You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Sop AutoclavingDocument4 pagesSop AutoclavingXiang LiuNo ratings yet
- Financial Management 2E: Rajiv Srivastava - Dr. Anil Misra Solutions To Numerical ProblemsDocument5 pagesFinancial Management 2E: Rajiv Srivastava - Dr. Anil Misra Solutions To Numerical ProblemsParesh ShahNo ratings yet
- FDA Guidance - Mobile Medical Applications - Sept 25, 2013Document43 pagesFDA Guidance - Mobile Medical Applications - Sept 25, 2013Xiang LiuNo ratings yet
- Connector Design - Materials and Connector ReliabilityDocument16 pagesConnector Design - Materials and Connector ReliabilityXiang Liu100% (1)
- EMC TrendsDocument55 pagesEMC TrendsXiang LiuNo ratings yet
- Review of The New Y14 5 2009 StandardDocument16 pagesReview of The New Y14 5 2009 StandardPhillip GrimNo ratings yet
- Sterile Product Package Integrity TestingDocument104 pagesSterile Product Package Integrity TestingJihad Elias ChahlaNo ratings yet
- A Root Cause Analysis Method For Industrial Plant - Reliability Improvement and Engineering Design FeedbackDocument6 pagesA Root Cause Analysis Method For Industrial Plant - Reliability Improvement and Engineering Design FeedbackXiang LiuNo ratings yet
- Systems Engineering (SE) & Project Management: Nick Clemens, PMPDocument37 pagesSystems Engineering (SE) & Project Management: Nick Clemens, PMPcasakaNo ratings yet
- Test Method Validation Case StudyDocument2 pagesTest Method Validation Case StudyXiang LiuNo ratings yet
- 13F Internal Audit ChecklistDocument5 pages13F Internal Audit ChecklistXiang Liu0% (1)
- Intertek RoHS 2 Services BrochureDocument2 pagesIntertek RoHS 2 Services BrochureXiang LiuNo ratings yet
- ASQ Certification Program Gain Wider RecognitionDocument13 pagesASQ Certification Program Gain Wider RecognitionXiang LiuNo ratings yet
- Certification Exam - Tips, Trips and TrapsDocument7 pagesCertification Exam - Tips, Trips and TrapsXiang LiuNo ratings yet
- 6 1standard WorkDocument15 pages6 1standard WorkXiang Liu100% (1)
- Practical Guide To ISO 9001 ImplementationDocument20 pagesPractical Guide To ISO 9001 ImplementationXiang LiuNo ratings yet
- C /C Q C P ™: Assessor Checklist: General Criteria (Iso/Iec 17025)Document26 pagesC /C Q C P ™: Assessor Checklist: General Criteria (Iso/Iec 17025)Xiang LiuNo ratings yet
- Advertising II Marathi VersionDocument91 pagesAdvertising II Marathi VersionHarsh Sangani100% (1)
- EVOM ManualDocument2 pagesEVOM ManualHouston WhiteNo ratings yet
- Arduino Uno CNC ShieldDocument11 pagesArduino Uno CNC ShieldMărian IoanNo ratings yet
- Ajmera - Treon - FF - R4 - 13-11-17 FinalDocument45 pagesAjmera - Treon - FF - R4 - 13-11-17 FinalNikita KadamNo ratings yet
- Business-Communication Solved MCQs (Set-3)Document8 pagesBusiness-Communication Solved MCQs (Set-3)Pavan Sai Krishna KottiNo ratings yet
- Product Manual 26086 (Revision E) : EGCP-2 Engine Generator Control PackageDocument152 pagesProduct Manual 26086 (Revision E) : EGCP-2 Engine Generator Control PackageErick KurodaNo ratings yet
- Chemistry Investigatory Project (R)Document23 pagesChemistry Investigatory Project (R)BhagyashreeNo ratings yet
- How To Launch Remix OS For PCDocument2 pagesHow To Launch Remix OS For PCfloapaaNo ratings yet
- The Kicker TranscriptionDocument4 pagesThe Kicker TranscriptionmilesNo ratings yet
- Current Concepts in Elbow Fracture Dislocation: Adam C Watts, Jagwant Singh, Michael Elvey and Zaid HamoodiDocument8 pagesCurrent Concepts in Elbow Fracture Dislocation: Adam C Watts, Jagwant Singh, Michael Elvey and Zaid HamoodiJoão Artur BonadimanNo ratings yet
- HRMDocument118 pagesHRMKarthic KasiliaNo ratings yet
- Steel Design Fourth Edition William T Segui Solution Manual 1Document11 pagesSteel Design Fourth Edition William T Segui Solution Manual 1RazaNo ratings yet
- Iaea Tecdoc 1092Document287 pagesIaea Tecdoc 1092Andres AracenaNo ratings yet
- Dreaded Attack - Voyages Community Map Rules v1Document2 pagesDreaded Attack - Voyages Community Map Rules v1jNo ratings yet
- Prospekt Puk U5 en Mail 1185Document8 pagesProspekt Puk U5 en Mail 1185sakthivelNo ratings yet
- Math Review CompilationDocument9 pagesMath Review CompilationJessa Laika CastardoNo ratings yet
- Mathematics Mock Exam 2015Document4 pagesMathematics Mock Exam 2015Ian BautistaNo ratings yet
- BS 7974 2019Document68 pagesBS 7974 2019bcyt00No ratings yet
- Seabank Statement 20220726Document4 pagesSeabank Statement 20220726Alesa WahabappNo ratings yet
- Formula:: High Low Method (High - Low) Break-Even PointDocument24 pagesFormula:: High Low Method (High - Low) Break-Even PointRedgie Mark UrsalNo ratings yet
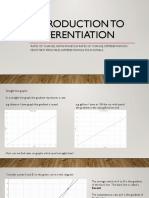
- Introduction To DifferentiationDocument10 pagesIntroduction To DifferentiationaurennosNo ratings yet
- 788 ManualDocument16 pages788 Manualn0rdNo ratings yet
- Shelly e CommerceDocument13 pagesShelly e CommerceVarun_Arya_8382No ratings yet
- Convection Transfer EquationsDocument9 pagesConvection Transfer EquationsA.N.M. Mominul Islam MukutNo ratings yet
- Satish Gujral - FinalDocument23 pagesSatish Gujral - Finalsatya madhuNo ratings yet
- Dwnload Full Beckers World of The Cell 9th Edition Hardin Solutions Manual PDFDocument35 pagesDwnload Full Beckers World of The Cell 9th Edition Hardin Solutions Manual PDFgebbielean1237100% (12)
- Modern School For SaxophoneDocument23 pagesModern School For SaxophoneAllen Demiter65% (23)
- 1995 Biology Paper I Marking SchemeDocument13 pages1995 Biology Paper I Marking Schemetramysss100% (2)
- BLP#1 - Assessment of Community Initiative (3 Files Merged)Document10 pagesBLP#1 - Assessment of Community Initiative (3 Files Merged)John Gladhimer CanlasNo ratings yet