamyNo ratings yet
- Oracle CollectionsDocument20 pagesOracle CollectionsVenkatesh Gurusamy100% (1)
- Tuning A New QueryDocument4 pagesTuning A New QueryVenkatesh GurusamyNo ratings yet
- Oracle Apps Technical ManualDocument81 pagesOracle Apps Technical ManualPJ190289% (9)
- Oracle RDBMS & SQL Tutorial (Very Good)Document66 pagesOracle RDBMS & SQL Tutorial (Very Good)api-3717772100% (7)
- How To Identify Winning Mutual Funds (Safal Niveshak)Document20 pagesHow To Identify Winning Mutual Funds (Safal Niveshak)Vishal Safal Niveshak KhandelwalNo ratings yet
- Learn Oracle SQL FundamentalsDocument43 pagesLearn Oracle SQL FundamentalsknsanjiNo ratings yet
- Exception Handling Exception Handling Exception Handling Exception HandlingDocument13 pagesException Handling Exception Handling Exception Handling Exception HandlingshailuramNo ratings yet
- How To Create Custom Concurrent RequestsDocument12 pagesHow To Create Custom Concurrent Requestskilarihari100% (1)
- Oracle Interview QuestionsDocument24 pagesOracle Interview QuestionsVenkatesh GurusamyNo ratings yet
- Best Practices For SQL in PLSQLDocument31 pagesBest Practices For SQL in PLSQLSriharsha MajjigaNo ratings yet
- SQL Performance TuningDocument10 pagesSQL Performance TuningVenkatesh Gurusamy100% (1)
- Oracle CollectionsDocument20 pagesOracle CollectionsVenkatesh Gurusamy100% (1)
- Oracle Index InternalsDocument83 pagesOracle Index InternalsSanthosh ThatojuNo ratings yet
- Accounting RulesDocument12 pagesAccounting RulesVenkatesh GurusamyNo ratings yet
- How To Identify Winning Mutual Funds (Safal Niveshak)Document20 pagesHow To Identify Winning Mutual Funds (Safal Niveshak)Vishal Safal Niveshak KhandelwalNo ratings yet
- SQL Performance TuningDocument10 pagesSQL Performance TuningVenkatesh Gurusamy100% (1)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5784)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Chapter 1Document10 pagesChapter 1Misganaw YeshiwasNo ratings yet
- 2 Quarter Pacing Guide 2012-2013Document4 pages2 Quarter Pacing Guide 2012-2013api-31926103No ratings yet
- AC Winding Analysis Using Winding Function ApproachDocument21 pagesAC Winding Analysis Using Winding Function ApproachPriteem BeheraNo ratings yet
- Ms Word Practical Assignment PDFDocument52 pagesMs Word Practical Assignment PDFgithuikoechNo ratings yet
- Alpha Beta Pruning Lecture-23: Hema KashyapDocument42 pagesAlpha Beta Pruning Lecture-23: Hema KashyapAKSHITA MISHRANo ratings yet
- MiniTest 230304Document2 pagesMiniTest 230304Osama MaherNo ratings yet
- Syl&Scheme 1 Styear 2018Document31 pagesSyl&Scheme 1 Styear 2018Aryan GuptaNo ratings yet
- RP Lecture8Document18 pagesRP Lecture8stipe1pNo ratings yet
- Exercise Paper On Photoelectric EffectDocument4 pagesExercise Paper On Photoelectric EffectJohn Lorenzo100% (1)
- Motion Class 9 NotesDocument15 pagesMotion Class 9 NotesBavan Deep100% (1)
- Tutorial Fourier Series and TransformDocument5 pagesTutorial Fourier Series and TransformRatish DhimanNo ratings yet
- ApplicationsOfMatrixMathematics Dr.M.aparnaDocument4 pagesApplicationsOfMatrixMathematics Dr.M.aparnaAmrit DangiNo ratings yet
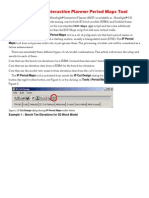
- MSIP Period Maps Tool 200901Document8 pagesMSIP Period Maps Tool 200901Kenny CasillaNo ratings yet
- An Aggregatedisaggregate Intermittent Demand Approach Adida To ForecastingDocument11 pagesAn Aggregatedisaggregate Intermittent Demand Approach Adida To ForecastingPablo RiveraNo ratings yet
- Latitude and Longitude BasicDocument14 pagesLatitude and Longitude Basicapi-235000986100% (3)
- Machine Learning: An Introduction to Predicting the Future from Past ExperienceDocument65 pagesMachine Learning: An Introduction to Predicting the Future from Past ExperienceAnilNo ratings yet
- ISI Exam Sample PaperDocument5 pagesISI Exam Sample PaperQarliddh0% (1)
- Exercises in Nonlinear Control SystemsDocument115 pagesExercises in Nonlinear Control SystemsAshk Nori ZadehNo ratings yet
- Section 8.2: Monte Carlo Estimation: Discrete-Event Simulation: A First CourseDocument19 pagesSection 8.2: Monte Carlo Estimation: Discrete-Event Simulation: A First CoursessfofoNo ratings yet
- CH 2Document16 pagesCH 2Nazia EnayetNo ratings yet
- Cbot-Unit 1-LPPDocument23 pagesCbot-Unit 1-LPPJaya SuryaNo ratings yet
- B.tech Syllabus 3rd Semester For CSE IPUDocument8 pagesB.tech Syllabus 3rd Semester For CSE IPUykr007No ratings yet
- DesmosDocument14 pagesDesmosapi-433553650No ratings yet
- Forecasting Exercises ProblemDocument4 pagesForecasting Exercises ProblemBasha World100% (2)
- I.Condition For The Equilibrium of A Particle: Stiffness KDocument5 pagesI.Condition For The Equilibrium of A Particle: Stiffness KJirah LacbayNo ratings yet
- Homework Solutions - X - MOP (Blue-Black) 2012Document5 pagesHomework Solutions - X - MOP (Blue-Black) 2012Ayush AryanNo ratings yet
- Components For Pneumatic Automation: Five ONEDocument26 pagesComponents For Pneumatic Automation: Five ONEamNo ratings yet
- Chapter 3: Structures: TrussesDocument19 pagesChapter 3: Structures: TrussesBadar Sharif100% (1)
- TrusssDocument11 pagesTrusssfaizy216No ratings yet
- JavaScript: The Programming Language of the WebDocument15 pagesJavaScript: The Programming Language of the WebMary EcargNo ratings yet