You might also like
- Healthcare Information System A Complete Guide - 2020 EditionFrom EverandHealthcare Information System A Complete Guide - 2020 EditionNo ratings yet
- CDISCDocument28 pagesCDISCNaresh Kumar RapoluNo ratings yet
- MappingDocument34 pagesMappingboggalaNo ratings yet
- Sas Clinical Data Integration Fact SheetDocument4 pagesSas Clinical Data Integration Fact SheetChandrasekhar KothamasuNo ratings yet
- ADaM IG V1.1draftDocument92 pagesADaM IG V1.1draftRajashekar GatlaNo ratings yet
- D7.2 Data Managment Plan v1.04Document14 pagesD7.2 Data Managment Plan v1.04gkoutNo ratings yet
- David W. Mailhot February 7, 2006Document33 pagesDavid W. Mailhot February 7, 2006upendernNo ratings yet
- Validating The SDTM Dataset PDFDocument12 pagesValidating The SDTM Dataset PDFBhore SayaliNo ratings yet
- Master Patient IndexDocument6 pagesMaster Patient IndexAhmed YousefNo ratings yet
- SAS Clinical Course OutlineDocument6 pagesSAS Clinical Course OutlineNagesh KhandareNo ratings yet
- Adam PDFDocument51 pagesAdam PDFNagarjuna PNo ratings yet
- Implementation of ETL Tool For Data Warehousing For Non-Hodgkin Lymphoma (NHL) Cancer in Public Sector, PakistanDocument5 pagesImplementation of ETL Tool For Data Warehousing For Non-Hodgkin Lymphoma (NHL) Cancer in Public Sector, PakistanWARSE JournalsNo ratings yet
- MYCINDocument5 pagesMYCINsaurabh3112vermaNo ratings yet
- Managing Data Integrity As Part of Master Data Management: Katri VihavainenDocument60 pagesManaging Data Integrity As Part of Master Data Management: Katri VihavainenAntonio FrianNo ratings yet
- HL7 Integration Analyst in Nashville TN Resume Éilís CreanDocument6 pagesHL7 Integration Analyst in Nashville TN Resume Éilís CreanEilisCreanNo ratings yet
- SAS Projects DiscriptionDocument2 pagesSAS Projects DiscriptionRavi Prakash MayreddyNo ratings yet
- SDTM and AdamDocument8 pagesSDTM and Adamjpavan100% (1)
- CDM Best PracticeDocument34 pagesCDM Best PracticeAlexandra SacheNo ratings yet
- Decentralizing Clinical Trials: A New Quality-by-Design, Risk-Based FrameworkDocument14 pagesDecentralizing Clinical Trials: A New Quality-by-Design, Risk-Based Frameworknate zhangNo ratings yet
- SAS Cluster Project ReportDocument24 pagesSAS Cluster Project ReportBiazi100% (1)
- The "Epic" Challenge of Optimizing Antimicrobial Stewardship: The Role of Electronic Medical Records and TechnologyDocument9 pagesThe "Epic" Challenge of Optimizing Antimicrobial Stewardship: The Role of Electronic Medical Records and TechnologyMr XNo ratings yet
- Clinical Data ManagementDocument5 pagesClinical Data ManagementKen KhumanchaNo ratings yet
- Base Sas Advance SAS Interview Questions by Keli TechnologiesDocument12 pagesBase Sas Advance SAS Interview Questions by Keli TechnologiesnageshNo ratings yet
- C Disc ExpressDocument31 pagesC Disc ExpressupendernathiNo ratings yet
- ADAM Trace BilityDocument18 pagesADAM Trace BilityABHIJIT SheteNo ratings yet
- SDTM-ADaM Pilot Project PDFDocument63 pagesSDTM-ADaM Pilot Project PDFbrajani28No ratings yet
- 3604sas Base & Advanced Course ContentDocument14 pages3604sas Base & Advanced Course Contentクマー ヴィーンNo ratings yet
- Data Testing White PaperDocument15 pagesData Testing White PaperShiva Krishna BeraNo ratings yet
- A Study of Advanced Hospital Managaement System: Kumaran S, DR Pusphagaran, Kalai Selvi, Christopher, DeepakDocument8 pagesA Study of Advanced Hospital Managaement System: Kumaran S, DR Pusphagaran, Kalai Selvi, Christopher, Deepakrohising2045No ratings yet
- CRF Design Template v4.0Document28 pagesCRF Design Template v4.0Shalini ShivenNo ratings yet
- SCDM CourseDocument6 pagesSCDM Coursedhaval-shah-6890100% (1)
- The Essential PROC SQLDocument10 pagesThe Essential PROC SQLdevidasckulkarniNo ratings yet
- Cdiscsdtmtrainingpresentation 12900042423172 Phpapp01Document26 pagesCdiscsdtmtrainingpresentation 12900042423172 Phpapp01geekindiaNo ratings yet
- HL7 DiagramDocument2 pagesHL7 DiagramChris GarsonNo ratings yet
- Allscripts Common Interface Engine Presentation For Allscripts West Regional User Group Winter MeetingDocument24 pagesAllscripts Common Interface Engine Presentation For Allscripts West Regional User Group Winter MeetingJC CampbellNo ratings yet
- SAS Programmer ResumeDocument4 pagesSAS Programmer ResumerelicysynopNo ratings yet
- Cdisc SyllabusDocument2 pagesCdisc SyllabusAbhinav TangellaNo ratings yet
- Tableau For Healthcare Webinar Mass General Presentation Final 04-25-17Document34 pagesTableau For Healthcare Webinar Mass General Presentation Final 04-25-17jayNo ratings yet
- Adam Ae Final v1Document51 pagesAdam Ae Final v1imk_mithunNo ratings yet
- Bundle Three Hour SSC PDFDocument14 pagesBundle Three Hour SSC PDFRodrigo RochaNo ratings yet
- Phuse: 10-12 September 2005 Heidelberg, GermanyDocument41 pagesPhuse: 10-12 September 2005 Heidelberg, GermanySandeep KumarNo ratings yet
- Design and Development of Online Hospital Management Information SystemDocument10 pagesDesign and Development of Online Hospital Management Information SystemRula ShakrahNo ratings yet
- ADT DFT ORU: The Most Commonly Used HL7 Message Types IncludeDocument1 pageADT DFT ORU: The Most Commonly Used HL7 Message Types IncludeRafi Uddin ShaikNo ratings yet
- Sas fAQ'S 1Document114 pagesSas fAQ'S 1meenaNo ratings yet
- The 5 Most Important Clinical SAS Programming Validation StepDocument6 pagesThe 5 Most Important Clinical SAS Programming Validation Steppalani.ramjiNo ratings yet
- An Automated Medical Duties Scheduling System Using Queing Techniques (Chapter 1-5)Document19 pagesAn Automated Medical Duties Scheduling System Using Queing Techniques (Chapter 1-5)ABUBSAKAR SIDIQ AMINUNo ratings yet
- Indexing in DBMS - Ordered Indices - Primary Index - Dense Index - Sparse Index - Secondary Index - Multilevel Indices - Clustering Index in DatabaseDocument7 pagesIndexing in DBMS - Ordered Indices - Primary Index - Dense Index - Sparse Index - Secondary Index - Multilevel Indices - Clustering Index in Databasekaramthota bhaskar naikNo ratings yet
- Template For Gap AnalysisDocument14 pagesTemplate For Gap AnalysisSajeel ZamanNo ratings yet
- Creation of SDTM Annotated CRFsDocument25 pagesCreation of SDTM Annotated CRFssangameswararao kusumanchiNo ratings yet
- Data Quality Management ModelDocument11 pagesData Quality Management ModelHanum PutericNo ratings yet
- Accenture Connected Health Global Report Final WebDocument280 pagesAccenture Connected Health Global Report Final Webkon-baNo ratings yet
- Bi TestingDocument11 pagesBi TestingwaseemqaNo ratings yet
- Clinical SAS TermsDocument12 pagesClinical SAS TermsRachapudi SumanNo ratings yet
- Create First Data WareHouse - CodeProjectDocument10 pagesCreate First Data WareHouse - CodeProjectchinne046No ratings yet
- SSIS Operational and Tuning GuideDocument50 pagesSSIS Operational and Tuning GuideEnguerran DELAHAIENo ratings yet
- Data Governance and Data Management: Contextualizing Data Governance Drivers, Technologies, and ToolsFrom EverandData Governance and Data Management: Contextualizing Data Governance Drivers, Technologies, and ToolsNo ratings yet
- Data Warehousing Fundamentals for IT ProfessionalsFrom EverandData Warehousing Fundamentals for IT ProfessionalsRating: 3 out of 5 stars3/5 (1)
- SAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Oracle AIM MethodologyDocument2 pagesOracle AIM Methodologychan-No ratings yet
- Siebel Web Service ReferenceDocument146 pagesSiebel Web Service ReferenceDharma SasthaNo ratings yet
- Aggregator TransformationDocument18 pagesAggregator Transformationchan-No ratings yet
- Siebel Performance Tuning GuideDocument254 pagesSiebel Performance Tuning GuiderodrigofdiasNo ratings yet
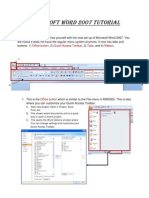
- Microsoft Word 2007 Tutorial: Office Button Quick Access Toolbar Tabs RibbonDocument5 pagesMicrosoft Word 2007 Tutorial: Office Button Quick Access Toolbar Tabs Ribbonchan-No ratings yet
- Scripting For Siebel 7Document114 pagesScripting For Siebel 7chan-100% (1)
- EIM ScenariosDocument19 pagesEIM Scenarioschan-No ratings yet
- Irm PDFDocument27 pagesIrm PDFerraticNo ratings yet
- BST PDFDocument392 pagesBST PDFTushar KhattarNo ratings yet
- fli6 O JLDF +:yfg, /fdzfxky, Sf7Df8F) + Kf7/Oqmd: # K - Yd / L4Tlo KQSF) LNLVT K/Liff 5' F5' ) X'G) 5Document5 pagesfli6 O JLDF +:yfg, /fdzfxky, Sf7Df8F) + Kf7/Oqmd: # K - Yd / L4Tlo KQSF) LNLVT K/Liff 5' F5' ) X'G) 5Nihit Prakash KandelNo ratings yet
- Determining System Requirements: Multiple Choice QuestionsDocument9 pagesDetermining System Requirements: Multiple Choice QuestionsbigolNo ratings yet
- Cost & MGT Accounting - Lecture Note - Ch. 3 & 4Document28 pagesCost & MGT Accounting - Lecture Note - Ch. 3 & 4Ashe BalchaNo ratings yet
- Introduction To Electronic Commerce: E-Commerce: The Second Wave Fifth Annual EditionDocument43 pagesIntroduction To Electronic Commerce: E-Commerce: The Second Wave Fifth Annual EditionMohamed Makeen Waseer MohamedNo ratings yet
- BIM in Conflict ManagementDocument18 pagesBIM in Conflict ManagementSona NingNo ratings yet
- Baldwin Bicycle Company Case Analysis - GRP 2 - FinalDocument11 pagesBaldwin Bicycle Company Case Analysis - GRP 2 - FinalPatricia Bianca ArceoNo ratings yet
- Introduction To ManagementDocument23 pagesIntroduction To ManagementKiran ZamanNo ratings yet
- 2 SPP Document 201Document6 pages2 SPP Document 201Ian Gonzalez PascuaNo ratings yet
- Auditing 1 Final Chapter 10Document7 pagesAuditing 1 Final Chapter 10PaupauNo ratings yet
- Introduction To Human Resource Management: Objectives of HRM Functions of HRMDocument19 pagesIntroduction To Human Resource Management: Objectives of HRM Functions of HRMNusrat Jahan NafisaNo ratings yet
- Suhas Kumar Shetty Mar SimulationDocument2 pagesSuhas Kumar Shetty Mar SimulationRahul SharmaNo ratings yet
- Answer Aud339 June2019 - Mac2017Document26 pagesAnswer Aud339 June2019 - Mac2017Khairunisak NazriNo ratings yet
- Ibstpi-Idsurvey2015 WilliamsDocument7 pagesIbstpi-Idsurvey2015 Williamsapi-333100125No ratings yet
- It Audit ReportDocument2 pagesIt Audit Reportathabascans0% (1)
- Short Notes Mgmt627Document22 pagesShort Notes Mgmt627Sadia HanifNo ratings yet
- Dex Core (Strategic Management)Document11 pagesDex Core (Strategic Management)JessicaNo ratings yet
- FactSheet HDIPSD2 HB V.2 2019 05092018Document25 pagesFactSheet HDIPSD2 HB V.2 2019 05092018Shan ParkerNo ratings yet
- Substantive Tests of Inventory and Cost of Goods SoldDocument9 pagesSubstantive Tests of Inventory and Cost of Goods SoldMa Tiffany Gura RobleNo ratings yet
- Introduction To: - Pinkal Deore 20190301007Document6 pagesIntroduction To: - Pinkal Deore 20190301007Pinkal DeoreNo ratings yet
- Fundamentals of Human Resource Management 7th Edition by Noe Hollenbeck Gerhart and Wright ISBN Solution ManualDocument13 pagesFundamentals of Human Resource Management 7th Edition by Noe Hollenbeck Gerhart and Wright ISBN Solution Manualhiedi100% (22)
- Meezan Bank Limited SWOT Analysis OverviewDocument3 pagesMeezan Bank Limited SWOT Analysis Overviewakbar100% (1)
- Assessment of HRM Function in Bank of Kathmandu: Prepared By: (GROUP 5) Anish, Luna, Nirjal, Rakesh, Sujesh, UmeshDocument39 pagesAssessment of HRM Function in Bank of Kathmandu: Prepared By: (GROUP 5) Anish, Luna, Nirjal, Rakesh, Sujesh, Umeshnischal1100% (1)
- Channel ManagementDocument7 pagesChannel ManagementViplav NigamNo ratings yet
- Auditor Acceptance - Appointment LetterDocument2 pagesAuditor Acceptance - Appointment LetterPatra & AssociatesNo ratings yet
- COST - VOLUME-PROFIT AnalysisDocument17 pagesCOST - VOLUME-PROFIT Analysisasa ravenNo ratings yet
- A Guide To Green PurchasingDocument108 pagesA Guide To Green PurchasingTony BakerNo ratings yet
- SPC261 - Practical Approach To SharePoint Governance - The Key To Successful SharePoint 2010 SolutionsDocument35 pagesSPC261 - Practical Approach To SharePoint Governance - The Key To Successful SharePoint 2010 SolutionsBob the BuilderNo ratings yet
- JD - Infra Project Manager (PMPM10)Document3 pagesJD - Infra Project Manager (PMPM10)rainmanlinuxNo ratings yet